R 实现及相关文本挖掘 English participle

@[TOC](R实现及相关文本挖掘 English participle)
1 案例背景
目前朴素贝叶斯已经成功运用于垃圾邮件的过滤,也可用于垃圾短信的过滤,但是会有额外的挑战
短信文本量减少了
短信口语化:缩写,新兴词汇
数据:网上收集的带有标签的中英文短信数据
英文数据(sms_spam.csv):5559条数据,垃圾短信标记为spam,非垃圾短信标记为ham
文本处理:将数据转化成一种词袋(bag-of-words)的表示方法,忽略词序,只提供简单的变量查看单词是否出现
2 准备数据
英文文本处理中,需要考虑去除数字和标点符号,去除没有意义的单词,将句子分解成单个的单词
中文文本处理中,需要考虑去掉非中文字符或者非中英文字符,利用结巴分词需要用到的包:jiebaR,tm
library(jiebaR,quietly = T)
##read and clean
sms1<-read.csv("sms_spam.csv",encoding = "UTF-8")
View(sms1)
sms1$type<-as.factor(sms1$type)
table(sms1$type)

加载包tm,创建一个语料库(文本文件的集合)
Corpus创建一个语料库存储文本文档,读入的格式是VectorSource函数生成的向量信息
使用inspect查看语料库前三条信息
##clean use tm
install.packages("tm")
install.packages("jiebaR")
install.packages("wordcloud")
library(tm)
smsC<-Corpus(VectorSource(sms1$text))
class(smsC)
# print(smsC)
inspect(smsC[1:10])

tm_map()提供了一种用来转换(处理)语料库的方法,可以使用一系列转换函数(?getTransformations查看)来清理语料库,也可以是自定义函数
# remove characters that not letters
remove_NP<-function(x){
gsub("[^a-zA-Z]"," ",x)
}
corpus1<-tm_map(smsC,function(x)
stripWhitespace(removeWords(tolower(remove_NP(x)),stopwords()))) #stopwords 把停用词去掉(默认英文) stripwhitespeace 去掉多余空格
inspect(corpus1[1:10])
3 建立训练数据和测试数据
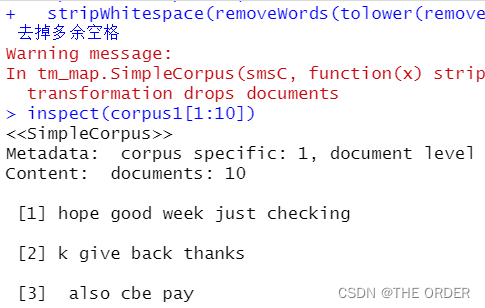
set.seed(21)
index<-sample(1:nrow(sms1),nrow(sms1)*0.75)
sms1_tr<-sms1[index,]
sms1_te<-sms1[-index,]
prop.table(table(sms1_tr$type))
prop.table(table(sms1_te$type))
smscor_tr<-corpus1[index]
smscor_te<-corpus1[-index]
4 生成词云图表
需要用到的包wordcloud,也可以用wordcloud2(如用wordcloud2,一般需要装生成频数的包qdap)
min.freq:单词在语料库中出现的最小次数(一般为文档总数目的10%);random.order指明词云是否以随机的顺序排列;max.words指明最多出现多少单词,scale表示单词的最大和最小字体
##word cloud
library(wordcloud)
pal<-brewer.pal(6,"Dark2")
wordcloud(smscor_tr,min.freq=40,random.order=T,colors=pal)#min.freq最小频率,order排序
indsp<-sms1_tr$type=="spam"
wordcloud(smscor_tr[indsp],max.words=40,random.order=F,scale=c(4,0.5),colors=pal)#max.words词云最多出现多少单词,scale词云大小
wordcloud(smscor_tr[!indsp],max.words=40,random.order=F,scale=c(4,0.5),colors=pal)


5 选取频繁词为特征
创建文档词矩阵(行为文档,列为词,较大的稀疏矩阵):DocumentTermMatrix()
剔除训练数据中出现在少于10封邮件中或少于记录总数的0.1%的所有单词,即找出所有频繁词:findFreqTerms()
按照频繁词重新生成文档词矩阵
稀疏矩阵中的元素表示单词在文档中出现的次数,需要转化成因子变量:出现yes,没出现no
##freq words
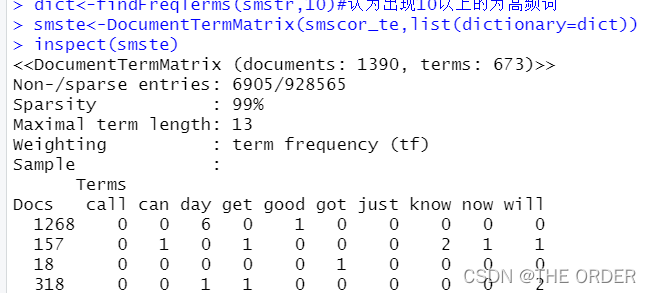
smstr<-DocumentTermMatrix(smscor_tr)#语料库对象生成词文档矩阵
inspect(smstr)
dict<-findFreqTerms(smstr,10)#认为出现10以上的为高频词
smste<-DocumentTermMatrix(smscor_te,list(dictionary=dict))
inspect(smste)
train<-apply(smstr[,dict],2,function(x) ifelse(x,"yes","no"))#把1,0转换为yes,no,这步没什么意义,主要支持naiveBayes函数
test<-apply(smste,2,function(x) ifelse(x,"yes","no"))
6 贝叶斯建模
需要用到的包e1017,gmodels
建模,预测分类,评估
其中的参数:type值为class(预测的类别)和raw(原始的预测概率)
其中的参数:prop.chisq表卡方贡献值,prop.t表示表格占比,dnn表示行列总名称
##model
library(e1071)
library(gmodels)
smsclass<-naiveBayes(train,sms1_tr$type,laplace = 0)#laplace估计
test_pre<-predict(smsclass,test,type="class")
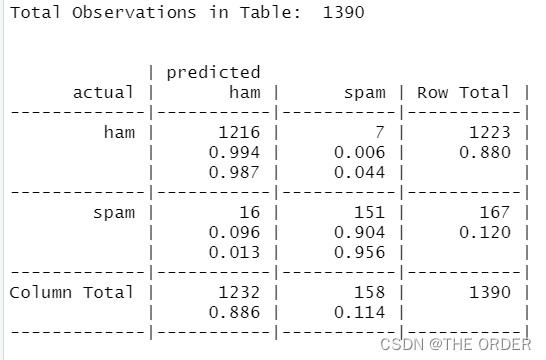
CrossTable(sms1_te$type,test_pre,prop.chisq = F,prop.t=F,dnn=c("actual","predicted"))

- 点赞
- 收藏
- 关注作者
评论(0)