Docker NS详解

Docker底层原理
一 背景
1.1 容器与虚拟化
Container(容器)是一种轻量级的虚拟化技术,它不需要模拟硬件创建虚拟机。在Linux系统里面,使用到Linux kernel的cgroups,namespace(ipc,network, user,pid,mount),capability等用于隔离运行环境和资源限制的技术,我们称之为容器。
容器技术早就出现。例如Solaris Zones 和 BSD jails 就是非 Linux 操作系统上的容器,而用于 Linux 的容器技术也有很多如 Linux-Vserver、OpenVZ 和 FreeVPS。虽然这些技术都已经成熟,但是这些解决方案还没有将它们的容器支持集成到主流 Linux 内核。总的来说,容器不等同于Docker,容器更不是虚拟机。
LXC项目由一个 Linux 内核补丁和一些 userspace 工具组成,它提供一套简化的工具来维护容器,用于虚拟环境的环境隔离、资源限制以及权限控制。LXC有点类似chroot,但是它比chroot提供了更多的隔离性。
Docker最初目标是做一个特殊的LXC的开源系统,最后慢慢演变为它自己的一套容器运行时环境。Docker基于Linux kernel的CGroups,Namespace,UnionFileSystem等技术封装成一种自定义的容器格式,用于提供一整套虚拟运行环境。毫无疑问,近些年来Docker已经成为了容器技术的代名词,如其官网介绍的Docker is world’s leading software containerization platform。本文会先简单介绍Docker基础概念,然后会分析下Docker背后用到的技术。

二 namespace
namespace隔离:
- IPC:主机名及域名,CLONE_NEWIPC
- MNT:挂载点,文件系统
- NET:网络设备,网络协议栈,端口等
- PID:进程编号
- USER:用户和组
- UTS:主机名及域名,CLONE_NEWUTS
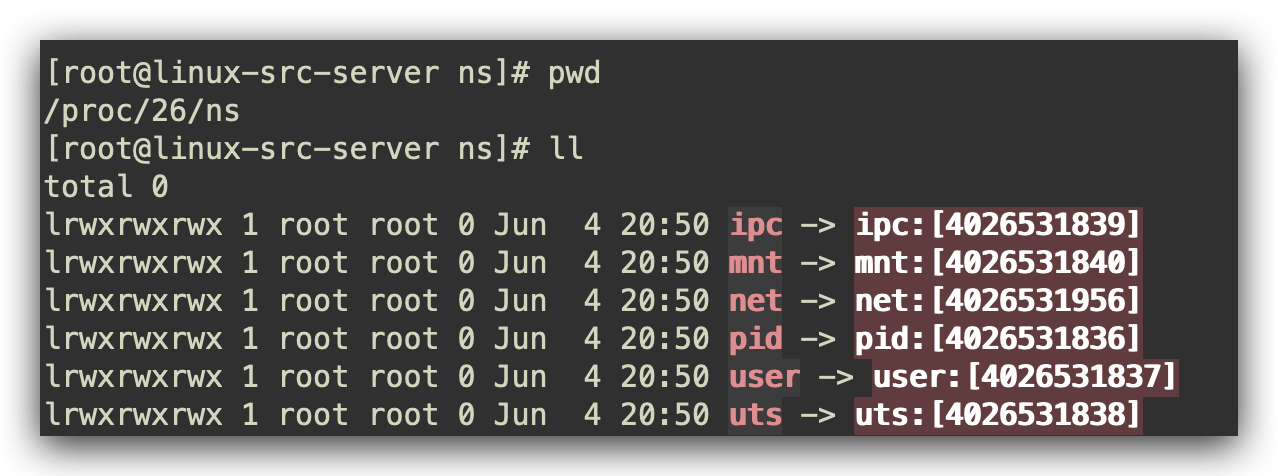

2.1 PID Namespace
在容器中,有自己的Pid namespace,因此我们看到的只有PID为1的初始进程以及它的子进程,而宿主机的其他进程容器内是看不到的。通常来说,Linux启动后它会先启动一个PID为1的进程,这是系统进程树的根进程,根进程会接着创建子进程来初始化系统服务。PID namespace允许在新的namespace创建一棵新的进程树,它可以有自己的PID为1的进程。在PID namespace的隔离下,子进程名字空间无法知道父进程名字空间的进程,如在Docker容器中无法看到宿主机的进程,而父进程名字空间可以看到子进程名字空间的所有进程。如图所示:

2.2 NS Namespace
NS Namespace用于隔离挂载点,不同NS Namespace的挂载点互不影响。创建一个新的Mount Namespace效果有点类似chroot,不过它隔离的比chroot更加完全。这是历史上的第一个Linux Namespace,由此得到了 NS 这个名字而不是用的 Mount。
在最初的NS Namespace版本中,挂载点是完全隔离的。初始状态下,子进程看到的挂载点与父进程是一样的。在新的Namespace中,子进程可以随意mount/umount任何目录,而不会影响到父Namespace。使用NS Namespace完全隔离挂载点初衷很好,但是也带来了某些情况下不方便,比如我们新加了一块磁盘,如果完全隔离则需要在所有的Namespace中都挂载一遍。为此,Linux在2.6.15版本中加入了一个shared subtree特性,通过指定Propagation来确定挂载事件如何传播。比如通过指定MS_SHARED来允许在一个peer group(子namespace 和父namespace就属于同一个组)共享挂载点,mount/umount事件会传播到peer group成员中。使用MS_PRIVATE不共享挂载点和传播挂载事件。其他还有MS_SLAVE和NS_UNBINDABLE等选项。可以通过查看cat /proc/self/mountinfo来看挂载点信息,若没有传播参数则为MS_PRIVATE的选项。

2.3 NET Namespace
Docker容器中另一个重要特性是网络独立(之所以不用隔离一词是因为容器的网络还是要借助宿主机的网络来通信的),使用到Linux 的 NET Namespace以及vet。veth主要的目的是为了跨NET namespace之间提供一种类似于Linux进程间通信的技术,所以veth总是成对出现,如下面的veth0和veth1。它们位于不同的NET namespace中,在veth设备任意一端接收到的数据,都会从另一端发送出去。veth实现了不同namespace的网络数据传输。

在Docker中,宿主机的veth端会桥接到网桥中,接收到容器中的veth端发过来的数据后会经由网桥docker0再转发到宿主机网卡eth0,最终通过eth0发送数据。当然在发送数据前,需要经过iptables MASQUERADE规则将源地址改成宿主机ip,这样才能接收到响应数据包。而宿主机网卡接收到的数据会通过iptables DNAT根据端口号修改目的地址和端口为容器的ip和端口,然后根据路由规则发送到网桥docker0中,并最终由网桥docker0发送到对应的容器中。
Docker里面网络模式分为bridge,host,overlay等几种模式,默认是采用bridge模式网络如图所示。如果使用host模式,则不隔离直接使用宿主机网络。overlay网络则是更加高级的模式,可以实现跨主机的容器通信,后面会单独总结下Docker网络这个专题。
2.4 USER Namespace
user namespace用于隔离用户和组信息,在不同的namespace中用户可以有相同的 UID 和 GID,它们之间互相不影响。父子namespace之间可以进行用户映射,如父namespace(宿主机)的普通用户映射到子namespace(容器)的root用户,以减少子namespace的root用户操作父namespace的风险。user namespace功能虽然在很早就出现了,但是直到Linux kernel 3.8之后这个功能才趋于完善。
创建新的user namespace之后第一步就是设置好user和group的映射关系。这个映射通过设置/proc/PID/uid_map(gid_map)实现,格式如下,ID-inside-ns是容器内的uid/gid,而ID-outside-ns则是容器外映射的真实uid/gid。比如0 1000 1表示将真实的uid=1000映射为容器内的uid=0,length为映射的范围。
ID-inside-ns ID-outside-ns length
不是所有的进程都能随便修改映射文件的,必须同时具备如下条件:
- 修改映射文件的进程必须有PID进程所在user namespace的CAP_SETUID/CAP_SETGID权限。
- 修改映射文件的进程必须是跟PID在同一个user namespace或者PID的父namespace。
- 映射文件uid_map和gid_map只能写入一次,再次写入会报错。
docker1.10之后的版本可以通过在docker daemon启动时加上–userns-remap=[USERNAME]来实现USER Namespace的隔离。我们指定了username=ssj启动dockerd,查看subuid文件可以发现ssj映射的uid范围是165536到165536+65536= 231072,而且在docker目录下面对应ssj有一个独立的目录165536.165536存在。
2.5 其他Namespace
UTS namespace用于隔离主机名等。可以看到在新的uts namespace修改主机名并不影响原namespace的主机名。
IPC Namespace用于隔离IPC消息队列等。可以看到,新老ipc namespace的消息队列互不影响。
CGROUP Namespace是Linux4.6以后才支持的新namespace。容器技术使用namespace和cgroup实现环境隔离和资源限制,但是对于cgroup本身并没有隔离。没有cgroup namespace前,容器中一旦挂载cgroup文件系统,便可以修改整全局的cgroup配置。有了cgroup namespace后,每个namespace中的进程都有自己的cgroup文件系统视图,增强了安全性,同时也让容器迁移更加方便。在我测试的Docker18.03.1-ce版本中容器暂时没有用到cgroup namespace,这里就不再展开。
三 CGroups
Linux CGroups用于资源限制,包括限制CPU、内存、blkio以及网络等。通过工具cgroup-bin (sudo apt-get install cgroup-bin)可以创建CGroup并进入该CGroup执行命令。
cpu.cfs_period_us 和 cpu.cfs_quota_us,它们分别用来限制该组中的所有进程在单位时间里可以使用的 cpu 时间,这里的 cfs(Completely Fair Scheduler) 是完全公平调度器的意思。cpu.cfs_period_us是时间周期,默认为100000,即100毫秒。而cpu.cfs_quota_us是在时间周期内可以使用的时间,默认为-1即无限制。cpu.shares用于限制cpu使用的,它用于控制各个组之间的配额。比如组cg1的cpu.shares为1024,组cg2的cpu.shares也是1024,如果都有进程在运行则它们都可以使用最多50%的限额。如果cg2组内进程比较空闲,那么cg1组可以将使用几乎整个cpu,tasks存储的是该组里面的进程ID。(注:debian8默认没有cfs和memory cgroup支持,需要重新编译内核及修改启动参数,debian9默认已经支持)
四 Capabilities
我们在启动容器时会时常看到这样的参数–cap-add=NET_ADMIN,这是用到了Linux的capability特性。capability是为了实现更精细化的权限控制而加入的。我们以前熟知通过设置文件的SUID位,这样非root用户的可执行文件运行后的euid会成为文件的拥有者ID,比如passwd命令运行起来后有root权限,有SUID权限的可执行文件如果存在漏洞会有安全风险。(查看文件的capability的命令为 filecap -a,而查看进程capability的命令为 pscap -a,pscap和filecap工具需要安装 libcap-ng-utils这个包)。
五 Union File System
UnionFS(联合文件系统)简单来说就是支持将不同的目录挂载到同一个目录中的技术。Docker支持的UnionFS包括OverlayFS,AUFS,devicemapper,vfs以及btrfs等,查看UnionFS版本可以用docker info查看对应输出中的Storage项即可,早期的Docker版本用AUFS和devicemapper居多,新版本Docker在Linux3.18之后版本基本默认用OverlayFS,这里以OverlayFS来分析。
OverlayFS与早期用过的AUFS类似,不过它比AUFS更简单,读写性能更好,在docker-ce18.03版本中默认用的存储驱动是overlay2,老版本overlay官方已经不推荐使用。它将两个目录upperdir和lowdir联合挂载到一个merged目录,提供统一视图。其中upperdir是可读写层,对容器修改写入在该目录中,它也会隐藏lowerdir中相同的文件。而lowdir是只读层,Docker镜像在这层。
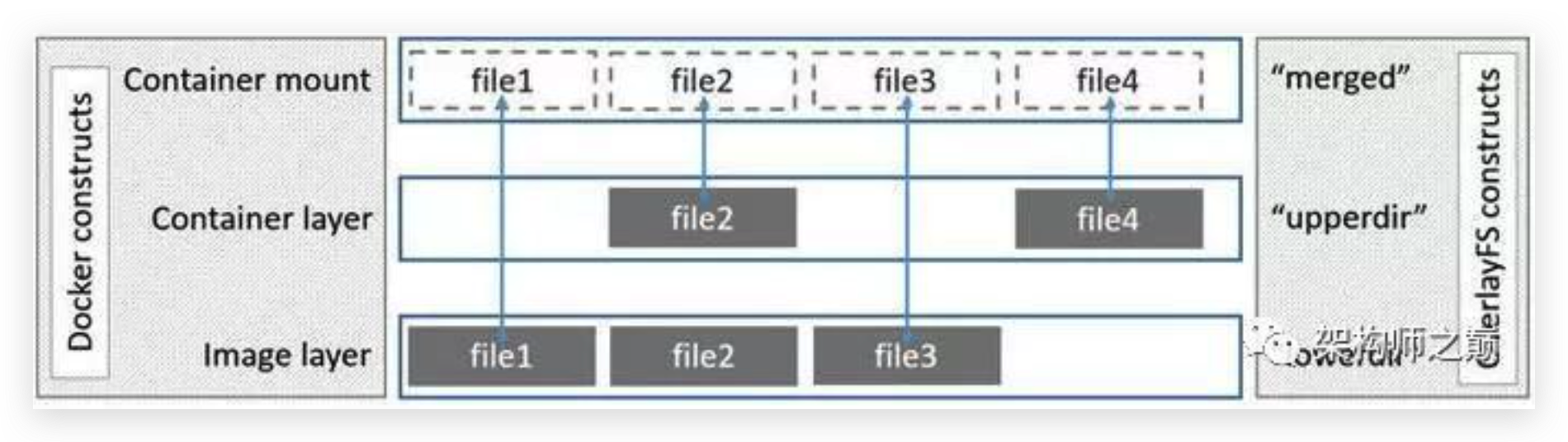
- 读取文件时,如果upperdir不存在该文件,则会从lowerdir直接读取。
- 修改文件时并不影响lowerdir中的文件,因为它是只读的。
- 如果修改的文件在upperdir不存在,则会从lowerdir拷贝到upperdir,然后在upperdir里面修改该文件,并不影响lowerdir目录的文件。
- 删除文件则是将upperdir中将对应文件设置成了c类型,即字符设备类型来隐藏已经删除的文件(与AUFS创建一个whiteout文件略有不同)。
回到Docker里面,我们拉取一个nginx镜像,有三层镜像,可以看到在overlay2对应每一层都有个目录(注意,这个目录名跟镜像层名从docker1.10版本后名字已经不对应了),另外的l目录是指向镜像层的软链接。最底层存储的是基础镜像debian/alpine,上一层是安装了nginx增加的可执行文件和配置文件,而最上层是链接/dev/stdout到nginx日志文件。而每个子目录下面的diff目录用于存储镜像内容,work目录是OverlayFS内部使用的,而link文件存储的是该镜像层对应的短名称,lower文件存储的是下一层的短名称。
此时我们启动一个nginx容器,可以看到overlay2目录多了两个目录,多出来的就是容器层的目录和只读的容器init层。容器目录下面的merged就是我们前面提到的联合挂载目录了,而lowdir则是它下层目录。而容器init层用来存储与这个容器内环境相关的内容,如 /etc/hosts和/etc/resolv.conf文件,它居于其他镜像层之上,容器层之下。
如果我们在容器中修改文件,则会反映到容器层的merged目录相关文件,容器层的diff目录相当于upperdir,其他层是lowerdir。如果之前容器层diff目录不存在该文件,则会拷贝该文件到diff目录并修改。读取文件时,如果upperdir目录找不到,则会直接从下层的镜像层中读取。

- 点赞
- 收藏
- 关注作者
评论(0)