【进阶篇】全流程学习《20天掌握Pytorch实战》纪实 | Day01 | 结构化数据建模流程范例

开源自由,知识无价~
🤗前言:torch安装
由于我是在PyCharm中进行实验的,所以需要自行安装torch的库,和其他的库安装一样,直接在Terminal中pip就OK了。
pip install torchpip install torchvision
整个安装过程可能有点慢,包也比较大,耐心等待即可。
如果是使用Jupyter notebook的同学,可以直接使用。(mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量)
😁概览

一、🎉准备数据
import os
import datetime
# 打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间
print("\n"+"=========="*8 + "%s" % nowtime)
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
printbar()
首先,有一段打印时间的程序,用到了内置的系统库(os、datetime)来获取时间信息。
- 正式准备数据
Titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。
结构化数据一般会使用Pandas中的DataFrame进行预处理。
Titanic数据集:RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。这场轰动的悲剧震撼了国际社会,并导致了更好的船舶安全条例。
海难导致生命损失的原因之一是
没有足够的救生艇给乘客和机组人员。虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
在这个挑战中,我们要求你完成对哪些人可能生存的分析。特别是,我们要求您运用机器学习的工具来预测哪些乘客幸免于难。
下面是根据文档中的代码,导入Titanic数据集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
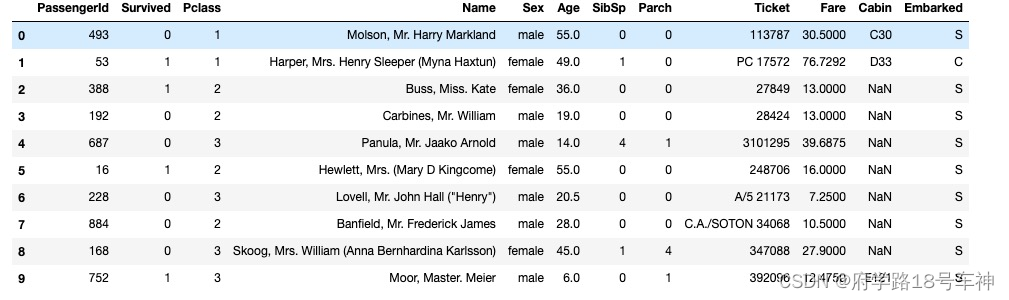
dftrain_raw = pd.read_csv('./data/titanic/train.csv') # 这里注意一下自己数据集存放的路径,更改为自己的路径即可
dftest_raw = pd.read_csv('./data/titanic/test.csv')
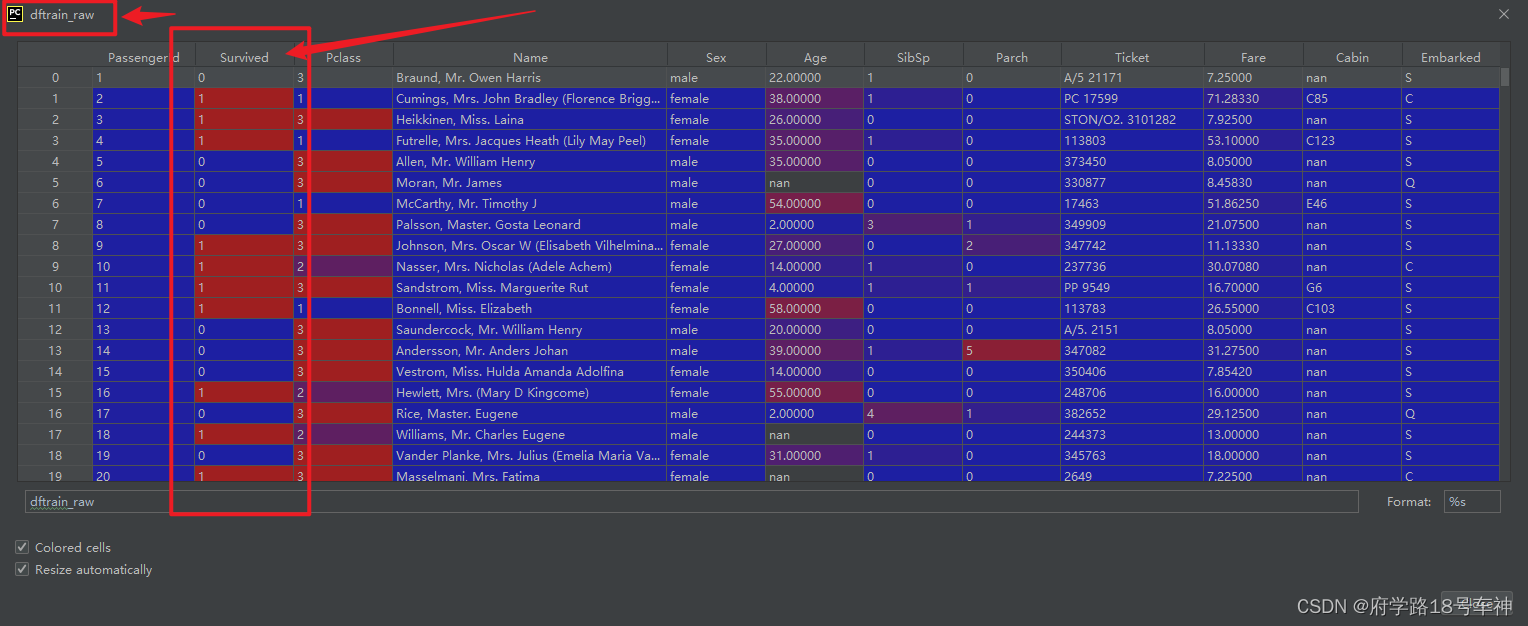
dftrain_raw.head(10)
原文档中的代码在Jupyter运行,不知道是否含有源文件,我自己下载了一个Titanic的数据集,然后存入文件夹,在运行。
- 这里也为大家提供了免费的公开Titanic数据集(本示例不能用):
链接:https://pan.baidu.com/s/1pYZQAPgtZya1h5iDzfxqOA
提取码:yyds- 文档提供的Titanic数据集(下载这个数据集):
链接:https://pan.baidu.com/s/1QSVOa6310Jv52sktb2sJug
提取码:yyds
字段说明:
- Survived:0代表死亡,1代表存活【y标签】
- Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
- Name:乘客姓名 【舍去】
- Sex:乘客性别 【转换成bool特征】
- Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
- SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
- Parch:乘客父母/孩子的个数(整数值)【数值特征】
- Ticket:票号(字符串)【舍去】
- Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
- Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
- Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
利用Pandas的数据可视化功能我们可以简单地进行探索性数据分析EDA(Exploratory Data Analysis)。
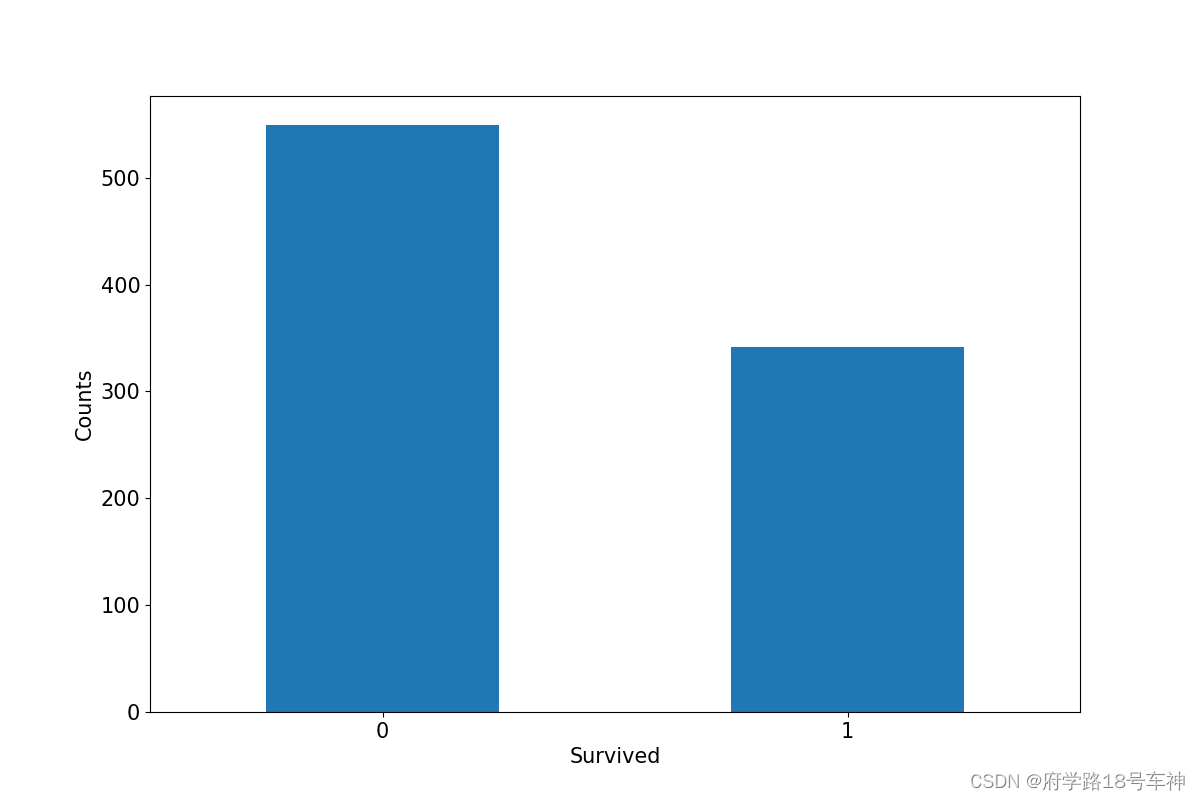
label分布情况
# %matplotlib inline
# %config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',
figsize = (12,8),fontsize=15,rot = 0) # kind:设置柱状图bar;figsize:设置图片大小;fontsize:设置文字大小;rot:旋转度
ax.set_ylabel('Counts',fontsize = 15) # 设置坐标系的y轴名称,fontsize:文字大小
ax.set_xlabel('Survived',fontsize = 15) # 设置x坐标系名称
plt.show() # 渲染出图
通过matplotlib来绘制图像,如果对于matplotlib不熟悉的同学,可以看看相关的内容,很简单,即用即学。
下面图中,可以看出,横坐标为
Survived(存活),纵坐标为Counts(人数)。死亡人数大于存活人数。
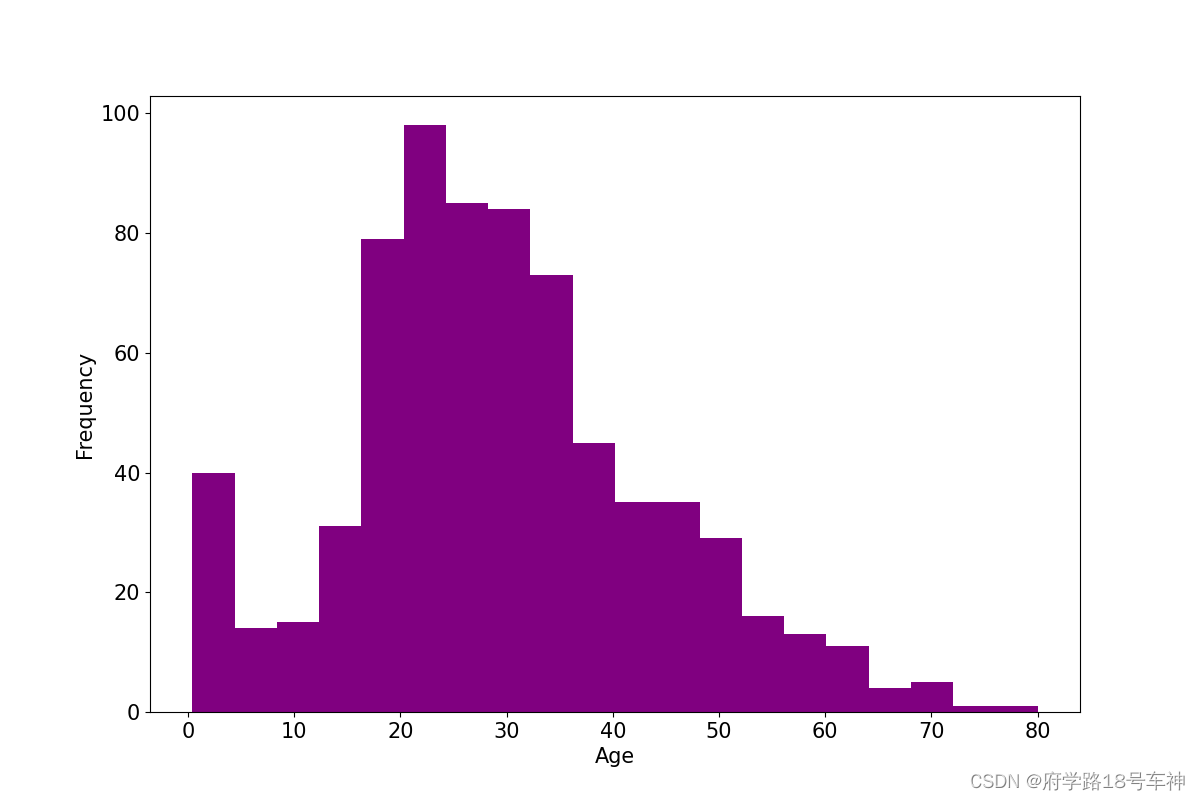
年龄分布情况
# %matplotlib inline
# %config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Age'].plot(kind = 'hist',bins = 20,color= 'purple',
figsize = (12,8),fontsize=15) # 通过修改dftrain_raw['Age']中的表头,即可获取列值,以传入绘图
ax.set_ylabel('Frequency',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()
和上面的
Survived图一样,只是导入的x和y轴不一样,图片颜色和形状我们都可以自己设定,还可以设置图例等。下面的是展现了数据集中的年龄分布情况,想这种分布,最好还是以柱状图展示,这样比较明显,颜色尽量不用太亮了,哈哈哈。
从下图可看出,整个数据集的分布,大致在20~40岁左右,类似于高斯分布(
瞎说的)。
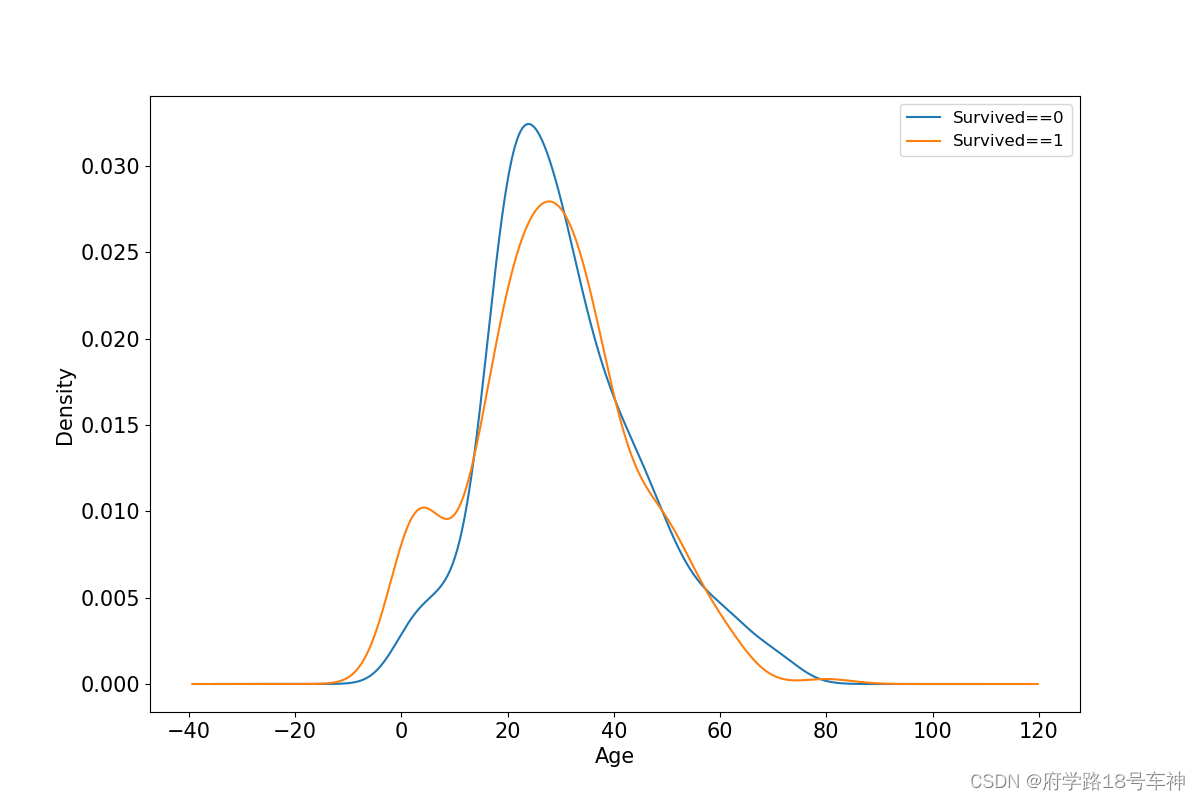
年龄和label的相关性
# %matplotlib inline
# %config InlineBackend.figure_format = 'png'
ax = dftrain_raw.query('Survived == 0')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
dftrain_raw.query('Survived == 1')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
ax.legend(['Survived==0','Survived==1'],fontsize = 12)
ax.set_ylabel('Density',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()
上面可知,分别取值存活的标签中的年龄数值,然后再使用每列的值作为x轴,并计算y值得概率密度。这样就可以看出
年龄和label的相关性了。
从计算的概率密度来看,蓝色的线(表示死亡)大致在20多岁左右比较密集,也就说明死亡的大部分为年轻人;橙色的线(存活)大致在30-40较为密集,0-10岁其次,最后是老年群体(50以上)。这也大致说明了一些人比其他人更有可能生存,比如
妇女,儿童和上层阶级。
下面为正式的数据预处理
def preprocessing(dfdata): # 数据预处理
dfresult= pd.DataFrame() # df格式化
#Pclass:乘客所持票类,有三种值(1,2,3)
dfPclass = pd.get_dummies(dfdata['Pclass']) # pandas 中的 get_dummies 方法主要用于对类别型特征做 One-Hot 编码(独热编码)。
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ] # 设置dfPclass的列
dfresult = pd.concat([dfresult,dfPclass],axis = 1) # 数据合并操作,axis: 需要合并链接的轴,0是行,1是列
#Sex:乘客性别 【转换成bool特征】
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
dfresult['Age'] = dfdata['Age'].fillna(0)
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare:乘客兄弟姐妹/配偶的个数(整数值) ,乘客父母/孩子的个数(整数值),乘客所持票的价格(浮点数,0-500不等)
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
x_train = preprocessing(dftrain_raw).values # 对训练数据预处理,并获取元素值
y_train = dftrain_raw[['Survived']].values # 获取训练数据中'Survived'特征下的元素值
x_test = preprocessing(dftest_raw).values # 对测试数据预处理,并获取元素值
y_test = dftest_raw[['Survived']].values # 获取测试数据中'Survived'特征下的元素值(此处存在Bug)
print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )
print("y_train.shape =", y_train.shape )
print("y_test.shape =", y_test.shape )
Duang~
⚡爆错~(数据集的锅)
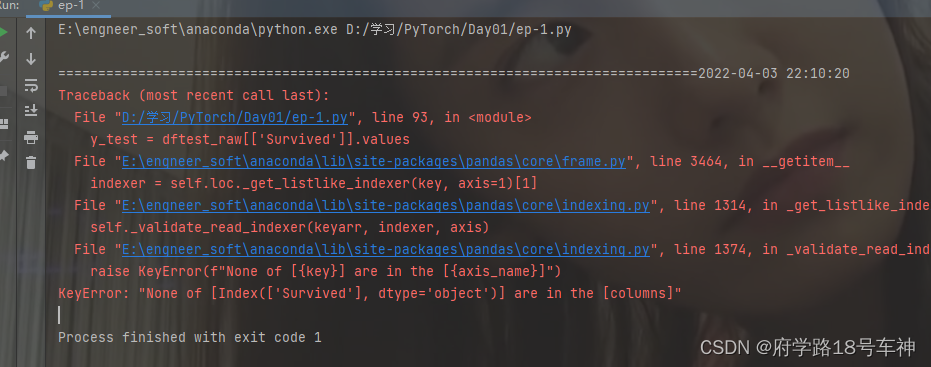
分析下爆错的原因:
KeyError: "None of [Index(['Survived'], dtype='object')] are in the [columns]"
KeyError:“没有[Index([‘幸存’],dtype=‘object’)]在[列]中”
也就是下面这条的问题
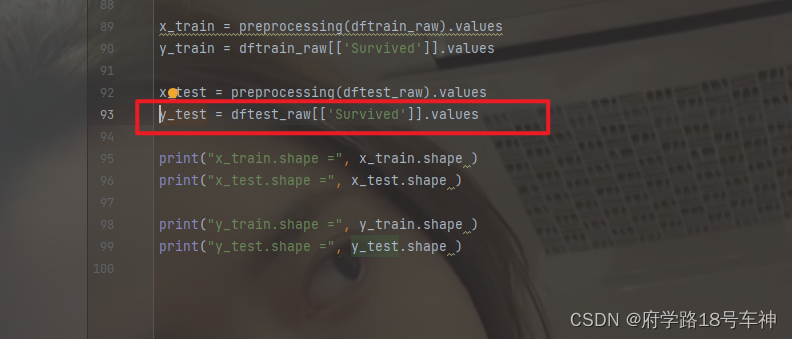
难到
dftest_raw中不包含"Survived"?我们检查一下dftest_raw的数据表,好像真的不包括"Survived"栏。
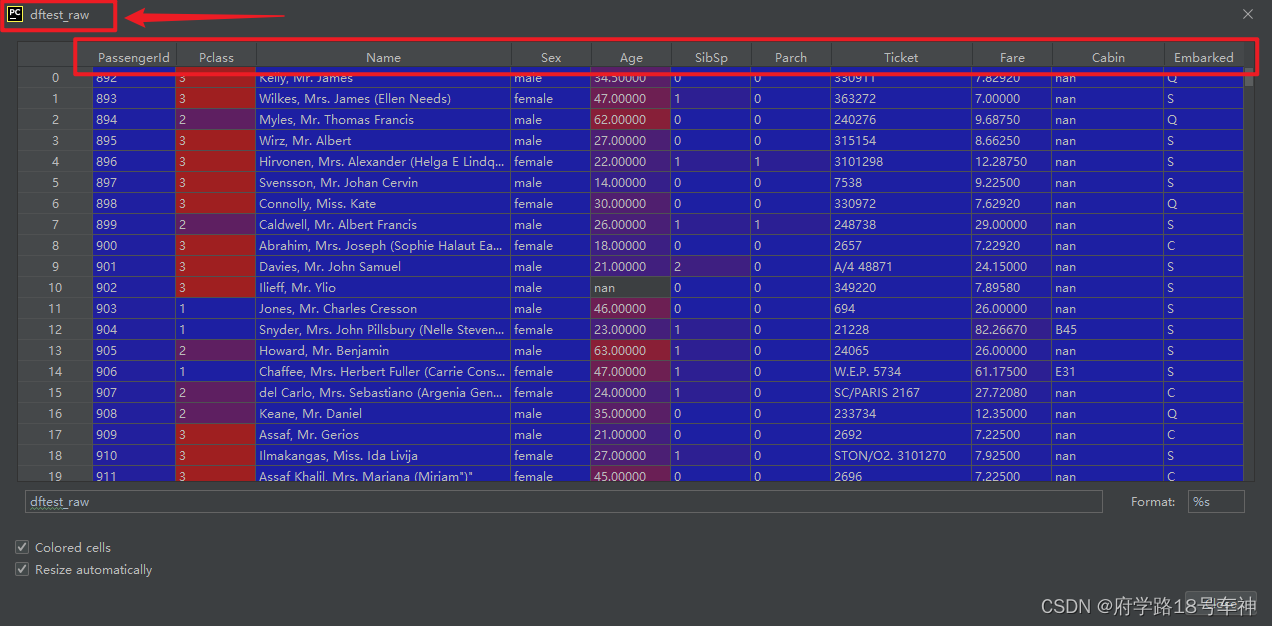
再观察一下训练数据,里面包含
"Survived"栏,我们试着修改一下代码。此刻,我在想难道是我的数据集有错,最后我查阅了很多的资料,发现,测试数据和训练数据的特征确实存在差异,所以文档作者这么写代码,我怀疑数据集是做了略微的改动的(如有误请谅解)
GitHub:https://github.com/HumbertoSubiza/Titanic/blob/master/test.csv
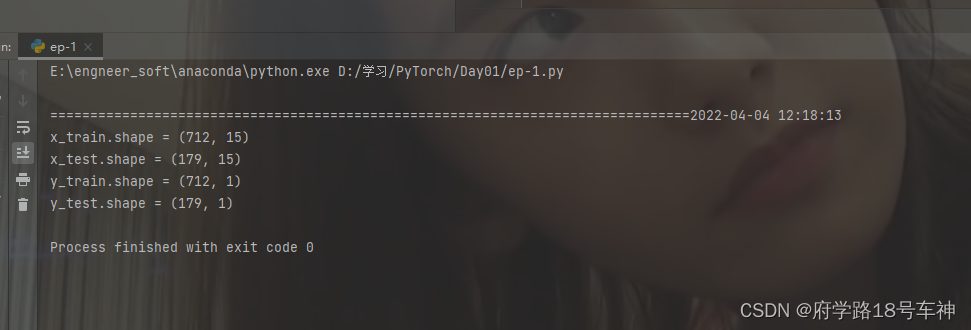
文档的输出结果是:
x_train.shape = (712, 15)
x_test.shape = (179, 15)
y_train.shape = (712, 1)
y_test.shape = (179, 1)
可以看出,
y_test.shape = (179, 1),是一个一维数据,179*1的矩阵。y矩阵应该都是特征,所以只有一列数据。但是所以的标准Titanic数据集里面都不包含"Survived"。
后来我发现作者的数据集和网上开源的缺失不一样,还是用作者提供的吧。运行完结果和文档一样
上面已经完成了数据预处理工作
- 进一步使用
DataLoader和TensorDataset封装成可以迭代的数据管道
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),
shuffle = True, batch_size = 8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),
shuffle = False, batch_size = 8)
关于
DataLoader和TensorDataset的解释:DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)
DataLoader:__init__中的几个重要的输入
| dataset | 数据集对象 |
|---|---|
| batch_size | 根据具体情况设置即可 |
| shuffle | 设置为真不会按数据顺序输出,一般在训练数据中使用 |
| collate_fn | 是用来处理不同情况下的输入dataset的封装,一般采用默认即可,除非你自定义的数据读取输出非常少见 |
| batch_sampler | 其和batch_size、shuffle等参数是互斥的,一般采用默认 |
| sampler | 从代码可以看出,其和shuffle是互斥的,一般默认即可 |
| num_workers | 设置多少个子进程可以使用,设置0表示在主进程中使用。可以加快数据导入速度 |
| pin_memory | If True, the data loader will copy tensors into CUDA pinned memory before returning them. 也就是一个数据拷贝的问题 |
| timeout | 是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错 |
| BatchSampler | 把batch size个RandomSampler类对象封装成一个,这样就实现了随机选取一个batch的目的 |
TensorDataset:TensorDataset(data_tensor, target_tensor)
- data_tensor : 需要被封装的数据样本
- target_tensor : 需要被封装的数据标签
- 关于
torch.tenor()
在Pytorch中,Tensor和tensor都用于生成新的张量
- torch.Tensor()是Python类,更明确的说,是默认张量类型torch.FloatTensor()的别名,torch.Tensor([1,2]) 会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。
- torch.tensor()仅仅是Python的函数
torch.tensor(data, dtype=None, device=None, requires_grad=False)
其中data可以是:list, tuple, array, scalar等类型。
torch.tensor()可以从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor,torch.FloatTensor,torch.DoubleTensor。
代码解释:
使用DataLoader和TensorDataset封装成可以迭代的数据管道,训练数据设置
shuffle = True,batch_size设置为8;同理,测试数据也同样的操作,先生成浮点数张量,在数据加载。
测试数据管道
for features,labels in dl_train:
print(features,labels)
break
运行后的结果,和文档一致
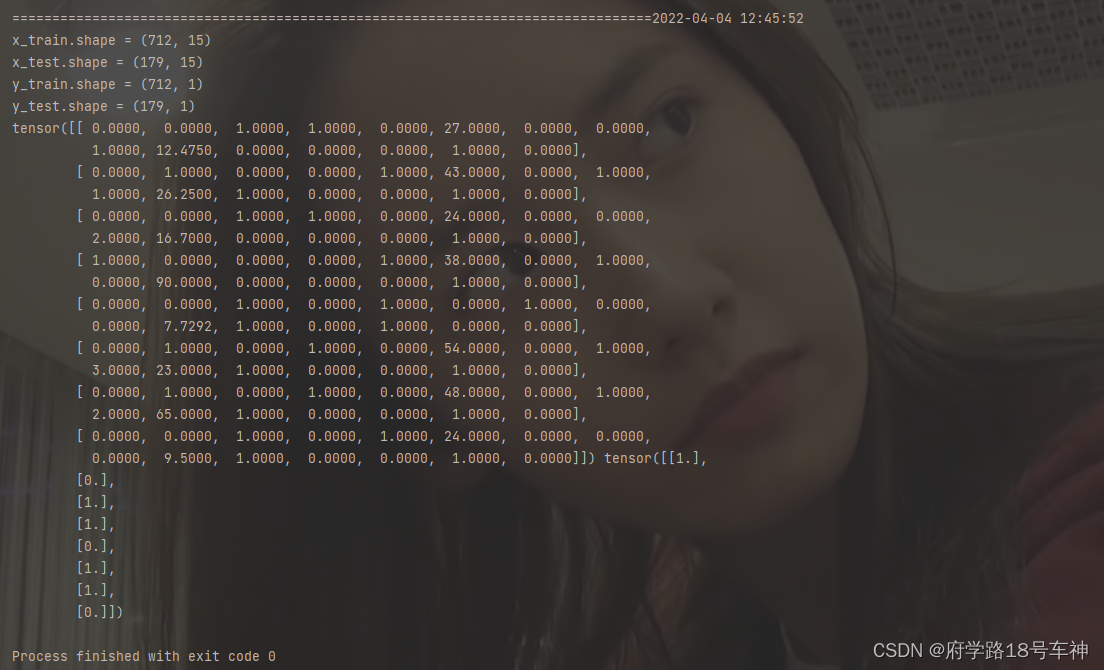
上面代码是测试生成的迭代数据管道,打印出来看。
二、🎉定义模型
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器进行封装。
此处选择使用最简单的nn.Sequential,按层顺序模型。
def create_net(): # 网络构建函数
net = nn.Sequential() # 按层顺序模型
net.add_module("linear1",nn.Linear(15,20)) # 加入线性"linear1"模型
net.add_module("relu1",nn.ReLU()) # 加入"relu1",下同加入模型
net.add_module("linear2",nn.Linear(20,15))
net.add_module("relu2",nn.ReLU())
net.add_module("linear3",nn.Linear(15,1))
net.add_module("sigmoid",nn.Sigmoid())
return net # 返回构建好的网络模型,一个添加了6个函数模型
net = create_net()
print(net)
输出:
Sequential(
(linear1): Linear(in_features=15, out_features=20, bias=True)
(relu1): ReLU()
(linear2): Linear(in_features=20, out_features=15, bias=True)
(relu2): ReLU()
(linear3): Linear(in_features=15, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
from torchkeras import summary
summary(net,input_shape=(15,))
可能在这里运行不了,需要安装库
torchkeras,直接pip即可安装
pip intall torchkeras
==这里安装遇到点小问题,就是库的搭配问题——版本不兼容,直接安装他要求的版本更新就是了==

提高一个安装指定版本的小技巧,以
numpy为例子:
pip install numpy==版本号
关于torchkeras的相关介绍:
torchkeras是在pytorch上实现的仿keras的高层次Model接口。有了它,你可以像Keras那样,对pytorch构建的模型进行summary,compile,fit,evaluate , predict五连击。一切都像行云流水般自然。听起来,torchkeras的功能非常强大。但实际上,它的实现非常简单,全部源代码不足300行。- 了解过深度学习框架的都知道,
Tensorflow是早期的主流框架,而后又出现了Keras,keras对Tensorflow进行了封装,使得搭建深度学模型的过程简化到了几个简单的步骤:summary、compile、fit、evaluate、 predict。Pytorch虽然比Tensorflow出现的晚,但是其在框架的实现方式上,更为优雅,可以很好的与Python的原生编程思维结合起来,因此越来越多的人开始转向Pytorch。开发的过程就是不断模块化的过程,Torchkeras便是这一原则下的产物,它将Pytorch进行了封装,使得利用Pytorch搭建深度学模型的过程也可以像Keras那样,并且非常的灵活。- 有个开源的学习代码可以自行了解:https://github.com/lyhue1991/torchkeras
再来看,导入的库函数summary能够查看模型的输入和输出的形状,可以更加清楚地输出模型的结构。下面给出相关解释
torchsummary.summary(model, input_size, batch_size=-1, device="cuda")
功能:查看模型的信息,便于调试:
model:pytorch 模型,必须继承自 nn.Moduleinput_size:模型输入 size,形状为 C,H ,Wbatch_size:batch_size,默认为 -1,在展示模型每层输出的形状时显示的 batch_sizedevice:“cuda"或者"cpu”
- 使用时需要注意,默认device=‘cuda’,如果是在‘cpu’,那么就需要更改。不匹配就会出现下面的错误:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
代码解读
导入
torchkeras中的summary,可以实现对构建模型的输入输出形状查看,更为直观的观测输出模型的结构。
summary(net,input_shape=(15,)),其中net为上级构建的网络模型,设置模型的输入
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 20] 320
ReLU-2 [-1, 20] 0
Linear-3 [-1, 15] 315
ReLU-4 [-1, 15] 0
Linear-5 [-1, 1] 16
Sigmoid-6 [-1, 1] 0
================================================================
Total params: 651
Trainable params: 651
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.000057
Forward/backward pass size (MB): 0.000549
Params size (MB): 0.002483
Estimated Total Size (MB): 0.003090
----------------------------------------------------------------
Process finished with exit code 0
复现结果与文档结果一致~
从结果中,可以查看一共包含的层数和类型
Layer (type)、Output Shape、Param #。以及一些输入缓存大小、反馈大小等,是在做模型训练中比较常用的操作。
三、🎉训练模型
Pytorch:通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有==3类==典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种较通用的脚本形式。
from sklearn.metrics import accuracy_score
loss_func = nn.BCELoss() # 构建损失函数
optimizer = torch.optim.Adam(params=net.parameters(),lr = 0.01) # 优化器这里使用的是Adam,另外还有比如SGD、RMSProp等等
metric_func = lambda y_pred,y_true: accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5) # 度量函数,这里利用分类准确率accuracy_score来实现
metric_name = "accuracy"
from sklearn.metrics import accuracy_score解读:
这里用到了 :
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)分类准确率分数是指所有分类正确的百分比。分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。- ==normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数==
==举例==:
>>>import numpy as np
>>>from sklearn.metrics import accuracy_score
>>>y_pred = [0, 2, 1, 3]
>>>y_true = [0, 1, 2, 3]
>>>accuracy_score(y_true, y_pred)
0.5
>>>accuracy_score(y_true, y_pred, normalize=False)
2
nn.BCELoss(). 这里讲的是默认对一个batch里面的数据做二元交叉熵并且求平均。torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='means')下面参数说明:
weight: 给每个batch元素的权重,一般没用size_average: 默认为Truereduce: True/False 默认为True,对每个minibatch做reduction: 用的比较多的是这个,若用了2.3可能导致4失效。官方解释链接:https://pytorch.org/docs/stable/nn.html?highlight=bceloss#torch.nn.BCELoss
官方示例:
>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(m(input), target)
>>> output.backward()
运行结果:
import torch.nn as nn
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
input
Out[21]: tensor([-0.6212, -0.9684, 0.6923], requires_grad=True)
target = torch.empty(3)
target
Out[23]: tensor([-1.5901e-30, 4.5907e-41, 0.0000e+00])
target = target.random_(2)
target
Out[25]: tensor([1., 0., 1.])
output = loss(m(input), target)
output
Out[27]: tensor(0.5929, grad_fn=<BinaryCrossEntropyBackward>)
下面继续模型训练:
epochs = 10
log_step_freq = 30
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name]) # 记录输出当前的训练迭代次数和损失值
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 这里用到了最初的那个代码,获取当前时间
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1,训练循环-------------------------------------------------
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features,labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播求损失
predictions = net(features)
loss = loss_func(predictions,labels)
metric = metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 2,验证循环-------------------------------------------------
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features,labels) in enumerate(dl_valid, 1):
# 关闭梯度计算
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions,labels)
val_metric = metric_func(predictions,labels)
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 3,记录日志-------------------------------------------------
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
复现运行结果如下:
Start Training...
================================================================================2022-04-04 14:13:03
[step = 30] loss: 0.631, accuracy: 0.667
[step = 60] loss: 0.644, accuracy: 0.654
EPOCH = 1, loss = 0.629,accuracy = 0.667, val_loss = 0.551, val_accuracy = 0.708
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.529, accuracy: 0.721
[step = 60] loss: 0.546, accuracy: 0.708
EPOCH = 2, loss = 0.567,accuracy = 0.711, val_loss = 0.464, val_accuracy = 0.757
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.568, accuracy: 0.704
[step = 60] loss: 0.539, accuracy: 0.731
EPOCH = 3, loss = 0.546,accuracy = 0.740, val_loss = 0.499, val_accuracy = 0.788
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.493, accuracy: 0.821
[step = 60] loss: 0.490, accuracy: 0.812
EPOCH = 4, loss = 0.508,accuracy = 0.791, val_loss = 0.466, val_accuracy = 0.772
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.530, accuracy: 0.771
[step = 60] loss: 0.488, accuracy: 0.794
EPOCH = 5, loss = 0.475,accuracy = 0.803, val_loss = 0.460, val_accuracy = 0.777
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.507, accuracy: 0.762
[step = 60] loss: 0.507, accuracy: 0.760
EPOCH = 6, loss = 0.499,accuracy = 0.765, val_loss = 0.450, val_accuracy = 0.804
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.498, accuracy: 0.792
[step = 60] loss: 0.503, accuracy: 0.787
EPOCH = 7, loss = 0.497,accuracy = 0.791, val_loss = 0.416, val_accuracy = 0.832
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.428, accuracy: 0.812
[step = 60] loss: 0.487, accuracy: 0.781
EPOCH = 8, loss = 0.475,accuracy = 0.794, val_loss = 0.433, val_accuracy = 0.799
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.435, accuracy: 0.821
[step = 60] loss: 0.441, accuracy: 0.819
EPOCH = 9, loss = 0.458,accuracy = 0.805, val_loss = 0.474, val_accuracy = 0.799
================================================================================2022-04-04 14:13:04
[step = 30] loss: 0.429, accuracy: 0.821
[step = 60] loss: 0.455, accuracy: 0.796
EPOCH = 10, loss = 0.443,accuracy = 0.802, val_loss = 0.430, val_accuracy = 0.799
================================================================================2022-04-04 14:13:04
Finished Training...
Process finished with exit code 0
由于训练和硬件也有一定的关系,每次训练得到的结果也略有差异,这个不影响。
一共设定了10个Epoch迭代,通过迭代的结果来看,损失率
loss越来越低,从0.629->0.443;准确率也越来越高,从0.667->0.802,可以自己尝试一下增加迭代次数,看看是否会随着迭代次数的增加loss会越来越低,准确率会越来越高,中间是否会陷入局部最优,如何找到一个全局最优解,这后面文档应该会考虑到的吧,哈哈哈,咱们后面继续学~
我尝试设置Epoch=50,得到的结果确实会提升一些,小伙伴们可以再尝试一下其他的。
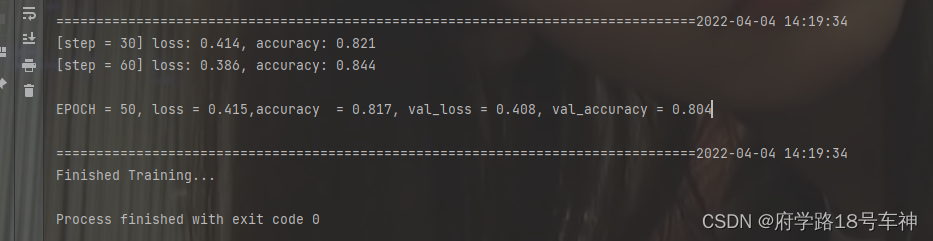
模型训练,主要掌握好整个训练模型的搭建思路,循环迭代的写法,文档作者给出的是一种通用的写法,可以借鉴,当然如果有好的写法(一定会有)也可掌握下来哦~
四、🎉评估模型
我们首先评估一下模型在训练集和验证集上的效果。
下面输出Epoch=10的结果
print(dfhistory) # Epoch=10
输出结果:
epoch loss accuracy val_loss val_accuracy
0 1.0 0.638417 0.662921 0.610701 0.730072
1 2.0 0.596947 0.675562 0.525235 0.713768
2 3.0 0.566752 0.733146 0.504490 0.777174
3 4.0 0.529242 0.766854 0.461202 0.777174
4 5.0 0.511466 0.785112 0.450230 0.771739
5 6.0 0.472861 0.793539 0.432059 0.820652
6 7.0 0.463463 0.786517 0.447174 0.793478
7 8.0 0.471010 0.794944 0.407182 0.788043
8 9.0 0.445191 0.800562 0.397194 0.793478
9 10.0 0.460264 0.792135 0.476356 0.815217
得到总体的迭代结果后,我们继续评估模型的性能,通过可视化操作实现
# %matplotlib inline
# %config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
输出可视化结果:
plot_metric(dfhistory,"loss") # 显示损失率的图,包含单个训练损失值和验证集损失值
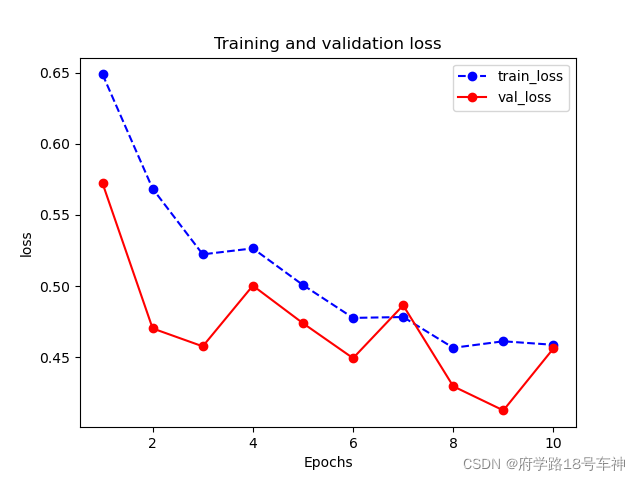
下面输出准确率的评估图
plot_metric(dfhistory,"accuracy") # 包含单个迭代的训练准确率和验证集准确率
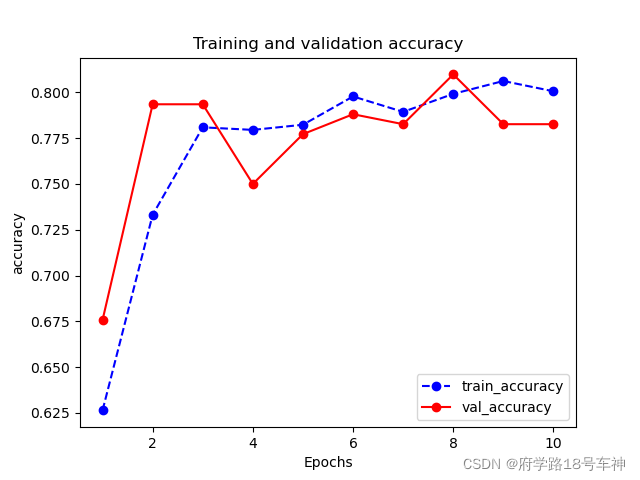
从结果来看,验证集的和训练集的结果还是很相似的,跟踪能力及模型的性能还是很好的,在迭代8-10次的时候有一些偏差,但是当迭代次数增加后,准确率会越来越高。
下图是Epoch=100的结果:
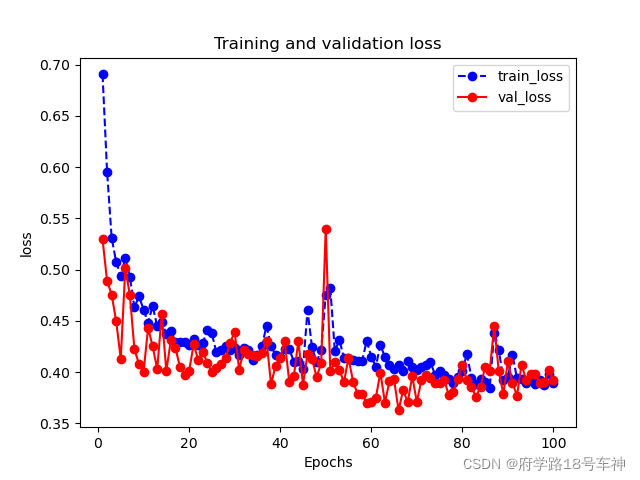
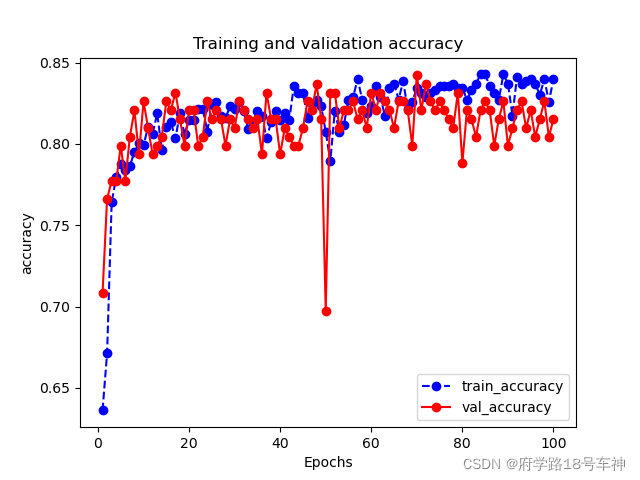
五、🎉使用模型
通常模型训练好之后,我们一般会用来对一些数据做线性回归、预测、分类、聚类等等操作。
文档中展示了预测的使用:
预测概率
#预测概率
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
print(y_pred_probs)
复现结果:
tensor([[0.2621],
[0.5652],
[0.3578],
[0.8538],
[0.4866],
[0.8762],
[0.2579],
[0.8862],
[0.5002],
[0.2572]])
计算出了Epoch=10次,每一次的预测概率。
预测类别
tensor([[0.],
[0.],
[0.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.]])
从结果来看,一共是分成了两个类别,即
0和1.
六、🎉保存模型
Pytorch 有两种保存模型的方式,都是通过调用pickle序列化方法实现的。
第一种方法只保存模型参数。
第二种方法保存完整模型。
推荐使用第一种,第二种方法可能在切换设备和目录的时候出现各种问题。
1.保存模型参数(推荐)
print(net.state_dict().keys())
输出结果:
odict_keys(['linear1.weight', 'linear1.bias', 'linear2.weight', 'linear2.bias', 'linear3.weight', 'linear3.bias'])
# 保存模型参数
torch.save(net.state_dict(), "./data/net_parameter.pkl")
net_clone = create_net()
net_clone.load_state_dict(torch.load("./data/net_parameter.pkl"))
print(net_clone.forward(torch.tensor(x_test[0:10]).float()).data)
保存的张量结果(模型参数):
tensor([[0.3254],
[0.6190],
[0.3080],
[0.6386],
[0.5521],
[0.9183],
[0.1427],
[0.7988],
[0.5306],
[0.1392]])
- 保存完整模型(不推荐)
# 法2
torch.save(net, './data/net_model.pkl')
net_loaded = torch.load('./data/net_model.pkl')
print(net_loaded(torch.tensor(x_test[0:10]).float()).data)
保存的张量结果(模型参数)和上面一致结果:
tensor([[0.3254],
[0.6190],
[0.3080],
[0.6386],
[0.5521],
[0.9183],
[0.1427],
[0.7988],
[0.5306],
[0.1392]])
🥇总结
从结构化数据建模的流程开始学习,按照准备数据、定义模型、训练模型、评估模型、使用模型、保存模型这六大常规思路,简单数据集入手,对于0基础的同学来说可能还是稍有难度,因此,本文中给出了大部分使用到的库的解释,同时给出了部分代码的注释,以便小伙伴的理解,仅供参考,如有错误,请留言指出,最后一句:开源万岁~
同时为原作者打Call:
如果本书对你有所帮助,想鼓励一下作者,记得给本项目加一颗星星star⭐️,并分享给你的朋友们喔😊!
地址在这里哦:https://github.com/lyhue1991/eat_pytorch_in_20_days
😊Reference
- https://github.com/lyhue1991/eat_pytorch_in_20_days
- https://blog.csdn.net/tfcy694/article/details/85338745
- https://www.cnblogs.com/gshang/p/13544553.html
- https://cloud.tencent.com/developer/article/1664838
- https://github.com/lyhue1991/torchkeras
- https://blog.csdn.net/u011630575/article/details/79645814
- https://pytorch.org/docs/stable/nn.html?highlight=bceloss#torch.nn.BCELoss
- https://blog.csdn.net/weixin_43914889/article/details/104664945

- 点赞
- 收藏
- 关注作者
评论(0)