大数据平台架构解析——以讯飞大数据平台Odeon为例

@[toc]
大数据平台架构解析——以讯飞大数据平台Odeon为例
定义
Odeon大数据平台以全图形化Web操作的形式为用户提供一站式的大数据能力:包括数据采集、任务编排、调度及处理、数据展现(BI)等;同时提供完善的权限管理、日志追踪、集群监控等能力
功能
-
数据通道:SQL、NoSql数据库及日志多源数据接入与导出
-
数据管理:完善的元数据管理、数据质量标准管理体系,同时具备完整的数据隔离及授权机制
-
数据分析:支持离线批处理、流式计算、OLAP、AdHoc等多种计算方式
-
数据服务:基于Greenplum和Kylin的数据服务架构,提供DaaS(数据即服务)服务
-
调度管理:可视化工作流构建,基于Time、Event等触发机制,全程状态监控
-
可视化运维:物理集群、分析作业、工作流、资源使用情况等全方位可视化监控及告警
-
快速部署:平台开发及部署采用业界主流DevOps模式,全组件镜像化,实现快速部署运维

(以上均来自讯飞官网的定义;)
总的来说——主要的也就是
- 数据采集,
- 数据开发,
- 数据分析,
- 数据编程

数据采集
主要分为结构化通道和日志通道;
结构化:包含一些常用的关心型数据库,例如:MySQL,Oracle;还有k-v的MongoDB 等等。
日志:一些业务上产生的锚点产生的数据等等。

数据开发
Apache Oozie是Hadoop工作流调度框架。它是一个运行相关的作业工作流系统。这里,用户被允许创建向非循环图工作流程,其可以在并列 Hadoop 并顺序地运行。
它由两部分组成:
工作流引擎:一个工作流引擎的职责是存储和运行工作流程,由 Hadoop 作业组成:MapReduce, Pig, Hive.
协调器引擎:它运行基于预定义的时间表和数据的可用性工作流程作业。
Oozie可扩展性和可管理及时执行成千上万的工作流程(每个由几十个作业)的Hadoop集群。
Oozie 也非常灵活。人们可以很容易启动,停止,暂停和重新运行作业。Oozie 可以很容易地重新运行失败的工作流。可以很容易重做因宕机或故障错过或失败的作业。甚至有可能跳过一个特定故障节点。

-
支持Oozie编辑器,可以通过仪表板提交和监控
Workflow、Coordinator和Bundle-
Oozie是管理hadoop作业的调度系统
-
Oozie的工作流作业是一系列动作的有向无环图(DAG)
-
Oozie协调作业是通过 时间(频率) 和有效数据触发当前的Oozie工作流程
-
Oozie支持各种hadoop作业,例如:
java mapreduce、Streaming mapreduce、hive、sqoop和distcp(分布式拷贝)等等,也支持系统特定的作业,例如java程序和shell脚本。
-
Oozie是一个可伸缩,可靠和可拓展的系统
-
-
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
-
基于文件浏览器(
File Browser)访问HDFS -
基于
Hive编辑器来开发和运行Hive查询 -
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
-
支持基于Impala的应用进行交互式查询
-
支持Spark编辑器和仪表板(Dashboard)
-
支持Pig编辑器,并能够提交脚本任务
-
支持Oozie编辑器,可以通过仪表板提交和监控
Workflow、Coordinator和Bundle-
Oozie是管理hadoop作业的调度系统
-
Oozie的工作流作业是一系列动作的有向无环图(DAG)
-
Oozie协调作业是通过**时间(频率)**和有效数据触发当前的Oozie工作流程
-
Oozie支持各种hadoop作业,例如:
java mapreduce、Streaming mapreduce、hive、sqoop和distcp(分布式拷贝)等等,也支持系统特定的作业,例如java程序和shell脚本。
-
Oozie是一个可伸缩,可靠和可拓展的系统
-
-
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
特性
- 不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
- 由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
- 支持通过增加机器进行横向扩展;
- 支持数据分片;
- 支持 RegionServers 之间的自动故障转移;
- 易于使用的 Java 客户端 API;
- 支持 BlockCache 和布隆过滤器;
举个例子
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
- 该表具有两个列族,分别是 personal 和 office;
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。

特点
- 容量大:一个表可以有数十亿行,上百万列;
- 面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
- 稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
- 数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
- 存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
Phoenix
Phoenix是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在Phoenix之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix的理念是we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成
Spring Data JPA或Mybatis等常用的持久层框架来操作 HBase。其次
Phoenix的性能表现也非常优异,Phoenix查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以Phoenix成为了 HBase 最优秀的 SQL 中间层。 -
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
-
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
- 什么是job?
Job简单讲就是提交给spark的任务。 - 什么是stage?
Stage是每一个job处理过程要分为的几个阶段。 - 什么是task?
Task是每一个job处理过程要分几为几次任务。Task是任务运行的最小单位。最终是要以task为单位运行在executor中。 - Job和stage和task之间有什么关系?
Job----> 一个或多个stage—> 一个或多个task
- 什么是job?
-
支持Job设计器,能够创建MapReduce/Streaming/Java Job
-
支持Sqoop 2编辑器和仪表板(Dashboard)
-
支持ZooKeeper浏览器和编辑器
-
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
-
使用sentry基于角色的授权以及多租户的管理.(Hue 2.x or 3.x)

数据分析
OLAP全称为在线联机分析应用,是一种对于多维数据分析查询的解决方案。典型的OLAP应用场景包括销售、市场、管理等商务报表,预算决算,经济报表等等。
最早的OLAP查询工具是发布于1970年的Express,然而完整的OLAP概念是在1993年由关系数据库之父EdgarF.Codd 提出,伴随而来的是著名的“twelvelaws of online analytical processing”. 1998年微软发布MicrosoftAnalysis Services,并且在早一年通过OLE DB for OLAP API引入MDX查询语言,2001年微软和Hyperion发布的XML forAnalysis 成为了事实上的OLAP查询标准。如今,MDX已成为与SQL旗鼓相当的OLAP 查询语言,被各家OLAP厂商先后支持。
OLAPCube是一种典型的多维数据分析技术,Cube本身可以认为是不同维度数据组成的dataset,一个OLAP Cube 可以拥有多个维度(Dimension),以及多个事实(Factor Measure)。用户通过OLAP工具从多个角度来进行数据的多维分析。通常认为OLAP包括三种基本的分析操作:上卷(rollup)、下钻(drilldown)、切片切块(slicingand dicing),原始数据经过聚合以及整理后变成一个或多个维度的视图。
传统OLAP根据数据存储方式的不同分为ROLAP(Relational OLAP)以及MOLAP(Multi-dimensionOLAP)
ROLAP 以关系模型的方式存储用作多维分析用的数据,优点在于存储体积小,查询方式灵活,然而缺点也显而易见,每次查询都需要对数据进行聚合计算,为了改善短板,ROLAP使用了列存、并行查询、查询优化、位图索引等技术
MOLAP 将分析用的数据物理上存储为多维数组的形式,形成CUBE结构。维度的属性值映射成多维数组的下标或者下标范围,事实以多维数组的值存储在数组单元中,优势是查询快速,缺点是数据量不容易控制,可能会出现维度爆炸的问题。
Apache kylin是一个开源的分布式分析引擎。它通过ANSI-SQL接口,提供基于hadoop的超大数据集(TB-PB级)的多维分析(OLAP)功能。
只需三步,kylin即可实现超大数据集上的亚秒级(sub-second latency)查询。
- 确定hadoop上一个星型模式(
Star schema)的数据集。 - 构建数据立方体(
Data cube)。 - 可通过
ODBC, JDBC,RESTful API等接口在亚秒级的延迟内查询相关数据。
OLAP-Kylin是基于Apache Kylin定制的Odeon大数据平台上的一个开源OLAP引擎。它采用多维立方体预计算技术,可以将大数据的SQL查询速度提升到亚秒级别。相对于之前的分钟乃至小时级别的查询速度,亚秒级别速度是百倍到千倍的提升,改引擎为超大规模数据集上的交互式大数据分析打开了大门。
核心组件:
数据立方体构建引擎(Cube Build Engine):当前底层数据计算引擎支持MapReduce1、MapReduce2、Spark等。
Rest Server:当前kylin采用的ODBC, JDBC,RESTful API接口提供web服务。
查询引擎(Query Engine):REST Server接收查询请求后,解析sql语句,生成执行计划,然后转发查询请求到Hbase中,最后将结构返回给REST Server。

- 为什么引入kylin?
由于数据是基于hadoop分布式存储,所以比mysql的伸缩性好。
提供hadoop上超大数据规模( 百亿行级别的数据)的亚秒级(sub-second latency)SQL查询,相对于hive的离线分析,可做到实时查询。
可无缝整合其他BI工具,如Tableau, PowerBI,Excel。

Apache kylin核心:Kylin的(OLAP) 引擎由元数据引擎、查询引擎、任务引擎、存储引擎组成。另外,它还有一个rest服务器对外提供查询请求的服务。
可扩展性:提供插件机制支持额外的特性和功能。
与其他系统的整合:可整合任务调度器,ETL工具、监控及告警系统。
驱动包(Drivers):提供ODBC、JDBC驱动支持与其他工具(如Tableau)的整合。
表(Table):表定义在hive中,是数据立方体(Data cube)的数据源,在build cube 之前,必须同步在 kylin中。
模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table)和多个查找表(Lookup Table)的连接和过滤关系。
立方体(Cube):它定义了使用的模型、模型中的表的维度(dimension)、度量(measure) ,一般指聚合函数,如:sum、count、average等)、如何对段分区( segments partition)、合并段(segments auto-merge)等的规则。
立方体段(Cube Segment):它是立方体构建(build)后的数据载体,一个 segment 映射hbase中的一张表,立方体实例构建(build)后,会产生一个新的segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的segment即可。
作业(Job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例build时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。如作业执行的状态信息为RUNNING 时,表明立方体实例正在被构建;若作业状态信息为FINISHED ,表明立方体实例构建成功;若作业状态信息为ERROR ,表明立方体实例构建失败!作业的所有状态如下:
1,NEW - This denotes one job has been just created.
2,PENDING - This denotes one job is paused by job scheduler and waiting for resources.
3,RUNNING - This denotes one job is running in progress.
4,FINISHED - This denotes one job is successfully finished.
5,ERROR - This denotes one job is aborted with errors.
6,DISCARDED - This denotes one job is cancelled by end users.
当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法:
一个完整的数据立方体,由N-dimension立方体,N-1 dimension立方体,N-2维立方体,0 dimension立方体这样的层关系组成,除了N-dimension立方体,基于原数据计算,其他层的立方体可基于其父层的立方体计算。所以该算法的核心是N次顺序的MapReduce计算。
在MapReduce模型中,key由维度的组合的构成,value由度量的组合构成,当一个Map读到一个key-value对时,它会计算所有的子立方体(child cuboid),在每个子立方体中,Map从key中移除一个维度,将新key和value输出到reducer中。直到当所有层计算完毕,才完成数据立方体的计算
数据编程
- Scala 、Java
- SQL 见博文 https://hiszm.blog.csdn.net/article/details/119540143
前端使用的是hue作为web UI; 通过wappalyzer可以看出基本的部分组件

Hue是一个Web应用(默认端口8888),用来简化用户和Hadoop集群的交互。
Hue技术架构,如下图所示,从总体上来讲,Hue应用采用的是B/S架构,hue是基于django框架开发,python作为底层语言。
大体上可以分为三层,分别是前端view层、Web服务层和Backend服务层。Web服务层和Backend服务层之间使用RPC((Remote Procedure Call)—远程过程调用)的方式调用。
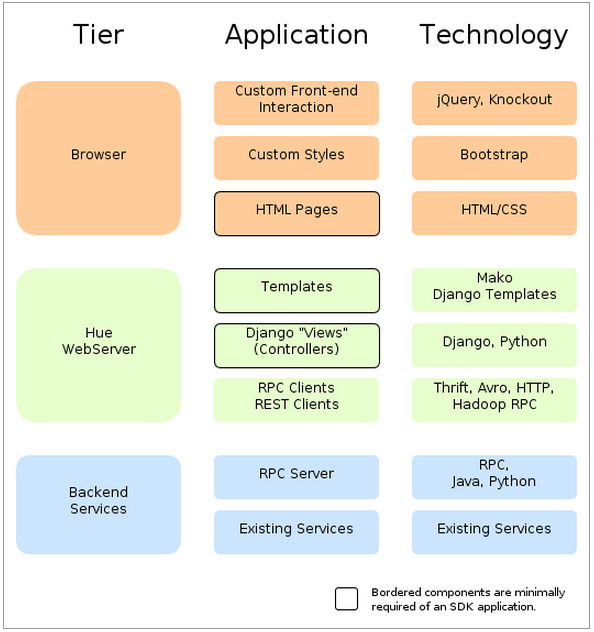
为什么使用hue呢?由于大数据框架很多,为了解决某个问题,一般来说会用到多个框架,但是每个框架又都有自己的web UI监控界面,对应着不同的端口号。比如HDFS(50070)、YARN(8088)、MapReduce(19888)等。这个时候有一个统一的web UI界面去管理各个大数据常用框架是非常方便的。这就使得对大数据的开发、监控和运维更加的方便。
| 大数据组件 | 常用的端口及说明 |
|---|---|
| CDH | 7180: Cloudera Manager WebUI 端口 7182: Cloudera Manager Server 与 Agent 通讯端口 |
| Hadoop | 50070:HDFS WEB UI 端口 8020 : 高可用的 HDFS RPC 端口 9000 : 非高可用的 HDFS RPC 端口 8088 : Yarn 的 WEB UI 接口 8485 : JournalNode 的 RPC 端口 8019 : ZKFC 端口 19888:jobhistory WEB UI 端口 |
| Zookeeper | 2181 : 客户端连接 zookeeper 的端口 2888 : zookeeper 集群内通讯使用,Leader 监听此端口 3888 : zookeeper 端口 用于选举 leader |
| Hbase | 60010:Hbase 的 master 的 WEB UI 端口 (旧的) 新的是 16010 60030:Hbase 的 regionServer 的 WEB UI 管理端口 |
| Hive | 9083 : metastore 服务默认监听端口 10000:Hive 的 JDBC 端口 |
| Spark | 7077 : spark 的 master 与 worker 进行通讯的端口 standalone 集群提交 Application 的端口 8080 : master 的 WEB UI 端口 资源调度 8081 : worker 的 WEB UI 端口 资源调度 4040 : Driver 的 WEB UI 端口 任务调度 18080:Spark History Server 的 WEB UI 端口 |
| Kafka | 9092: Kafka 集群节点之间通信的 RPC 端口 |
| Redis | 6379: Redis 服务端口 |
| HUE | 8888: Hue WebUI 端口 |

补充
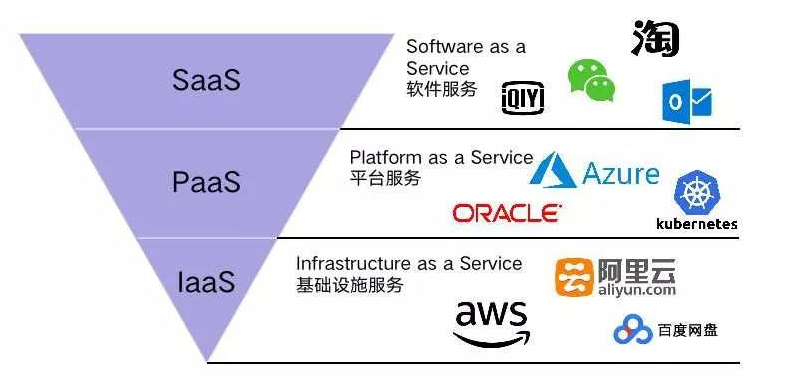
- 大数据全家桶

- IaaS,PaaS,SaaS,DaaS
数据即服务(Data-as-a-Service,DaaS)是指与数据相关的任何服务都能够发生在一个集中化的位置,如聚合、数据质量管理、数据清洗等,然后再将数据提供给不同的系统和用户,而无需再考虑这些数据来自于哪些数据源。
DevOps:Developer Operations Engineering,开发运维工程师。
- RPC
RPC:远程调用。通过RPC框架,使得我们可以像调用本地方法一样地调用远程机器上的方法:
1、本地调用某个函数方法
2、本地机器的RPC框架把这个调用信息封装起来(调用的函数、入参等),序列化(json、xml等)后,通过网络传输发送给远程服务器
3、远程服务器收到调用请求后,远程机器的RPC框架反序列化获得调用信息,并根据调用信息定位到实际要执行的方法,执行完这个方法后,序列化执行结果,通过网络传输把执行结果发送回本地机器
4、本地机器的RPC框架反序列化出执行结果,函数return这个结果


https://www.jianshu.com/p/849452eb80ab
https://www.xfyun.cn/solution/big-data-platform
http://gethue.com/
http://bh-lay.github.io/demos/vue/layout-editor/
https://blog.csdn.net/liangyihuai/article/details/54137163
http://huxiaoqiang.github.io/2016/07/17/hadoop%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA/
http://221.239.36.178/accounts/login/?next=%2Fodeon%2Fnotebook%2F%23%2Findex%2Fnotebook-list
https://www.oreilly.com/radar/bringing-interactive-bi-to-big-data/
https://fusioninsight.github.io/ecosystem/zh-hans/SQL_Analytics/Apache_Kylin_2.6.1/#_1
https://dxj1113.github.io/2017/07/17/Kylin%E5%88%9D%E6%8E%A2/

- 点赞
- 收藏
- 关注作者
评论(0)