R决策树随机森林实现

【摘要】 R决策树随机森林实现
@TOC
1 加载包和数据集
#### random forest ############
install.packages('randomForest')
library(randomForest)
data(iris)
attach(iris)
table(iris$Species)
class=as.factor(iris$Species)
2 对数据集进行描述
######描述 ############
biplot(princomp(iris[,1:4], cor=TRUE))
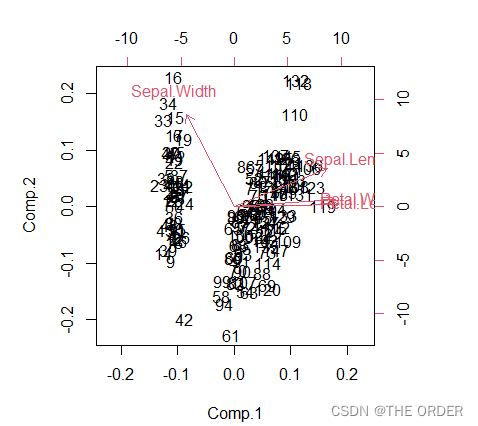
根据相关性可以查看对数据集分类效果影响最重要的变量类型
3设置训练集和测试集
set.seed(100)
ind=sample(2,nrow(iris),replace=TRUE,prob=c(0.75,0.25))
#### 训练集、测试集########
train=iris[ind==1,]
test=iris[ind==2,]
####两种模型机制 ###############
4 随机森林建模
###### 1、模型#############
iris.rf1=randomForest(Species~.,train,ntree=50,nPerm=5,mtry=3,proximity=TRUE,importance=TRUE)
print(iris.rf1)

iris.pred1=predict( iris.rf1,iris[ind==2,] )
table(observed=iris[ind==2,"Species"],predicted=iris.pred1 )
iris.rf1$importance
iris.rf1$forest
iris.rf1$votes
iris.rf1$err.rate

5 随机森林调参
创造等差数列,循环创建随机森林观察误差最小的参数,选择误差最小的参数作为模型应用
m=seq(10,5000,by=50)
colMeans(iris.rf1$err.rate)
err=NULL
for (i in 1:length(m)) {
iris.rf1=randomForest(Species~.,train,ntree=m[i],nPerm=5,mtry=3,proximity=TRUE,importance=TRUE)
err[i]=colMeans(iris.rf1$err.rate)
}
画图观察误差,使用which可以判断误差在数列中的位置,查找到最小误差值
err
plot(m,err,type="l")
plot(m,err,type="h")
which(err==min(err))
which.min(err)
m[which.min(err)]
6 重要性观察
######2、数据集 ############
RF2 <- randomForest(train[,-5], train[,5],prox=TRUE, importance=TRUE)
imp <- importance(RF2)
impvar <- imp[order(imp[,3], decreasing=TRUE),];impvar
varImpPlot(RF2)

# 一些重要参数说明
# randomForest()对训练集的数据进行处理,生成决策树
# iris.rf=randomForest(Species~.,iris[ind==1,],ntree=50,nPerm=10,mtry=3,proximity=TRUE,importance=TRUE)
# Species~.:代表需要预测的列,species是列的名称。
# iris[ind==1,]:生成决策树的训练集
# ntree:生成决策树的数目
# nperm:计算importance时的重复次数
# mtry:选择的分裂属性的个数
# proximity=TRUE:表示生成临近矩阵
# importance=TRUE:输出分裂属性的重要性
# predict()
# iris.pred=predict( iris.rf,iris[ind==2,] )
# iris.rf:表示生成的随机森林模型
# iris[ind==2,] :进行预测的测试

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)