使用Python实现K近邻-------文章中有源码

【摘要】 使用Python实现K近邻-------文章中有源码
实验目的
使用Python实现K近邻
实验原理
(1)计算测试与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别出现的概率;
(5)返回前K个点中出现概率最高的类别作为测试数据的预测分类。
实验内容(表格区域可拉长)
(1)电影类别预测;
(2)手写数字识别。
1)
代码:
import numpy as np
def distinguish():
group = np.array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])
lable = ("爱情片", "爱情片", "爱情片", "动作片", "动作片", "动作片")
list = []
temp = []
x=len(lable)
m, n , a = 0, 0, 0
text = np.array([18, 90])
for i in range(len(group)):
list.append(((text[0] - group[i][0]) ** 2 + (text[1] - group[i][1]) ** 2) ** 0.5)
# print(list)
list.sort()
print(list)
k = int(input("请输入需要投票样本的个数:"))
# 无穷大数
float('inf')
# while a<5:
# temp.append(list[a])
# a+=1
try:
for i in range(x):
temp.append(list.index(min(list)))
#置为最大值
list[list.index(min(list))] = float('inf')
# print(temp)
for i in range(k):
if lable[temp[0]] == '爱情片':
m += 1
else:
n += 1
if m > n:
print("爱情片")
else:
print("动作片")
except Exception as e:
pass
if __name__ == "__main__":
distinguish()
截图: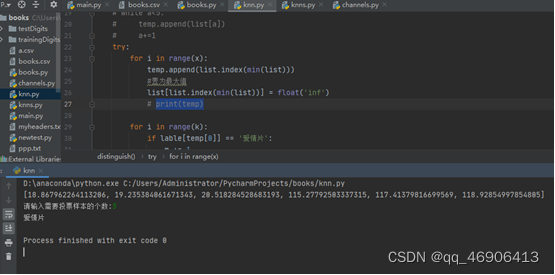
2)
import numpy as np
import os
def getData(path): #通过路径得到数据
data = []
for file in os.listdir(path):
temp = []
with open(path + file) as lines:
for line in lines:
for word in line[:-1]: #遍历一行中每个字符
temp.append(int(word))
temp.append(int(file[0]))
data.append(temp)
return np.array(data)
def calDist(l1, l2): #计算np数组距离的平方
return np.sum((l1 - l2) ** 2)
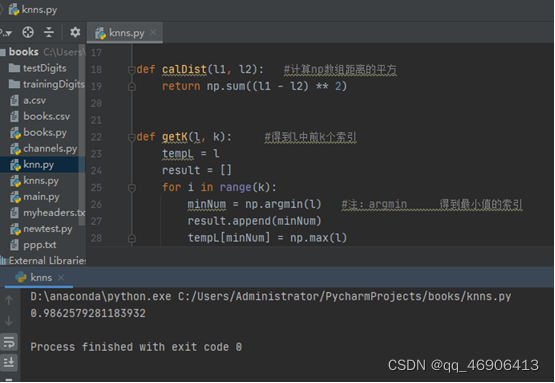
def getK(l, k): #得到l中前k个索引
tempL = l
result = []
for i in range(k):
minNum = np.argmin(l) #注:argmin 得到最小值的索引
result.append(minNum)
tempL[minNum] = np.max(l)
return np.array(result)
def mostN(l): #得到出现次数做多的元素
return np.argmax(np.bincount(l))
def knn(trainDir, testDir, k):
trainData = getData(trainDir)
testData = getData(testDir)
trueN = 0
length = len(testData)
for i in testData:
temp = []
for j in trainData:
temp.append(calDist(i[:-1], j[:-1]))
tempK = getK(temp, k)
preNum = trainData[mostN(tempK)][-1] #预测正确的标签
if i[-1] == preNum:
trueN += 1
return trueN / length
if __name__ == "__main__":
trainDir = "./trainingDigits/"
testDir = "./testDigits/"
print(knn(trainDir, testDir, 1))
截图:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)