【C++要笑着学】引用的概念 | 引用的应用 | 引用的探讨 | 常引用

![]()
写在前面:
本章将对C++的基础,引用部分的知识进行讲解。
有些地方为了能够加深理解,我们会举几个比较有意思的栗子,在讲解的同时会适当的整活。
Ⅰ. 引用的概念
0x00 引入话题
![]()
![]() 不知道大伙知不知道 "抓捕周树人跟我鲁迅有什么关系" 这个梗 ~
不知道大伙知不知道 "抓捕周树人跟我鲁迅有什么关系" 这个梗 ~

![]()
这段是2018年电视剧《楼外楼》中鲁迅先生的一段台词。剧中一个没文化的军官带着一批人要来抓捕周树人,鲁迅让他们拿出搜捕令,他们拿了出来,鲁迅看过之后就说:抓捕周树人和我鲁迅有什么关系?于是这群人都以为是抓错人了,就走了。
这一段其实是在嘲讽他们没有文化,连作家的笔名都不知道。
"抓捕周树人跟我鲁迅有什么关系" ,当然有关系了!哈哈哈哈哈哈。

![]()
后来这个军官才知道鲁迅是周树人的笔名,他们要抓的人正是鲁迅。
🔺 这个 "笔名" 其实就是引用,我们继续往下学习。
0x01 什么是引用
😂 第一次接触 "引用" 的概念时,直接看词去理解,真的会让人一脸懵逼……
但是如果用 "取别名" 或 "取绰号" 来理解,就没有那么难以理解了。
![]()
🤔 但是如果用 "取别名" 或 "取绰号" 来理解,就没有那么难以理解了。
📚 概念:引用就是给一个已经存在的变量取一个别名。
📜 语法:数据类型& 引用名 = 引用实体;
👆 这里的&可不是取地址啊!它是放在数据类型后面的&,一定要区分开来!
💬 代码演示:
#include <iostream>
using namespace std;
int main(void)
{
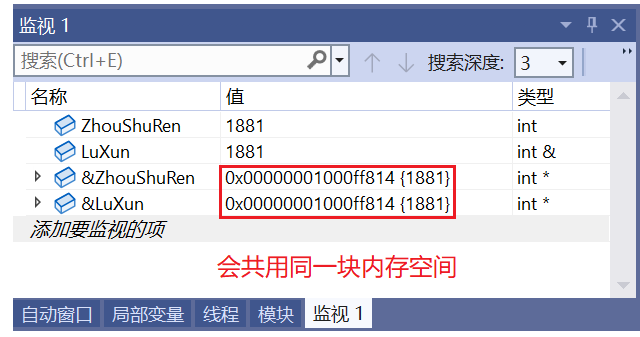
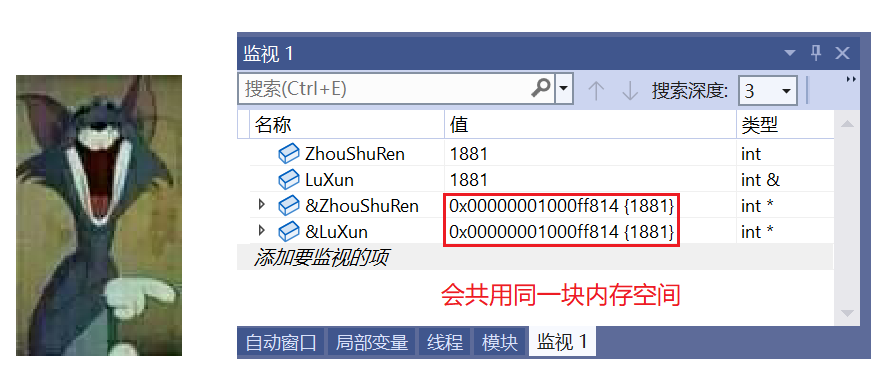
int ZhouShuRen = 1881;
int& LuXun = ZhouShuRen; // 鲁迅就是周树人的引用
cout << ZhouShuRen << endl;
cout << LuXun << endl;
return 0;
}🚩 运行结果: 1881 1881
🔑 解读:
引用在语法层,我们要理解这里没有开新空间,就是对原来的取了一个新名称而已。

![]()
📌 注意事项:
① 引用并不是新定义一个变量,只是给一个变量取别名。
② 编译器不会为引用的变量开辟内存空间,它和它引用的变量会共用同一块内存空间。
![]()
0x02 引用的特性

![]() 引用在定义时必须初始化!
引用在定义时必须初始化!
初始化时必须要指定清楚,你到底是要给谁取别名。

![]() 含糊不清是不行的,你都不知道要给谁取别名,你取他干甚呢?
含糊不清是不行的,你都不知道要给谁取别名,你取他干甚呢?
💬 又到了大伙最爱的踩坑环节:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int& b; // ❌
return 0;
}
![]()

![]() 一个变量可以有多个引用。
一个变量可以有多个引用。
一个人当然可以有多个绰号,所以一个变量也可以有多个别名。
💬 代码演示:(川普 川建国 懂王)
#include <iostream>
using namespace std;
int main(void)
{
int Trump = 2333; // 变量
int& ChuanJianGuo = Trump; // 引用1
int& DongWang = Trump; // 引用2
return 0;
}

![]() 引用一旦引用了一个实体,就不能引用其他实体了。
引用一旦引用了一个实体,就不能引用其他实体了。
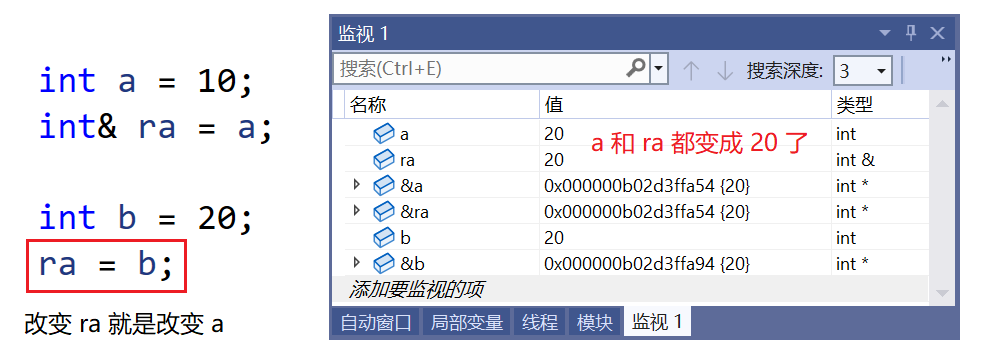
int main(void)
{
int a = 10;
int& ra = a;
int b = 20;
ra = b; // ?
return 0;
}(这里取名为 ra,因为引用的英文是 reference,所以我后面命名变量时会简写为 r,或者 ref 来代表引用)
❓ 问号处是什么意思呢?这里是让 ra 变成 b 的别名,还是把 b 的值赋值给 ra 呢?
💡 这里是赋值,我们打开监视窗口看一下:
![]()
🔺 引用是不会变的,我们定义它的时候它是谁的别名,就是谁的别名了。
以后就不会改了,它是从一而终的!!!
💬 引用和指针是截然不同的,指针是可以改变指向的:
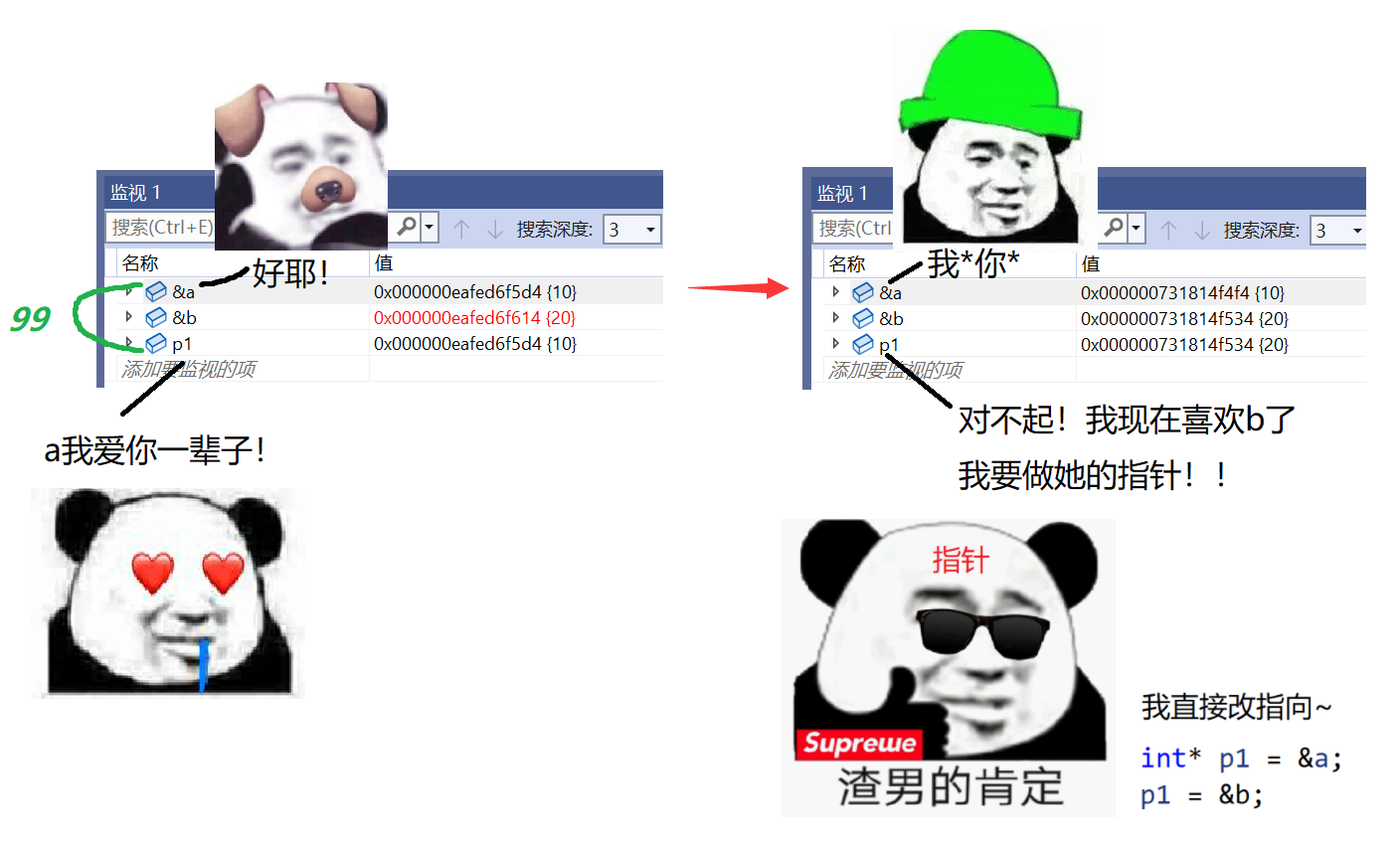
int main(void)
{
int a = 10;
int* p1 = &a;
int b = 20;
p1 = &b; // 改变指针指向
return 0;
}🔑 解析:指针在这里就像极了渣男!
![]()
📚 这里再提一句,引用的底层其实就是指针。
你可以这么理解,引用他不想像以前那样做渣男了,于是回炉重造!
《重生之我不是渣男》,开始一生只爱一个人了!

![]()
Ⅱ. 引用的应用
0x00 引入
![]()
![]() 平常这么写其实没什么意义:
平常这么写其实没什么意义:
int a = 10;
int& ra = a;❗ 它真正有用的地方在于它能够做参数和做返回值。
0x01 引用做参数
![]()
![]() 我们在C语言教学中讲过 Swap 两数交换的三种方式。
我们在C语言教学中讲过 Swap 两数交换的三种方式。
我们当时用的最多的就是利用临时变量去进行交换。
如果把它写成函数形式就是这样:
void Swap(int* px, int* py) {
int tmp = *px;
*px = *py;
*py = tmp;
}
int main(void)
{
int a = 10;
int b = 20;
Swap(&a, &b); // 传址
return 0;
}
![]() 这里我们调用 Swap 函数需要传地址,因为形参是实参的一份临时拷贝,改变形参并不会对实参产生实质性的影响。
这里我们调用 Swap 函数需要传地址,因为形参是实参的一份临时拷贝,改变形参并不会对实参产生实质性的影响。
💬 但是,我们学了引用之后我们就可以这么玩:

![]()
void Swap(int& ra, int& rb) {
int tmp = ra;
ra = rb;
rb = tmp;
}
int main(void)
{
int a = 10;
int b = 20;
Swap(a, b); // 这里既没有传值,也没有传地址,而是传引用
return 0;
}🔍 监视结果如下:
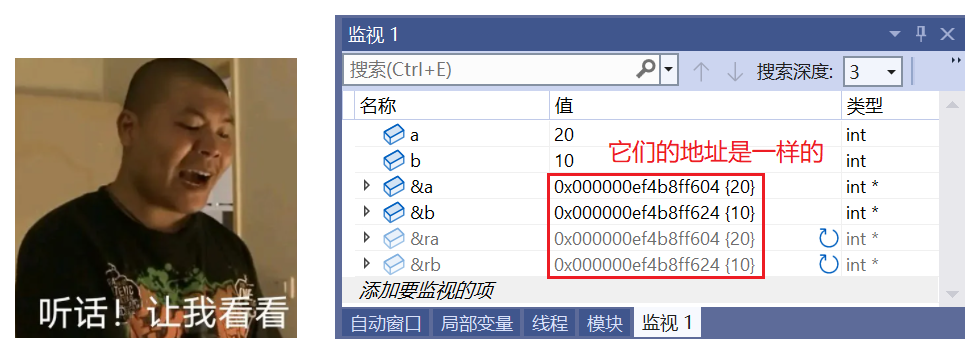
![]()
❓ 是怎么做到交换的?
🔑 我们知道,形参是定义在栈帧里面的。
实际调用这个函数的时候,才会给 ra 和 rb 开空间。调用这个函数的时候,把实参传给形参。
那什么时候开始定义的?实参传给形参的时候开始定义的。
ra 是 a 的别名,rb 是 b 的别名,所以 ra 和 rb 的交换,就是 a 和 b 的交换。
因此,我们利用这一特点,就可以轻松实现两数的交换。
🔺 我们来梳理一下,顺带复习一下之前讲的函数重载。
💬 现在我们一共学了三种传参方式:传值、传地址、传引用。
#include<iostream>
using namespace std;
void Swap(int x, int y) {
int tmp = x;
x = y;
y = tmp;
}
void Swap(int* px, int* py) {
int tmp = *px;
*px = *py;
*py = tmp;
}
void Swap(int& rx, int& ry) {
int tmp = rx;
rx = ry;
ry = tmp;
}
int main(void)
{
int a = 10;
int b = 20;
Swap(&a, &b);
Swap(a, b); // 报错 ❌
return 0;
}

![]() 这里 Swap(a,b) 为什么会报错呢?
这里 Swap(a,b) 为什么会报错呢?
这三个 Swap 是可以构成函数重载的,
只要不影响它的函数名修饰规则,就不会构影响!
换言之,修饰出来的函数名不一样,就支持重载!
void Swap(int x, int y); _Z4swapixiy
void Swap(int* px, int* py); _Z4swaprxry
void Swap(int& rx, int& ry); _Z4swappxpy

![]() 但是 Swap(a,b) 调用时存在歧义。调用不明确!
但是 Swap(a,b) 调用时存在歧义。调用不明确!
它不知道调用哪一个,是传值还是传引用,所以会报错。
当时再讲数据结构单链表的时候用的是二级指针,当时没有采用头结点的方式。
那么要传指针的地址,自然要用二级指针的方式接收。
现在我们学了引用,我们就可以试着用引用的方法来解决了(这里我们把 .c 改为 .cpp)
![]()
![]() 任何类型都是可以取别名的,指针也不例外:
任何类型都是可以取别名的,指针也不例外:
int a = 10;
int& ra = a;
int* pa = &a;
int*& rpa = pa
![]() 我们来看如何用引用的方法来实现!
我们来看如何用引用的方法来实现!
💬 SList.h:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLNodeDataType;
typedef struct SingleListNode {
SLNodeDataType data; // 用来存放节点的数据
struct SingleListNode* next; // 指向后继节点的指针
} SLNode;
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode*& rpHead, SLNodeDataType x);
// ... 略💬 SList.cpp:
#include "SList.h"
/* 打印 */
void SListPrint(SLNode* pHead) {
SLNode* cur = pHead;
while (cur != NULL) {
printf("%d -> ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
/* 创建新节点 */
SLNode* CreateNewNode(SLNodeDataType x) {
//创建,开辟空间
SLNode* new_node = (SLNode*)malloc(sizeof(SLNode));
//malloc检查
if (new_node == NULL) {
printf("malloc failed!\n");
exit(-1);
}
//放置
new_node->data = x; //存传入的数据
new_node->next = NULL; //next默认置空
return new_node; //递交新节点
}
/* 尾插(指针的引用) */
void SListPushBack(SLNode*& rpHead, SLNodeDataType x) {
//创建新节点
SLNode* new_node = CreateNewNode(x);
//如果链表是空的
if (rpHead == NULL) {
//直接插入即可
rpHead = new_node;
}
else {
//找到尾结点
SLNode* end = rpHead;
while (end->next != NULL) {
end = end->next; //令end指向后继节点
}
//插入
end->next = new_node;
}
}🔑 解读: 这里的 SLNode*& rpHead 就是 pHead 的一个别名。
💬 Test.cpp:
#include "SList.h"
// 这里我们不传二级指针了。
//void TestSList1()
//{
// SLNode* pList = NULL;
// SListPushBack(&pList, 1);
// SListPushBack(&pList, 2);
// SListPushBack(&pList, 3);
// SListPushBack(&pList, 4);
//
// SListPrint(pList);
//}
// 使用引用的方法:
// 我们传 指针的 引用!
void TestSList2()
{
SLNode* pList = NULL;
SListPushBack(pList, 1);
SListPushBack(pList, 2);
SListPushBack(pList, 3);
SListPushBack(pList, 4);
SListPrint(pList);
}
int main()
{
TestSList2();
return 0;
}🔑 解读:这里我们采用引用的方法,调用 SListPushBack 时传递的就是 pList 的引用。

![]() 这里补充一下,为了能够更简单地表示,有些书上还有这种写法。
这里补充一下,为了能够更简单地表示,有些书上还有这种写法。
定义链表结构的时候 typedef 多定义一个 pSLNode*
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用来存放节点的数据 int data
struct SingleListNode* next; // 指向后继节点的指针
} SLNode, *pSLNode;
void SListPrint(pSLNode pHead);
void SListPushBack(pSLNode& rpHead, SLNodeDataType x);
// 这么一来,就会出现这种写法 👆
// 很多书上的写法是这样的,我们一开始讲链表的时候
// 因为当时还没有出C++的教学,所以没有用这种方法。
![]()
0x02 传值返回

![]() 讲引用返回前,我们需要做一点点铺垫。
讲引用返回前,我们需要做一点点铺垫。
💬 传值返回:
int Add(int a, int b) {
int c = a + b;
return c;
}
int main(void)
{
int ret = Add(1, 2);
cout << ret << endl;
return 0;
}🔑 解读:

![]()
这里 return 的时候会生成一个临时变量(c 为 3)
将 3 复制给这个临时变量,然后返回给 ret
如果我们直接把 c 交给 ret,就会出现一些问题。
如果直接取 c 给 ret,取到的是 3 还是 随机值,就要取决于栈帧是否销毁空间!

![]() 这个时候严格来说,其实都是非法访问了。
这个时候严格来说,其实都是非法访问了。
因为这块空间已经还给操作系统了,这就取决于编译器了。
有的编译器会清,有的编译器不会清,这就太玄学了!
所以,在这中间会生成一个临时变量,来递交给 ret 。
而不是直接用 c 作为返回值,造成非法访问。
所以这里不会直接用 c 作为返回值,而是生成一个临时变量。

![]() 那么问题来了,这个临时变量是存在哪里的呢?
那么问题来了,这个临时变量是存在哪里的呢?
① 如果 c 比较小(4或8),一般是寄存器来干存储临时变量的活。
② 如果 c 比较大,临时变量就会放在调用 Add 函数的栈帧中。
🔺 总结:所有的传值返回都会生成一个拷贝
(这是编译器的机制,就像传值传参会生成一份拷贝一样)

![]() 我们用 VS 来反汇编操作一下,加深理解:
我们用 VS 来反汇编操作一下,加深理解:

![]()
🔑 解读:我们可以清楚的看到,确实是通过寄存器将 a + b 的结果交给 ret 的。
0x03 引用做返回值

![]() 我们已经知道,这里会生成一个临时变量了。
我们已经知道,这里会生成一个临时变量了。
我们现在回到正题,我们来试试引用的返回。
💬 体会下面的代码:
#include <iostream>
using namespace std;
int& Add(int a, int b) {
int c = a + b;
return c;
}
int main(void)
{
int ret = Add(1, 2);
cout << ret << endl;
return 0;
}🔑 引用返回的意思就是,不会生成临时变量,直接返回 c 的别名。

![]()
❌ 这段代码存在的问题:
① 存在非法访问,因为 Add(1, 2) 的返回值是 c 的引用,所以 Add 栈帧销毁后,会去访问 c 位置空间。
② 如果 Add 函数栈帧销毁,清理空间,那么取 c 值的时候取到的就是随机值,给 ret 就是随机值,当前这个取决于编译器实现了。VS 下销毁栈帧,是不清空间数据的。

![]() 既然不清空间数据,那还担心什么呢?
既然不清空间数据,那还担心什么呢?
💭 我们来看看下面这种情况:
#include <iostream>
using namespace std;
int& Add(int a, int b) {
int c = a + b;
return c;
}
int main(void)
{
int& ret = Add(1, 2);
cout << ret << endl;
Add(10, 20);
cout << ret << endl; // 这里ret变成30了
return 0;
}🚩 运行结果:
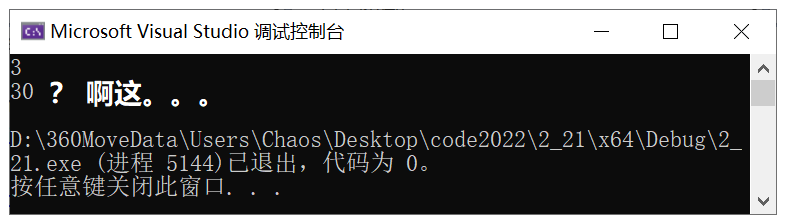
![]()
🔑 解读:我们并没有动 ret,但是 ret 的结果变成了 30,因为栈帧被改了。
当再次调用 Add 时,这块栈帧的所有权就不是你的了。
我函数销毁了,栈帧就空出来了,新的函数覆盖了之前那个已经销毁的栈帧,

![]() 所以 ret 的结果变成 30 了。
所以 ret 的结果变成 30 了。
![]()
![]() 似乎还是不太好理解,为了加深印象,我举个形象(奇葩)的例子:
似乎还是不太好理解,为了加深印象,我举个形象(奇葩)的例子:
其实,操作系统对内存空间的管理就像是房东一样。
我们使用的内存就好比是找房东租房子一样。
建立栈帧,函数调用完成后,把房子还给房东了。
但是你偷偷地把行李箱留在了房间里,
如果恰好没有人来住这个房间,你去取这个行李箱时完全没有问题的。
但是如果有人住了,新的租客没动你的行李箱,也不会有问题。
就怕这个新租客把你放在这的行李箱给丢了,甚至直接把你的行李箱占为己有了。
把你里面的衣服(数据)都给扔了,还把自己臭袜子放进去了。
这时你再回去取你的行李箱,取到的也只有臭袜子了,也不是你的衣服了。

![]()
🤣 呼呼啦啦说一大堆,结论就是:不要轻易使用引用返回!
❓ 那引用返回有什么存在的意义呢?等我们后面讲完类和对象后再细说。
🔺 总结:
日常当中是不建议用引用返回的,如果函数返回时,出了函数的作用域,
如果返回对象还未还给操作系统,则可以使用引用返回,如果已经还给操作系统了,
就不要用引用返回了,老老实实传值返回就行了。

![]() 通俗点说就是 —— 看返回对象还在不在栈帧内,在的话就可以使用引用返回。
通俗点说就是 —— 看返回对象还在不在栈帧内,在的话就可以使用引用返回。
💬 举个例子:静态变量,全局变量,出了作用域不会销毁
int& Count() {
static int n = 0;
n++;
// ...
return n;
}📌 注意事项:临时变量具有常性
#include <iostream>
#define N 10
using namespace std;
int& At(int i) {
static int arr[N];
return arr[i]; // 返回的是数组的第i个的引用(别名)
}
int main(void)
{
// 写
for (size_t i = 0; i < N; i++) {
At(i) = 10 + i; // 依次给 11 12 13 14…… 给 At
}
// 读
for (size_t i = 0; i < N; i++) {
cout << At(i) << " "; // 获取值,但是只是打印
}
cout << endl;
return 0;
}🚩 运行结果如下:

![]()
具有常性,临时变量是右值(不可被修改),可以读但不能修改。

![]()
Ⅲ. 关于引用的探讨
0x00 比较传值和传引用的效率

![]()
❓ 那传值返回和传引用返回的区别是什么呢?
💡 传引用返回速度更快。
📚 以值作为参数或者返回值类型,在传参和返回期间, 函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝。
因此值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
传值和传引用的效率比较:
#include <iostream>
#include <time.h>
using namespace std;
struct S {
int arr[10000];
};
void CallByValue(S a) {
;
}
void CallByReference(S& a) {
;
}
void TimeCompare() {
S s1;
/* 以值作为函数参数 */
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++) {
CallByValue(s1);
}
size_t end1 = clock();
/* 以引用作为函数参数 */
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++) {
CallByReference(s1);
}
size_t end2 = clock();
/* 计算两个函数运行结束后的时间 */
cout << "Call by Value: " << end1 - begin1 << endl;
cout << "Call By Reference: " << end2 - begin2 << endl;
}
int main(void)
{
TimeCompare();
return 0;
}🚩 运行结果:

![]()
值和引用作为返回值类型的性能对比:
💬 记录起始时间和结束时间,从而计算出两个函数完成之后的时间。
#include <iostream>
#include <time.h>
using namespace std;
struct S {
int arr[10000];
};
void ByValue(S a) {
;
}
void ReturnByReference(S& a) {
;
}
void TimeCompare() {
S s1;
/* 以值作为函数参数 */
size_t begin1 = clock();
for (size_t i = 0; i < 100000; i++) {
ByValue(s1);
}
size_t end1 = clock();
/* 以引用作为函数参数 */
size_t begin2 = clock();
for (size_t i = 0; i < 100000; i++) {
ReturnByReference(s1);
}
size_t end2 = clock();
/* 计算两个函数运行结束后的时间 */
cout << "Return By Value: " << end1 - begin1 << endl;
cout << "Return By Reference: " << end2 - begin2 << endl;
}
int main(void)
{
TimeCompare();
return 0;
}🚩 运行结果如下:

![]()

![]() 传值返回会创建临时变量,每次会拷贝 40000 byte。
传值返回会创建临时变量,每次会拷贝 40000 byte。
而传引用返回没有拷贝,所以速度会快很多很多,因为是全局变量所以栈帧不销毁。
所以这种场景我们就可以使用传引用返回,从而提高程序的运行效率。
🔺 总结:传值和船只真在作为传参以及返回值类型上效率相差十分悬殊。
引用的作用主要体现在传参和传返回值:
① 引用传参和传返回值,有些场景下面,可以提高性能(大对象 + 深拷贝对象)。
② 引用传参和传返回值,输出型参数和输出型返回值。
有些场景下面,形参的改变可以改变实参。
有些场景下面,引用返回,可以减少拷贝、改变返回对象。(了解一下,后面会学)
引用后面用的非常的多!非常重要!
0x01 引用和指针的区别
在语法概念上:引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
![]()
但是在底层的实现上:实际上是有空间的,因为引用是按照指针方式来实现的。
#include <iostream>
#include <time.h>
using namespace std;
int main(void)
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}🔍 我们来看看引用和指针的汇编代码对比:

![]()
0x02 指针和引用的不同点
总结 ❌ 整活 ✅
① 引用概念上定义一个变量的别名,而指针是存储一个变量的地址。
② 引用在定义时必须初始化,指针最好初始化,但是不初始化也不会报错。
int a = 0;
int& ra; ❌ 必须初始化!
int* pa; ✅ 可以不初始化③ 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型的实体。
④ 有空指针,但是没有空引用。

![]()
⑤ 在 sizeof 中含义不同,引用结果为引用类型的大小,但指针始终是地址空间所占字节数(64位平台下占8个字节)
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
int& ra = a;
int* pa = &a;
cout << sizeof(ra) << endl;
cout << sizeof(pa) << endl;
return 0;
}🚩 运行结果如下:(本机为64位环境)

![]()
⑥ 引用++即引用的实体增加1,指针++即指针向后偏移一个类型的大小。
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
int& ra = a;
int* pa = &a;
cout << "ra加加前:" << ra << endl;
ra++;
cout << "ra加加后:" << ra << endl;
cout << "pa加加前:" << pa << endl;
pa++;
cout << "pa加加后:" << pa << endl;
return 0;
}
🚩 运行结果如下:
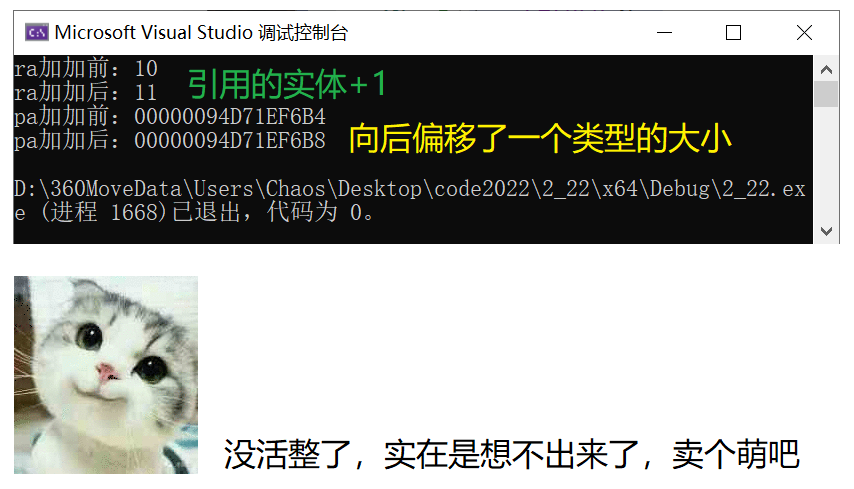
![]()
⑦ 有多级指针,但是没有多级引用。

![]()
⑧ 访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
int& ra = a;
int* pa = &a;
cout << ra << endl; // 引用直接是编译器自己处理,即取即用。
cout << *pa << endl; // 指针得加解引用操作符*,才能取到。
return 0;
}🚩 运行结果如下:
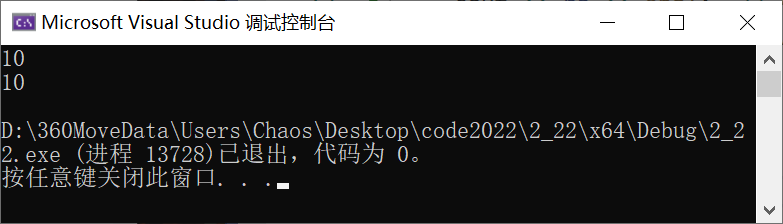
![]()
⑨ 引用比指针使用起来相对更加安全。

![]()
🔺 总结:指针使用起来更复杂一些,更容易出错一些。(指针和引用的区别,面试经常考察)
使用指针有考虑空指针,野指针等等问题,指针太灵活了,所以相对而言没有引用安全!

![]()
Ⅳ. 常引用
0x00 常引用的概念

![]() 如果既要利用引用来提高程序的效率,又想要保护传递给函数的数据不能在函数中被改变,就应使用常引用。
如果既要利用引用来提高程序的效率,又想要保护传递给函数的数据不能在函数中被改变,就应使用常引用。
📜 语法:const 数据类型& 引用名 = 引用实体;
一共有三种情况:分别是权限的放大、保持权限不变、权限的缩小。
0x01 权限的放大
💬 下面是一个引用的例子:
int main(void)
{
int a = 10;
int& ra = a;
return 0;
}💬 如果对引用实体使用 const 修饰,直接引用会导致报错:
int main(void)
{
const int a = 10;
int& ra = a;
return 0;
}🚩 运行结果如下:(报错)

![]()
🔑 分析:导致这种问题的原因是,我本身标明了 const,这块空间上的值不能被修改。
我自己都不能修改,你 ra 变成我 a 的引用,意味着你 ra 可以修改我的 a,
这就是属于权限的放大问题,a 是可读的,你 ra 要变成可读可写的,当然不行。
这要是能让你随随便便修改,那我岂不是 const 了个寂寞?

![]() 这合理吗?这不合理!
这合理吗?这不合理!
❓ 那么如何解决这样的问题,我们继续往下看。
0x02 保持权限的一致

![]() 既然引用实体用了 const 进行修饰,我直接引用的话属于权限的放大,
既然引用实体用了 const 进行修饰,我直接引用的话属于权限的放大,
我们可以给引用前面也加上 const,让他们的权限保持不变。
💬 给引用前面加上 const:
int main(void)
{
const int a = 10;
const int& ra = a;
return 0;
}🔑 解读:const int& ra = a 的意思就是,我变成你的别名,但是我不能修改你。
这样 a 是可读不可写的,ra 也是可读不可写的,这样就保持了权限的不变。
如果我们想使用引用,但是不希望它被修改,我们就可以使用常引用来解决。
0x03 权限的缩小

![]() 如果引用实体并没有被 const 修饰,是可读可写的,但是我希望它的引用不能修改它,我们可以用常引用来解决。
如果引用实体并没有被 const 修饰,是可读可写的,但是我希望它的引用不能修改它,我们可以用常引用来解决。
💬 a 是可读可写的,但是我限制 ra 是可读单不可写:
int main(void)
{
int a = 10;
const int& ra = a;
return 0;
}🔑 解读:这当然是可以的,这就是权限的缩小。
举个例子,就好比你办身份证,你的本名是可以印在身份证上的,
但是你的绰号可以印在身份证上吗?

![]()
所以就需要加以限制,你的绰号可以被人喊,但是不能写在身份证上。

![]() 所以,权限的缩小,你可以理解为是一种自我的约束。
所以,权限的缩小,你可以理解为是一种自我的约束。
0x04 常引用的应用
💬 举个例子:

![]() 假设 x 是一个大对象,或者是后面学的深拷贝的对象
假设 x 是一个大对象,或者是后面学的深拷贝的对象
那么尽量用引用传参,以减少拷贝。
如果 Func 函数中不需要改变 x,那么这里就尽量使用 const 引用传参。
void Func(int& x) {
cout << x << endl;
}
int main(void)
{
const int a = 10;
int b = 20;
Func(a); // ❌ 报错,涉及权限的放大
Func(b); // 权限是一致的,没问题
return 0;
}加 const 后,让权限保持一致:
void Func(const int& x) {
cout << x << endl;
}
int main(void)
{
const int a = 10;
int b = 20;
Func(a); // 权限是一致的
Func(b); // 权限的缩小
return 0;
}
🔑 解读:如此一来,a 是可读不可写的,传进 Func 函数中也是可读不可写的,
就保持了权限的一致了。b 是可读可写的,刚才形参还没使用 const 修饰之前,
x 是可读可写的,但是加上 const 后,属于权限的缩小,x 就是可读但不可写的了。
常引用后期会用的比较多,现在理解的不深刻也没关系,早晚的事情。
后面讲类和对象的时候会反复讲的,印象会不断加深的。
0x05 带常性的变量的引用
💬 先看代码:
int main(void)
{
double d = 3.14;
int i = d;
return 0;
}
![]()
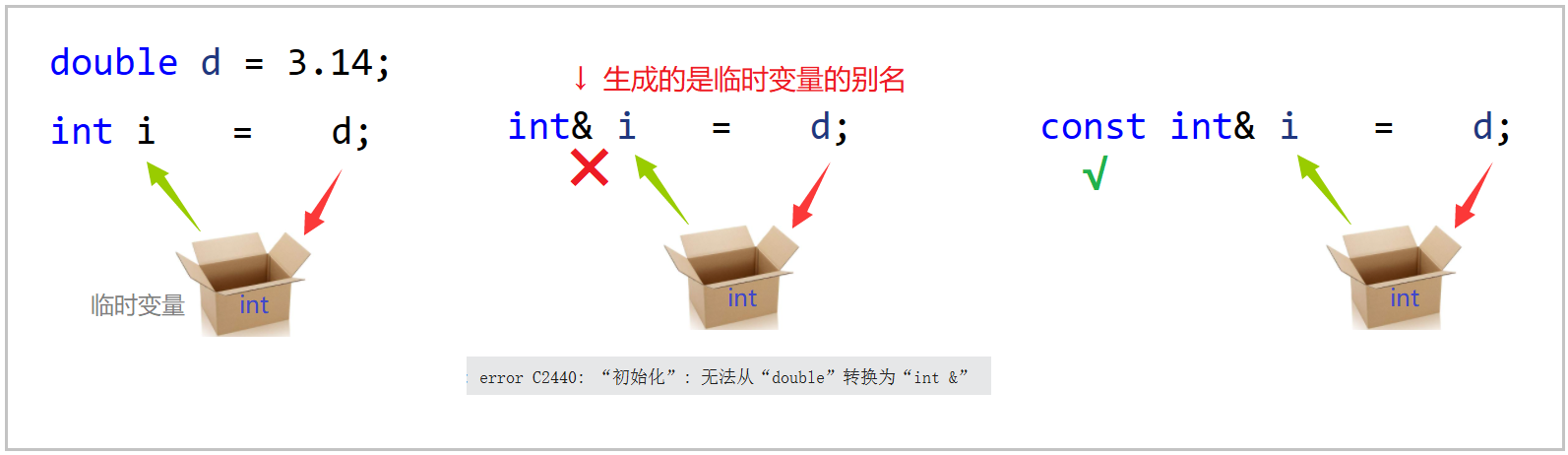
![]() 这里的 d 是可以给 i 的,这个在C语言里面叫做 隐式类型转换 。
这里的 d 是可以给 i 的,这个在C语言里面叫做 隐式类型转换 。
它会把 d 的整型部分给 i,浮点数部分直接丢掉。
❓ 但是我在这里加一个引用呢?
int main(void)
{
double d = 3.14;
int& i = d; // 我能不能用i去引用d呢?
return 0;
}🚩 运行结果:(报错)
直接用 i 去引用 d 是会报错的,思考下是为什么?
这里可能有的朋友要说,d 是浮点型,i 是整型啊,会不会是因为类型不同导致的?

![]() 但是奇葩的是,如果我在它前面加上一个 const 修饰,却又不报错了,这又是为什么?
但是奇葩的是,如果我在它前面加上一个 const 修饰,却又不报错了,这又是为什么?
int main(void)
{
double d = 3.14;
const int& i = d; // ??? 又可以了
return 0;
}
![]() 哎它* *滴!const,const 为什么行!!!
哎它* *滴!const,const 为什么行!!!
🔑 解析:因为 临时变量具有常性,不能被修改。
隐式类型转换不是直接发生的,而是现在中间产生一个临时变量。
是先把 d 给了临时变量,然后再把东西交给 i 的:
![]()
如果这里用了引用,生成的是临时变量的别名,
又因为临时变量是一个右值,是不可以被修改的,所以导致了报错。
🔺 结论:如果引用的是一个带有常性的变量,就要用带 const 的引用。
0x06 常引用做参数

![]() 使用引用传参,如果函数中不改变参数的值,建议使用 const&
使用引用传参,如果函数中不改变参数的值,建议使用 const&
💬 举个例子:
一般栈的打印,是不需要改变参数的值的,这里就可以加上 const
void StackPrint(const struct Stack& st) {...}const 数据类型& 可以接收各种类型的对象。
使用 const 的引用好处有很多,如果传入的是 const 对象,就是权限保持不变;
普通的对象,就是权限的缩小;中间产生临时变量,也可以解决。
因为 const 引用的通吃的,它的价值就在这个地方,如果不加 const 就只能传普通对象。

![]()

![]() 谢谢你读到这里!
谢谢你读到这里!
参考资料:
Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. .
百度百科[EB/OL]. []. https://baike.baidu.com/.
比特科技. C++[EB/OL]. 2021[2021.8.31]. .
程序员面试宝典[M]. 5. .
📌 笔者:王亦优
📃 更新: 2022.2.28(修正版本)
❌ 勘误:暂无
📜 声明: 由于作者水平有限,本文有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!
本章完。

- 点赞
- 收藏
- 关注作者
评论(0)