R baging和boosting比较

在上一章节,博主介绍了baging和boosting的原理
本章主要讲解R代码
1 R准备工作
#R中的adabag包均有函数实现bagging和adaboost的分类建模(另外,ipred包中的bagging()函数可以实现bagging回归)。第一题就利用adabag包实现bagging和adaboost建模,并根据预测结果选择最优模型。
#a) 为了描述这两种方式,先利用全部数据建立模型:
#利用boosting()(原来的adaboost.M1()函数)建立adaboost分类
install.packages("adabag")
library(adabag)
2 全数据测试
直接使用R自带的iris数据集进行boosting建模测验,boosting会重视分类良好的分类器和关注分错的数据,逐步学习变成强分类器
a=boosting(Species~.,data=iris) #建立adaboost分类模型
(z0=table(iris[,5],predict(a,iris)$class)) #查看模型的预测结果
#模型的预测结果全部正确。
(E0=(sum(z0)-sum(diag(z0)))/sum(z0)) #计算误差率
#[1] 0
#从结果看,预测的误差率为0。
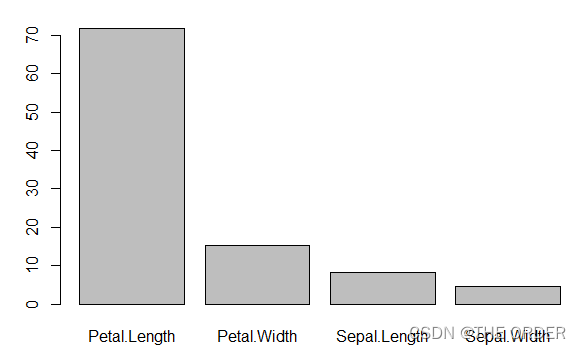
barplot(a$importance) #画出变量重要性图
#上图可以得知,各变量的重要性分别为:Petal.Length>Petal.Width>Sepal.Length>Sepal.Width
b<-errorevol(a,iris) #计算全体的误差演变
plot(b$error,type="l",main="AdaBoost error vs number of trees") #对误差演变进行画图
重要性图
残差在迭代后的变化趋势
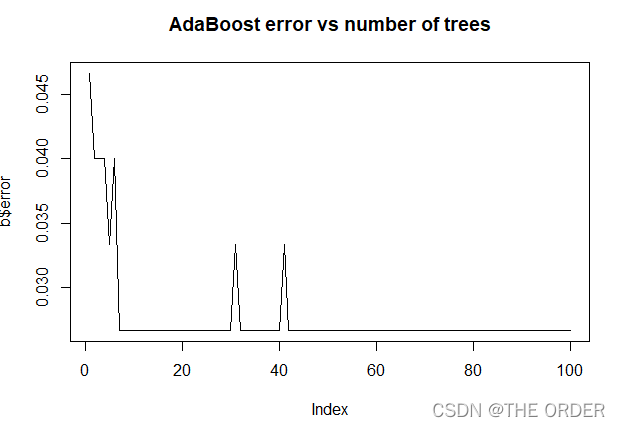
#上图可以得知,在第七次迭代后误差率就达到零了,实现预测零误差率。
#接下来,利用bagging()函数建立bagging分类模型: b=bagging(Species~.,data=iris) #建立bagging分类模型 (z0=table(iris[,5],predict(b,iris)class)) #查看模型的预测结果
bagging测试

#可以看出,bangging分类将1个Versicolor误分为Virginica,将3个Virginica误分为Versicolor。
(E0=(sum(z0)-sum(diag(z0)))/sum(z0)) #计算误差率
#[1] 0.02666667
#误差率为0.027。
barplot(b$importance)
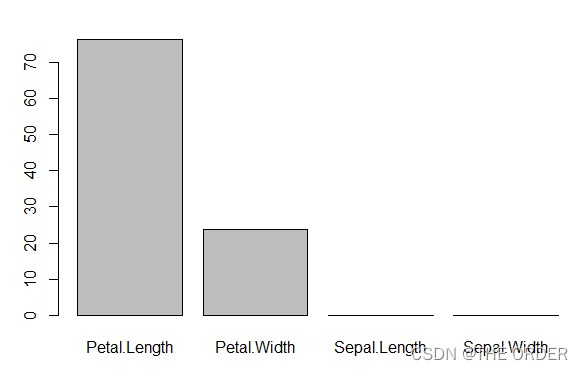
上图可以得知,各变量的重要性分别为:Petal.Length>Petal.Width>Sepal.Length>Sepal.Width
在全量建模的情况下,对比bagging和adaboost分类,adaboost分类的精确度高达100%,明显优于bagging分类。
下面再做5折交叉验证,这里仅给出训练集和测试集的分类平均误差率:
3 交叉验证比较
#利用boosting()(原来的adaboost.M1()函数)建立adaboost分类
set.seed(1044) #设定随机种子
samp=c(sample(1:50,25),sample(51:100,25),sample(101:150,25)) #进行随机抽样
a=boosting(Species~.,data=iris[samp,]) #利用训练集建立adaboost分类模
(z0=table(iris[-samp,5],predict(a,iris[-samp,])$class))
(E0=(sum(z0)-sum(diag(z0)))/sum(z0))
#从结果看,训练集的预测结果是100%正确,测试集的误差率是0.02666667,有1个实际为Versicolor误分为Virginica,1个Virginica误分为Versicolor

#接下来,利用bagging()函数建立bagging分类模型:
b=bagging(Species~.,data=iris[samp,]) #利用训练集建立bagging分类模型
(z0=table(iris[-samp,5],predict(b,iris[-samp,])$class))
(E0=(sum(z0)-sum(diag(z0)))/sum(z0))
Bagging对训练集的预测结果有2个实际为Virginica的误分为Versicolor,误差率为0.027,对测试集的预测结果有2个实际为Versicolor的误分类为Virginica,有2个实际为Virginica的误分为Versicolor,误差率为0.053。
#boosting比bagging好并不是绝对的,随机样本的改变会发生变化
#总结:从以上的预测结果对比得知,对于鸢尾花数据集,adabag分类的效果明显优于bagging分类。

- 点赞
- 收藏
- 关注作者
评论(0)