iOS之深入解析CocoaPods的GitLab CI与组件自动化构建与发布

【摘要】
一、Gitlab CI/CD 简介
① GitLab
GitLab 是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的 Git 项目仓库,可通过 Web 界面进行访问公开的或...
一、Gitlab CI/CD 简介
① GitLab
- GitLab 是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的 Git 项目仓库,可通过 Web 界面进行访问公开的或者私有的项目。
- GitLab 拥有与 GitHub 类似的功能,能够浏览源代码,管理缺陷和注释。
- GitLab 可以管理团队对仓库的访问,它非常易于浏览提交过的版本并提供一个文件历史库。
② GitLab CI/CD
- Gitlab CI/CD 是一个内置在 GitLab 中的工具,用于通过持续方法进行软件开发:
-
- 持续集成(Continuous Integration):频繁地(一天多次)将代码集成到主干,让产品可以快速迭代,同时还能保持高质量,它的核心措施是,代码集成到主干之前,必须通过自动化测试;
-
- 持续交付(Continuous Delivery):频繁地将软件的新版本,交付给质量团队或者用户,以供评审,如果评审通过,代码就进入生产阶段,持续交付可以看作持续集成的下一步,它强调的是,不管怎么更新,软件是随时随地可以交付的;
-
- 持续部署(continuous Deployment):代码通过评审以后,自动部署到生产环境,是持续部署是持续交付的下一步,持续部署的目标是,代码在任何时刻都是可部署的,可以进入生产阶段。
③ GitLab Runner
- GitLab Runner 用于执行 Gitlab CI/CD 触发的一系列作业,并将结果发送回 Gitlab。
- GitLab Runner 可以在 Docker 容器内运行或部署到 Kubernetes 集群中。
④ Pipeline
- Pipeline 中文称为流水线,是分阶段执行的构建任务。如:安装依赖、运行测试、打包、部署开发服务器、部署生产服务器等流程,合起来称为 Pipeline。
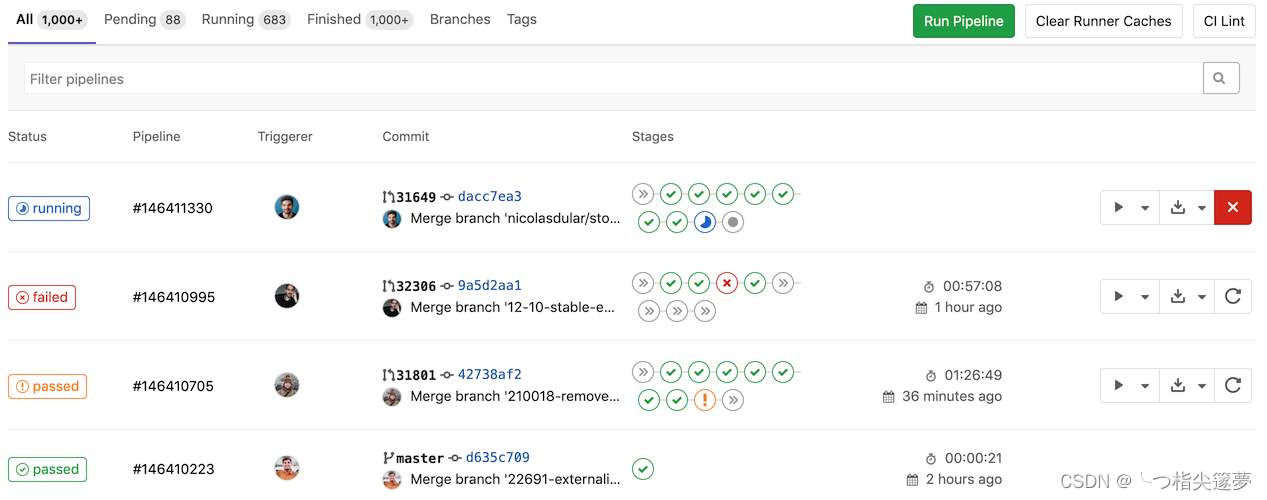
- Stage表示构建阶段,可以理解为上面所说安装依赖、运行测试等环节的流程。我们可以在一次 Pipeline 中定义多个 Stage。
- Job 表示构建的作业(或称之为任务),表示某个 Stage 里面执行的具体任务,可以在 Stages 里面定义多个 Jobs。
- Pipeline,Stage 和 Job 的关系如下所示:
⑤ 整体流程
- CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法,CI/CD 的核心概念是持续集成、持续交付和持续部署。
- 整个流程将分为几个部分:
-
- 首先开发人员在本地完成项目的开发之后,将代码推送到 Gitlab 仓库中;
-
- 当代码提交到 Gitlab 仓库时,会触发 Pipeline,Gitlab Runner 会根据 .gitlab-ci.yml 配置文件运行 Pipeline 中各阶段的任务,总共定义 3 个阶段:compile,build,deploy;
-
- 在 compile 阶段,Gitlab Runner 将项目编译成 jar 包,使用 MinIO 作为缓存,首次编译项目时会从 Maven 官网拉取依赖,之后会将依赖压缩后上传至 MinIo,在下一次编译时就可以直接从 MinIO 下载依赖文件;
-
- 在 build 阶段,Gitlab Runner 使用在 compile 阶段编译生成的 jar 包构建 Docker 镜像,并将镜像推送至镜像仓库;
-
- 在 deploy 阶段,Gitlab Runner 使用构建好 Docker 镜像在 Kubernetes 集群中部署应用。
二、背景分析
- 在实施业务组件化后,大部分没有组件化工具链支撑的团队一般都会遇到组件发布效率问题,如果遇到多个特性一起上线时,发布的组件数量可能达到几十个,手动发布这些组件的话,费时费力,非常影响开发体验。虽然可以通过 CI 简化单个组件的发布,只需要根据 Podfile 中的版本提交相应 tag 即可触发发布动作,但是 CI 并没有解决多个关联组件发布的前后顺序问题。如果下层组件还未发布就发布上层组件,此组件的 CI 很可能会因为缺少下层组件的某些接口而执行失败。
- 基于 GitFlow 工作流进行日常项目的开发,项目在进入预发阶段时,关联的组件都需要拉取 release 分支,当某次发版的所有关联项目都预发测试完毕时,此次发版的负责人(通常是其中某个项目的负责人)会通知团队内部成员对组件进行封板,然后组件的负责人会去合并 release 分支到 master & develop,并且发布一个新版本,等所有组件都发布完成后,发版负责人再去更新主工程 Podfile。
- 整个发版过程,组件负责人除了需要重复若干次以下操作,还需要知悉是否有下层组件还未发布:
>>>> 查看组件应升级版本,更新 podspec 版本并 commit
>>>> 合并 release 分支 ,gitflow finish release
>>>> 打 tag 并 push
>>>> CI 执行完毕,组件发布完成,可能需要通知上层组件的负责人
- 1
- 2
- 3
- 4
- 可以看到如果需要发布多个组件,其过程还是非常繁琐的。再单独说下发布顺序的问题,假设当前有需要发布的组件 A、B、C、D,其依赖关系如下:

- 在遵守 CocoaPods 发布规则的前提下,发布先后顺序应依次为 A、B-C、D ,其中 B 和 C 组件可同时发布,D 则需要等 B、C 都发布完成后才可以发布,也就是说只有当前组件的依赖没有包含未发布组件,此组件才可发布。
- 我们以前的发布情况常常是这样的:下层组件 A 由于 lint 不通过,导致依赖 A 的 B、C 都 lint 失败,由于没有限制开发者对私有源仓库的 push 权限,B、C 组件的负责人这时候可能就会选择向私有源仓库强推 podspec,导致出现 lint 失败的连锁反应,越来越多的组件本身代码没问题,却因为下层组件而 lint 失败,只能选择强推 podspec。遇到这种情况,除了强调发布规则,从根本上还是要减少发版操作给组件负责人带来的工作量。
- labor 就是为了能在一定程度上解决以上问题而创建的,在 labor 上执行发版操作时,组件负责人只需要关注 lint 的错误信息即可,剩余发布操作,包括上下层组件的发布顺序都由 labor 进行管理。
三、效果演示
- 以上述的 A、B、C、D 组件为例,在 labor 上添加发布并分析依赖后,可以看到组件发布页:
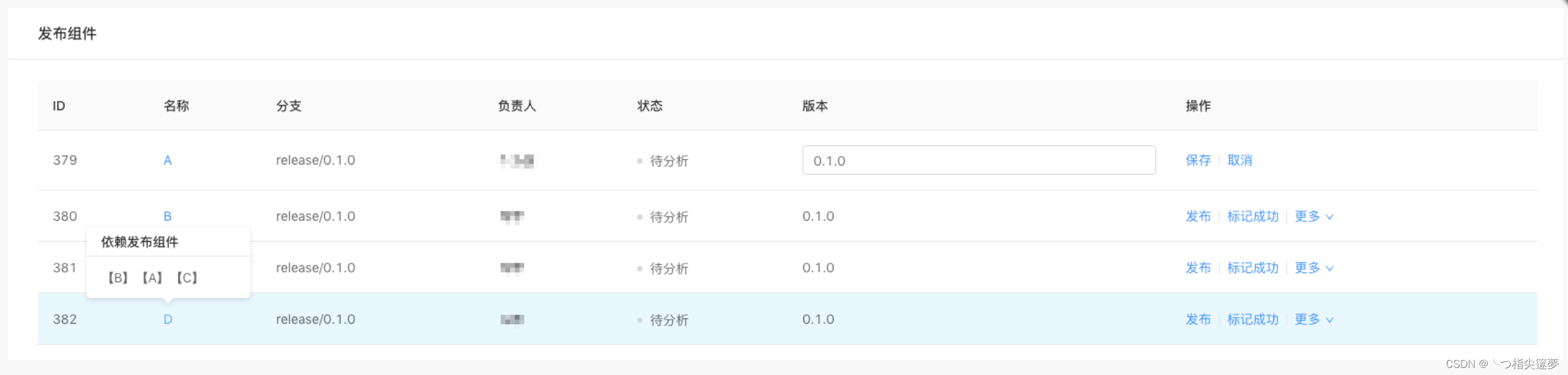
- 在发布页中,使用者可以查看依赖发布的组件,也可以修改发布组件的版本,labor 会在组件发布时同步到仓库的 podspec 文件中。执行自动发布后,labor 会和 GitLab 进行一系列交互。
- 以组件 A 为例,labor 会先创建所有发布组件目标分支的 MR:

- 然后触发对应 release 分支的 pipeline:

- 这里省去的 code review 这一步骤,如果需要的话,可以在 web 上设置入口,组件负责人设置为 review 完成后,才触发 pipeline。如果 pipeline 执行成功,那么 GitLab 会自动合并 MR,如果冲突的话,需要负责人在此 MR 下解决:
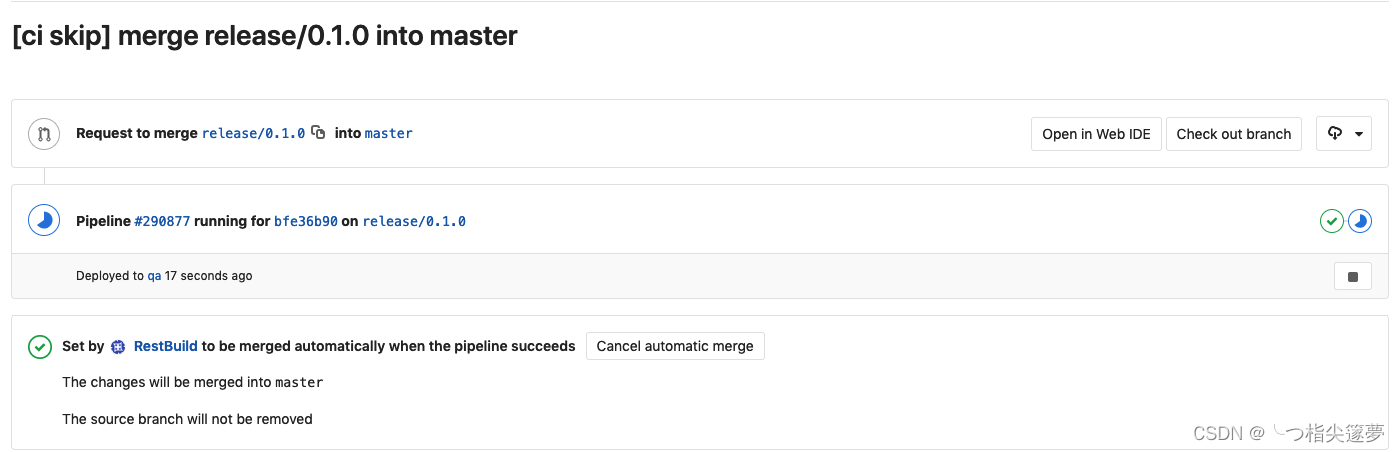
- MR 合并成功后,组件会更新状态为发布中(假如组件还有依赖未发布,那么这里的状态为已合并,等待依赖发布完成,状态才为发布中):

- 然后 labor 会给组件打 tag,并且触发 tag 的 pipeline:

- 在 tag 的 pipeline 执行成功后,就视 A 组件发布成功。A 发布成功后,labor 会查看 B、C 对应 MR 状态执行后续操作:
-
- MR pipeline 已经执行成功,并且对应的分支已经合并到 master (组件状态:已合并);
-
- MR pipeline 由于 A 没发布,lint 失败,分支没有合并到 master(组件状态:等待中);
- 如果是 1 状态,则直接创建 tag 发布,如果是 2 状态,则触发 MR 对应分支的 pipeline,假如此 MR 是因为 A 组件未发布导致合并失败的,那么在 A 发布后,重新触发的 MR pipeline 一般都能执行成功,当 MR 合并成功后,后续步骤与 1 一致。受益于 GitLab 分布式的 runner,可以通过 CI 同时发布多个组件。
- 当所有组件发布完成后,labor 会根据使用者输入的组件版本,更新发版工程的 Podfile:
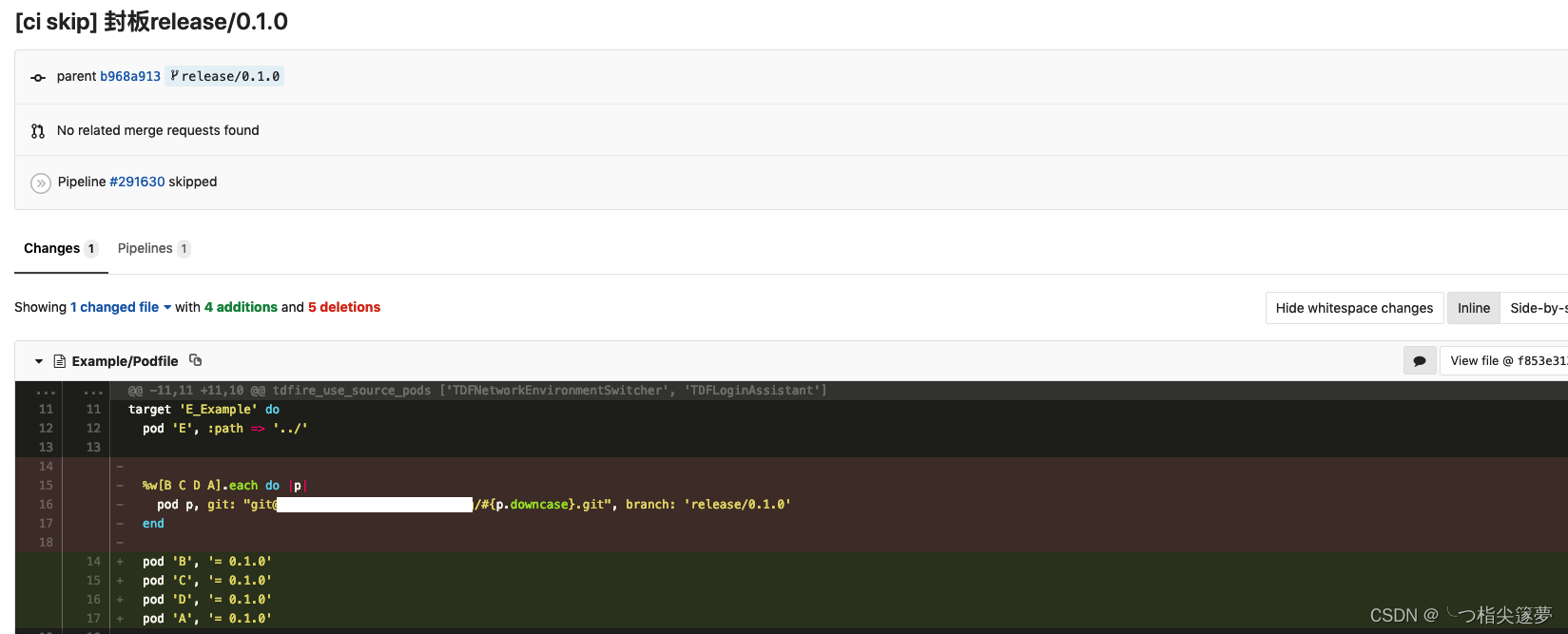
- 以上就是 labor 的主要工作步骤,可以看到,使用 labor 发版后,组件负责人只需要确保 MR 能顺利合并即可,不需要等待下层组件负责人发布完成的通知,也省去了繁琐的发布操作。
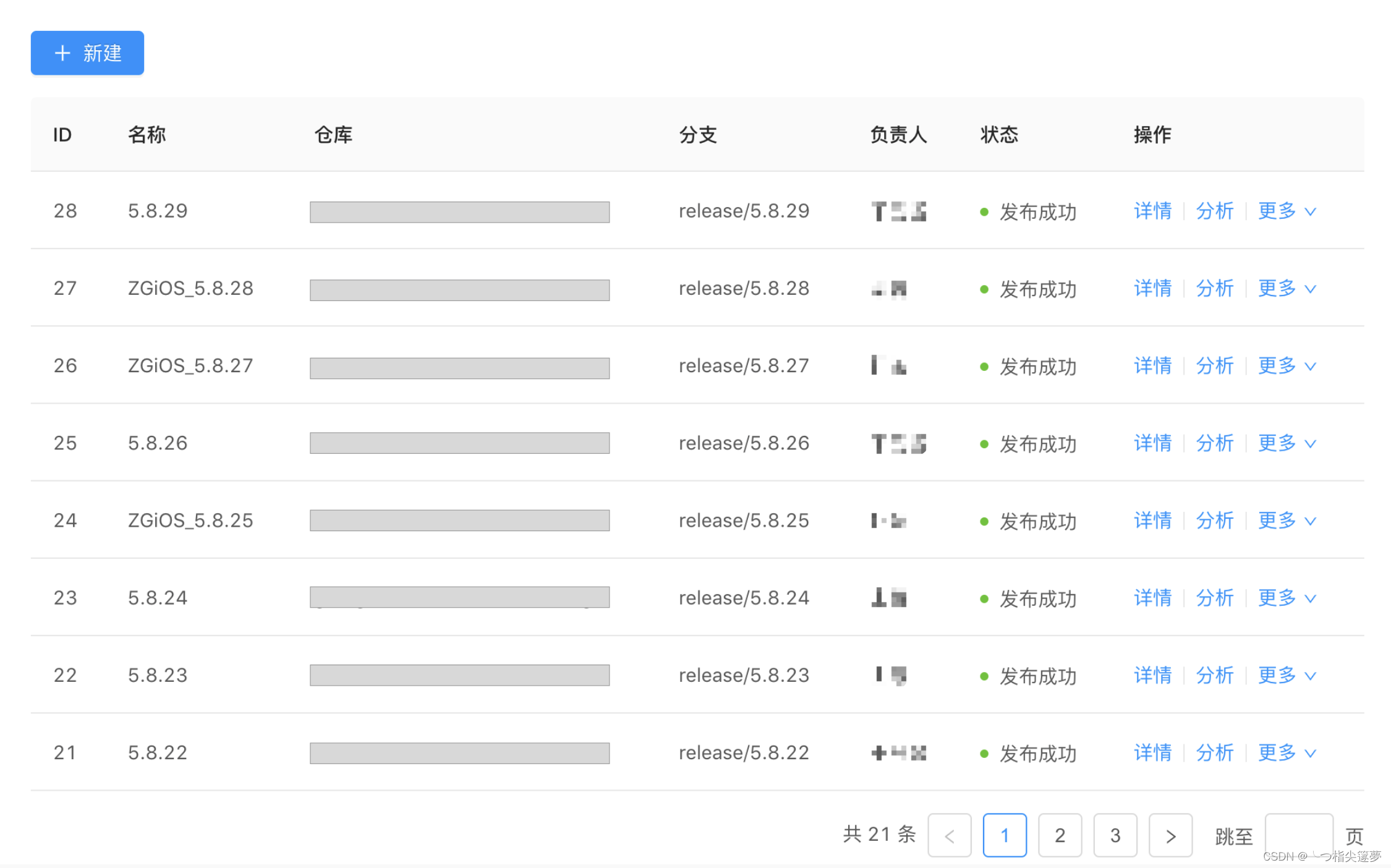
- 截止到目前为止,labor 已经帮助团队执行了近 30 次自动发布,每次发布的组件个数平均在 15 个左右,节省了很多组员沟通与操作时间。
四、labor 结构与发布类型
- labor 由如下几个服务构成:
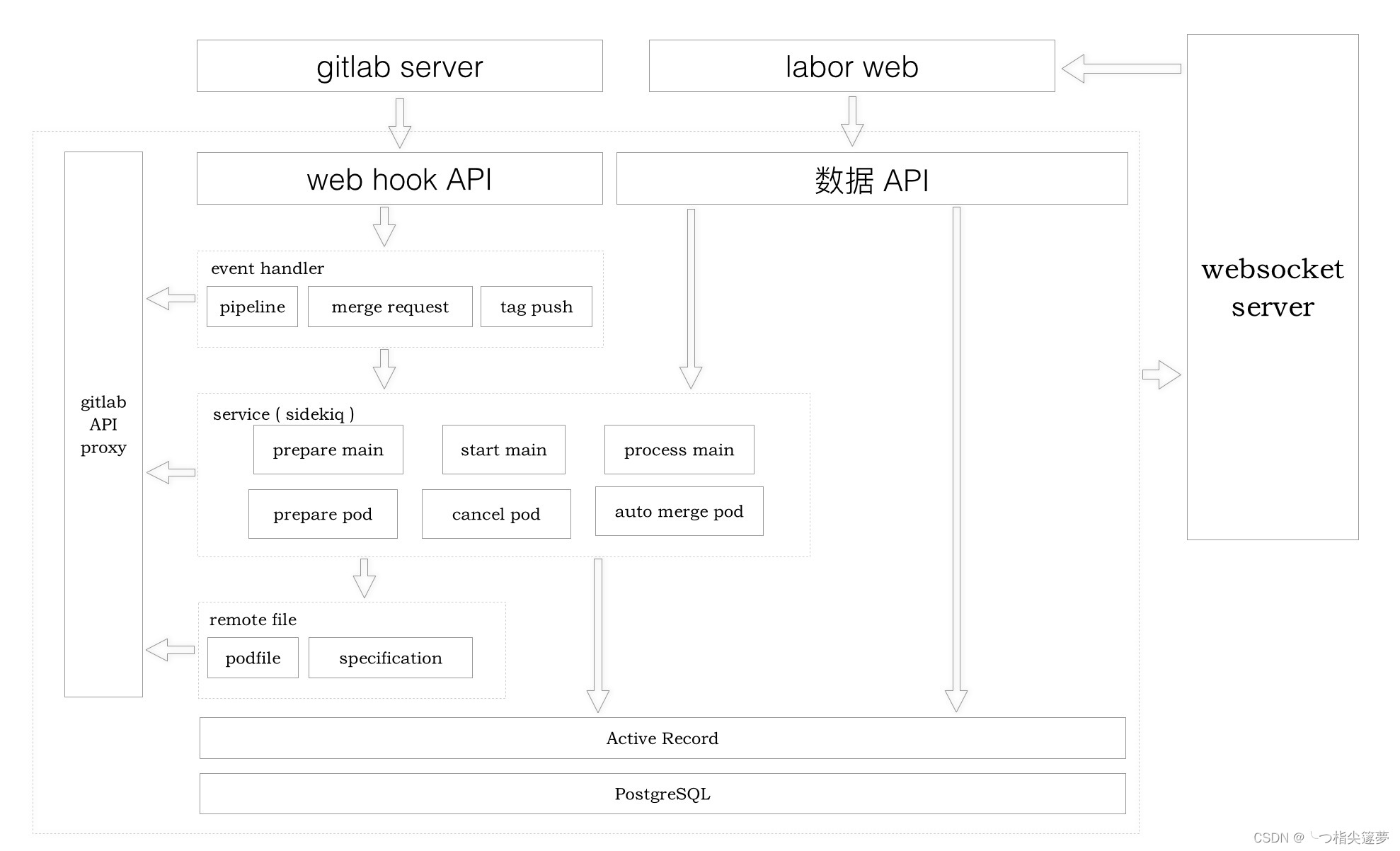
- 其中 web 端主要专注于发版交互与组件发布数据的展示,后端负责发版信息采集、组件发布任务调度以及和 GitLab 进行通信,websocket server 主要负责实时更新 web 中组件的发布状态。server 中很多操作都是与 GitLab 进行交互,耗时较多,所以 server 中的大部分 service 都是交给 sidekiq(后台任务处理系统)执行的。
- 依据发布性质,labor 把发布分为两种:
-
- 主发布 (main deploy);
-
- 子发布 (pod deploy)。
- 这里主发布的主体是发版工程,子发布的主体是组件,其中主发布主要负责发版工程信息的获取和更新,比如依赖的分析、最后目标分支 Podfile 的更新等。主发布经过分析后,会创建若干子发布,子发布则负责组件发布的所有流程,包括组件 MR 的创建,组件 tag 的创建,发布 CI 的触发等。
- 主发布和子发布涉及的所有状态如下:
created: '待分析',
analyzing: '分析中',
preparing: '准备中',
pending: '等待中',
waiting: '待发布',
skipped: '已忽略',
merged: '已合并',
deploying: '发布中',
success: '发布成功',
failed: '发布失败',
canceled: '已取消',
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 使用 state_machines-activerecord 以状态机的形式对发布状态进行管理,状态发生变更之后,都会通过 websocket 同步到 web 端。
- 分析目标工程的组件依赖是发版的第一步,对应主发布的 analyzing 状态,如下是 labor 分析步骤的序列图:
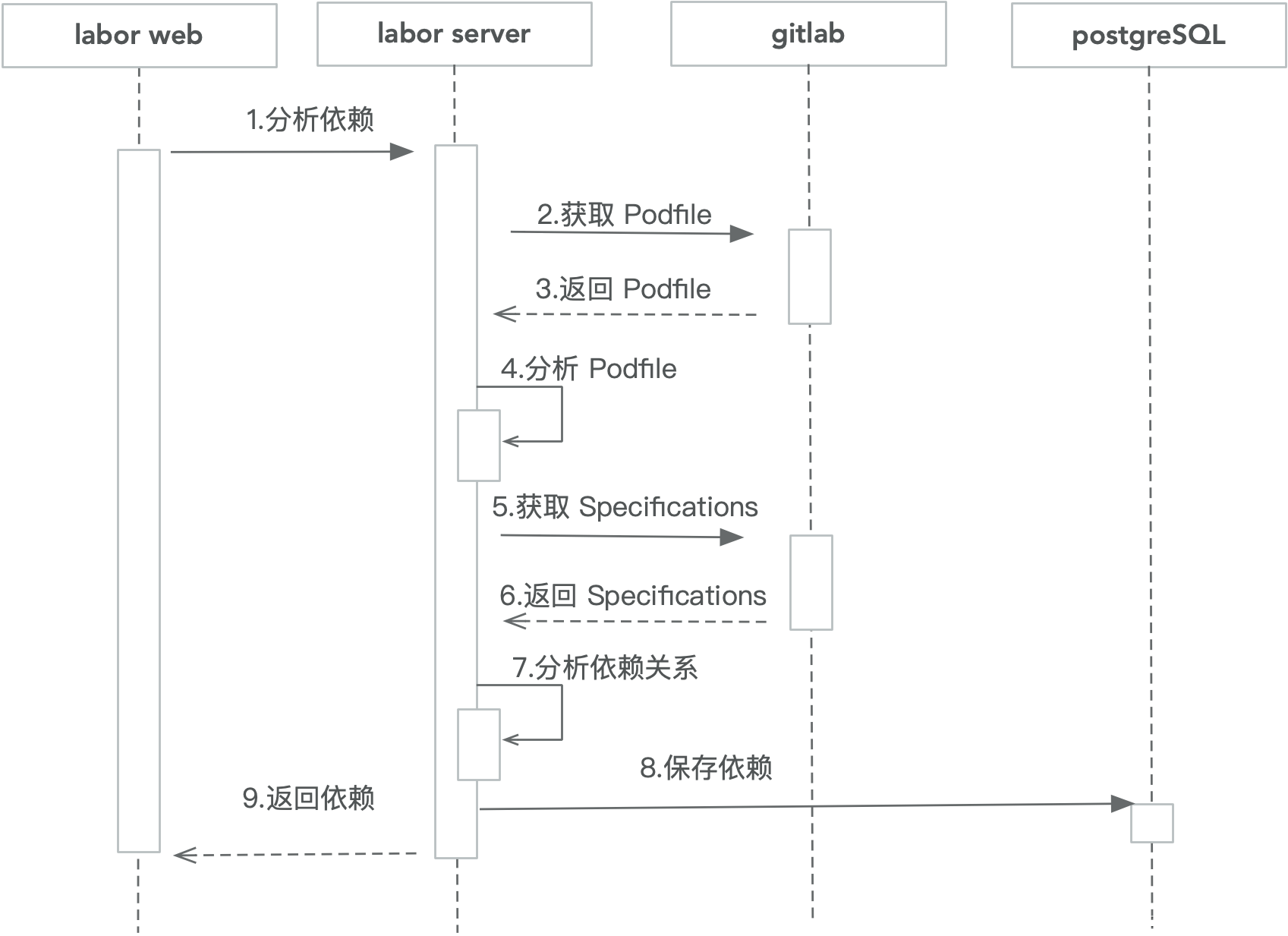
- 首先,web 向 server 端发起分析依赖请求,server 接收到请求后,使用 gitlab 向 GitLab 请求 Podfile 文件内容。由于 Podfile 可能在仓库的根目录或者 Example 文件夹下,使用 5 层深度的递归查询来获取文件路径。
- 获取到 Podfile 路径后,再根据文件内容创建 Podfile 对象:
# Labor::RemoteFile::Base
def file_contents
@file_contents ||= gitlab.file_contents(@project_id, @path, @ref)
rescue Gitlab::Error::NotFound => error
# self.class.name.demodulize
# [2..-1]
raise Labor::Error::NotFound.new("Can't find #{self.class.name.split('::').drop(2).join('')} with error #{error.message}")
end
# Labor::RemoteFile::Podfile
def podfile
@podfile ||= begin
content = file_contents
podfile = Pod::Podfile.from_ruby(Pathname.new(path), content)
podfile
end
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 生成 Podfile 对象后就可以分析发版信息,可以先过滤出需要发版的依赖:
podfile.dependencies.select { |dependency| dependency.external? && dependency.external_source[:tag].nil?}
- 1
- 然后通过同样的方式循环获取这些依赖的 podspec 文件,并且构建 Specification 对象:
untagged_specs = Parallel.map(untagged_git_dependencies, in_threads: 5) do |dep|
git = dep.external_source[:git]
ref = dep.external_source[:branch]
component_project = gitlab.project(git)
remote_file = Labor::RemoteFile::Specification.new(component_project.id, ref)
remote_file.specification
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 这里可以利用多线程加快执行效率,不过线程数不要过多,不然容易造成 GitLab 返回数据失败。获取到所有需要发布的 spec 后,可以结合组件与其依赖、间接依赖创建发布结构,然后保存至数据库。
- 同样以 A、B、C、D 组件为例,它们的 podspec 依赖如下:
# podspec
A
B
> A
C
> A
D
> B
> C
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 最终生成的发布结构如下:
# 发布结构
A
B
> A
C
> A
D
> A
> B
> C
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 当 A 发布完成后,发布结构转变为:
# 发布结构
A
B
C
D
> B
> C
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- B、C 组件会在需要发布的依赖清空之后,继续执行组件发布的后续操作。
五、发布组件
① 组件发布核心过程
- 组件的发布是整个服务的核心功能,顺利发布单个组件时的序列图如下:

- 上图中省略了部分和 websocket server 相关的逻辑,实际上其右边的状态发生变更时,都会进行 12、13 步骤的消息流动。
- 如果是自动发布所有组件,而不是发布单个组件,labor 会对主发布分析出的所有组件执行发布操作,这样相关负责人就可以选择提前去 review MR 上需要合并的代码,而不是等依赖的组件发布完成。
- 对于已知 lint 不通过,短时间无法解决错误的组件,labor 提供了手动标志组件发布成功的功能,使用者需要手动发布组件,再设置发布成功。添加这个功能主要是考虑到发版工程会接入其他业务线的组件,而我们并不想让这些组件影响发版进程。
- 组件发布过程中,根据处理对象的不同,又可分为以下两个阶段:
-
- 准备阶段(preparing ~ pending);
-
- 正式发布阶段(merged ~ success)。
② 准备阶段
- 首先,server 会给还未配置过的组件工程添加 webhook ,GitLab 很多任务都是放到 sidekiq 的,要想获取任务的执行信息,只能通过 webhook 让 GitLab 主动发送,所以这一步是组件能自动发布的重要前提。
- 接着,server 会校验创建 MR 的必要条件:
-
- 组件仓库必须要有 CI 配置文件,并且文件中包含发布 stage;
-
- 组件仓库的 default 分支必须为 master。
- 如果满足以上条件,我们会继续处理目标组件的 podspec 版本。labor 在分析依赖时,默认会使用 release 分支名中或者 podspec 中较高的版本号作为发布版本,如果实际发布时,组件发布版本比仓库中的 podspec 高,就需要更新 GitLab 仓库中 podspec 的 version 字段。
- 更新 podspec 版本的代码:
def update_podspec_content(podspec_content, version)
require_variable_prefix = true
version_var_name = 'version'
variable_prefix = require_variable_prefix ? /\w\./ : //
version_regex = /^(?<begin>[^#]*#{variable_prefix}#{version_var_name}\s*=\s*['"])(?<value>(?<major>[0-9]+)(\.(?<minor>[0-9]+))?(\.(?<patch>[0-9]+))?(?<appendix>(\.[0-9]+)*)?(-(?<prerelease>(.+)))?)(?<end>['"])/i
version_match = version_regex.match(podspec_content)
updated_podspec_content = podspec_content.gsub(version_regex, "#{version_match[:begin]}#{version}#{version_match[:end]}")
updated_podspec_content
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 更新字符串后,同步至 GitLab:
gitlab.edit_file(@project_id, @path, @ref, content, "更正 podspec 版本 #{version}".ci_skip)
- 1
- 这里 commit 信息以 [ci skip] 作为前缀,以减少触发不必要的 pipeline。最后,会校验目标分支是否为 master 或者已经合并到 master ,如果是的话 server 会直接标记此发布为 merged ,等待正式发布,否则 server 会给组件仓库创建 MR ,发布进入 pending 状态,等依赖的组件都发布完成后,如果此 MR 还未合并,server 会重新触发 MR 关联的 pipeline,pipeline 运行成功,目标分支合入 master 后,再执行正式发布。
③ 正式发布阶段
- 由于 tag 触发的 pipeline 包含二进制打包、源码及二进制版本发布的 stage,因此在这个阶段只需要管理 tag 及关联的 pipeline 就可以实现发布功能。这时候如果 tag 版本已经存在,GitLab 会返回创建失败,虽然 GitLab 提供了删除 tag 的功能,但还是不建议这么做的,我们会在 web 端提示发布失败,并且注明 tag 已存在,让组件负责人修改版本后重试发布此组件。
- GitLab 创建 tag 操作是异步的,因此我们会在 webhook 中监听 tag 创建结果,创建成功之后,就可以处理 pipeline。上文提到过 以 [ci skip] 开头 commit 不会触发 pipeline,所以需要在这里做下判断,如果已经有 pipeline,那么只更新对应数据库条目,否则就需要创建新的 pipeline。
六、更新依赖
- 在所有组件发布完成后,我们会把变更的组件版本,同步到发版工程对应分支的 Podfile 中。受限于目前的工作流程和有限的工具链,在开发时,还是避免不了手动修改 Podfile,所以依旧使用 ruby 来编写 Podfile,没有使用 YAML 或者 JSON 格式 (pod ipc podfile/podfile-json 可查看)。
- 过于灵活的编写方式,使得对其执行正则匹配需要以先推行编写规范为基础,因此不使用正则,而是让开发者提供 Podfile 模版,比如正常的 Podfile 为:
# 一些 ruby 语法的配置
target 'E' do
pod 'A', git: 'xxxx', branch: 'release/0.1.0'
pod 'J'
end
# 一些 ruby 语法的配置
- 1
- 2
- 3
- 4
- 5
- 6
- 那么开发者可以在同级目录下,添加 PodfileTemplate :
# 一些 ruby 语法的配置
target 'E' do
:TRIPLECCREPLACEME
end
# 一些 ruby 语法的配置
- 1
- 2
- 3
- 4
- 5
- labor 会先获取原 Podfile,解析其依赖之后,再根据数据库中的组件及其发布版本号,更新这些依赖,然后将 PodfileTemplate 文件的 :TRIPLECCREPLACEME 替换成更新后的依赖,以生成新的 Podfile:
# 一些 ruby 语法的配置
target 'E' do
pod 'A', '= 0.1.0'
pod 'J'
end
# 一些 ruby 语法的配置
- 1
- 2
- 3
- 4
- 5
- 6
- 当然,在工具链成熟的情况下,使用 JSON 或者 YAML 格式编写的 Podfile,更易于自动化处理,所以个人推荐前期最好不要在 Podfile 中添加过多 ruby 自定义代码,如果需要的话,可以以 cocoapods 插件的形式集成。
七、总结
- 由于 labor 只是个人在开发维护,所以制定流程和细节处理上可能不是非常合理,但就目前成果来看,labor 还是初步实现了发版时的组件自动化发布。本文更多的是展示了正常发布流程,实际上整个发布过程中,还是要处理挺多异常流程的。
- 不过在发版本时才统一对需要发布的组件进行验证,容易出现解决组件 lint 错误时间过长影响发版问题,所以可能还是需要添加组件准入规则,将这部分验证往前移,比如约束主工程的分支权限,在预发提测前让开发者预先打 rc 版本,确保 rc 版本验证成功之后,再以 web 操作的方式接入主工程,预发阶段修复组件 bug 后,重新走接入流程,这样应该就能保证发版时,需要发布组件的正确性(关于 rc 版本的 lint ,可能还需要变更下 CocoaPods 查找版本的默认方式,毕竟 Semantic Versioning 优先采用正式版本)。
文章来源: blog.csdn.net,作者:╰つ栺尖篴夢ゞ,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Forever_wj/article/details/124024658

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)