Flink的DataSource三部曲之三:自定义

【摘要】 实战多种自定义flink数据源
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本文是《Flink的DataSource三部曲》的终篇,前面都是在学习Flink已有的数据源功能,但如果这些不能满足需要,就要自定义数据源(例如从数据库获取数据),也就是今天实战的内容,如下图红框所示:


环境和版本
- 本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
在服务器上搭建Flink服务
- 前面两章的程序都是在IDEA上运行的,本章需要通过Flink的web ui观察运行结果,因此要单独部署Flink服务,我这里是在CentOS环境通过docker-compose部署的,以下是docker-compose.yml的内容,用于参考:
version: "2.1"
services:
jobmanager:
image: flink:1.9.2-scala_2.12
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager1:
image: flink:1.9.2-scala_2.12
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager2:
image: flink:1.9.2-scala_2.12
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
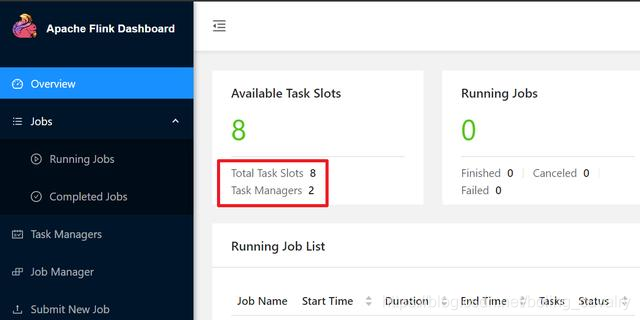
- 下图是我的Flink情况,有两个Task Maganer,共八个Slot全部可用:
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
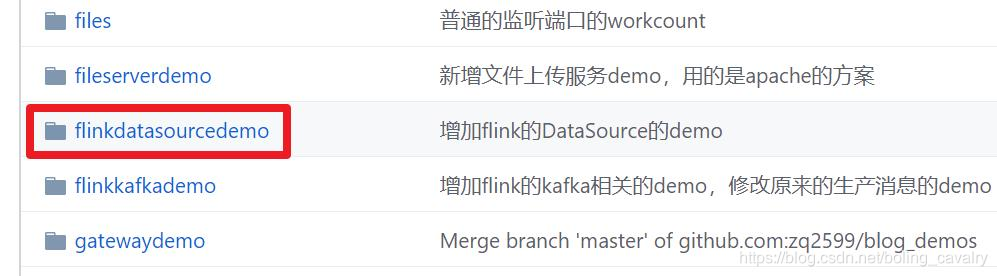
这个git项目中有多个文件夹,本章的应用在flinkdatasourcedemo文件夹下,如下图红框所示:
准备完毕,开始开发;
实现SourceFunctionDemo接口的DataSource
- 从最简单的开始,开发一个不可并行的数据源并验证;
- 实现SourceFunction接口,在工程flinkdatasourcedemo中增加SourceFunctionDemo.java:
package com.bolingcavalry.customize;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
public class SourceFunctionDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为2
env.setParallelism(2);
DataStream<Tuple2<Integer,Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<Integer, Integer>>() {
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Tuple2<Integer, Integer>> ctx) throws Exception {
int i = 0;
while (isRunning) {
ctx.collect(new Tuple2<>(i++ % 5, 1));
Thread.sleep(1000);
if(i>9){
break;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
});
dataStream
.keyBy(0)
.timeWindow(Time.seconds(2))
.sum(1)
.print();
env.execute("Customize DataSource demo : SourceFunction");
}
}
- 从上述代码可见,给addSource方法传入一个匿名类实例,该匿名类实现了SourceFunction接口;
- 实现SourceFunction接口只需实现run和cancel方法;
- run方法产生数据,这里为了简答操作,每隔一秒产生一个Tuple2实例,由于接下来的算子中有keyBy操作,因此Tuple2的第一个字段始终保持着5的余数,这样可以多几个key,以便分散到不同的slot中;
- 为了核对数据是否准确,这里并没有无限发送数据,而是仅发送了10个Tuple2实例;
- cancel是job被取消时执行的方法;
- 整体并行度显式设置为2;
- 编码完成后,执行mvn clean package -U -DskipTests构建,在target目录得到文件flinkdatasourcedemo-1.0-SNAPSHOT.jar;
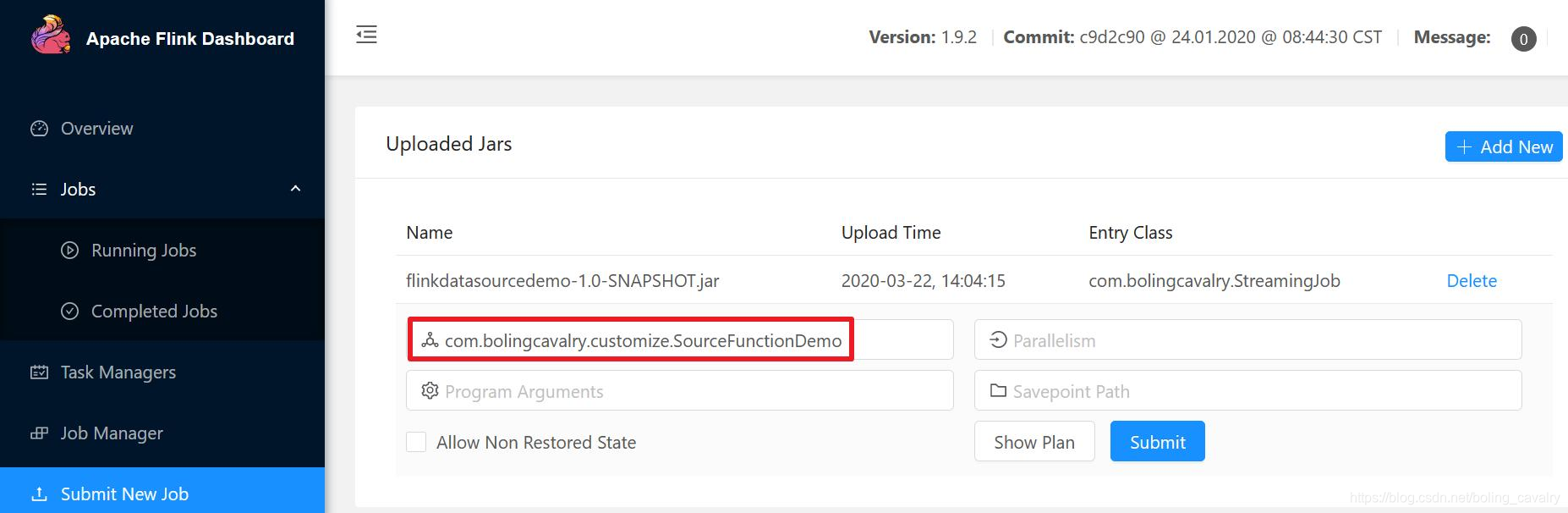
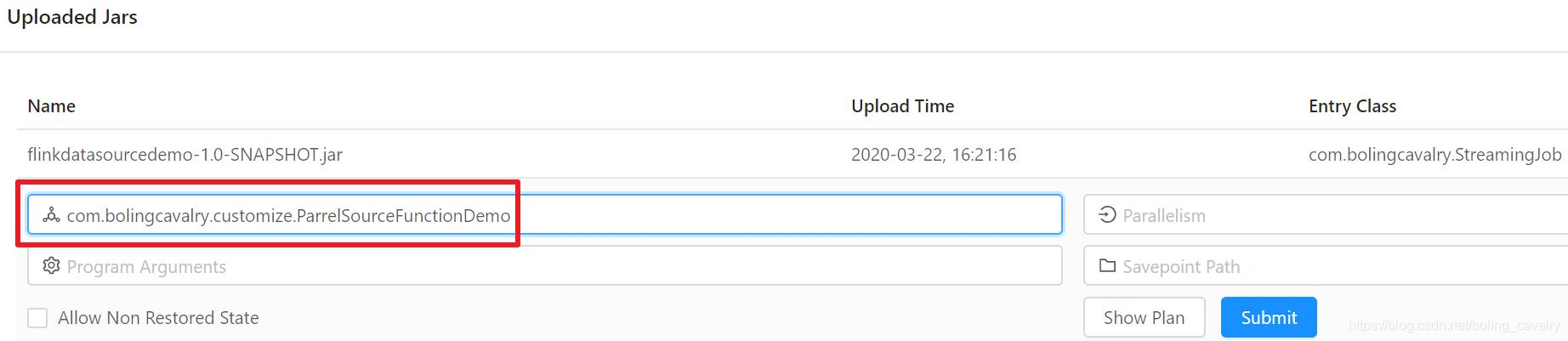
- 在Flink的web UI上传flinkdatasourcedemo-1.0-SNAPSHOT.jar,并指定执行类,如下图红框所示:
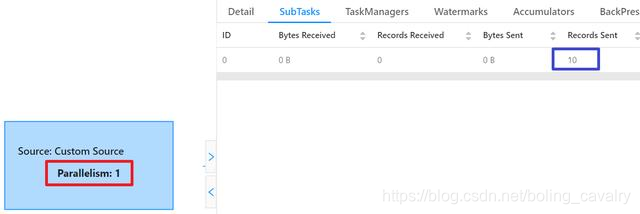
- 任务执行完成后,在Completed Jobs页面可以看到,DataSource的并行度是1(红框),对应的SubTask一共发送了10条记录(蓝框),这和我们的代码是一致的;
- 再来看消费的子任务,如下图,红框显示并行度是2,这和前面代码中的设置是一致的,蓝框显示两个子任务一共收到10条数据记录,和上游发出的数量一致:
- 接下来尝试多并行度的DataSource;
实现ParallelSourceFunction接口的DataSource
- 如果自定义DataSource中有复杂的或者耗时的操作,那么增加DataSource的并行度,让多个SubTask同时进行这些操作,可以有效提升整体吞吐量(前提是硬件资源充裕);
- 接下来实战可以并行执行的DataSource,原理是DataSoure实现ParallelSourceFunction接口,代码如下,可见和SourceFunctionDemo几乎一样,只是addSource方发入参不同,该入参依然是匿名类,不过实现的的接口变成了ParallelSourceFunction:
package com.bolingcavalry.customize;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
public class ParrelSourceFunctionDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为2
env.setParallelism(2);
DataStream<Tuple2<Integer,Integer>> dataStream = env.addSource(new ParallelSourceFunction<Tuple2<Integer, Integer>>() {
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Tuple2<Integer, Integer>> ctx) throws Exception {
int i = 0;
while (isRunning) {
ctx.collect(new Tuple2<>(i++ % 5, 1));
Thread.sleep(1000);
if(i>9){
break;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
});
dataStream
.keyBy(0)
.timeWindow(Time.seconds(2))
.sum(1)
.print();
env.execute("Customize DataSource demo : ParallelSourceFunction");
}
}
- 编码完成后,执行mvn clean package -U -DskipTests构建,在target目录得到文件flinkdatasourcedemo-1.0-SNAPSHOT.jar;
- 在Flink的web UI上传flinkdatasourcedemo-1.0-SNAPSHOT.jar,并指定执行类,如下图红框所示:
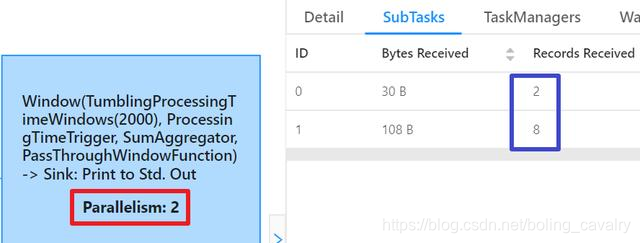
- 任务执行完成后,在Completed Jobs页面可以看到,如今DataSource的并行度是2(红框),对应的SubTask一共发送了20条记录(蓝框),这和我们的代码是一致的,绿框显示两个SubTask的Task Manager是同一个:
- 为什么DataSource一共发送了20条记录?因为每个SubTask中都有一份ParallelSourceFunction匿名类的实例,对应的run方法分别被执行,因此每个SubTask都发送了10条;
- 再来看消费数据的子任务,如下图,红框显示并行度与代码中设置的数量是一致的,蓝框显示两个SubTask一共消费了20条记录,和数据源发出的记录数一致,另外绿框显示两个SubTask的Task Manager是同一个,而且和DataSource的TaskManager是同一个,因此整个job都是在同一个TaskManager进行的,没有跨机器带来的额外代价:
- 接下来要实践的内容,和另一个重要的抽象类有关;


继承抽象类RichSourceFunction的DataSource
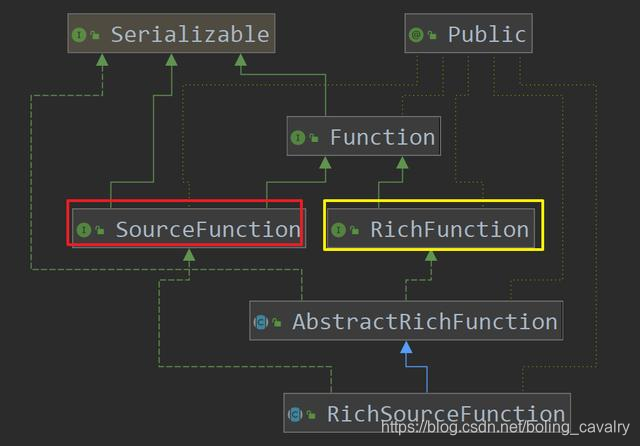
- 对RichSourceFunction的理解是从继承关系开始的,如下图,SourceFunction和RichFunction的特性最终都体现在RichSourceFunction上,SourceFunction的特性是数据的生成(run方法),RichFunction的特性是对资源的连接和释放(open和close方法):
- 接下来开始实战,目标是从MySQL获取数据作为DataSource,然后消费这些数据;
- 请提前准备好可用的MySql数据库,然后执行以下SQL,创建库、表、记录:
DROP DATABASE IF EXISTS flinkdemo;
CREATE DATABASE IF NOT EXISTS flinkdemo;
USE flinkdemo;
SELECT 'CREATING DATABASE STRUCTURE' as 'INFO';
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(25) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
INSERT INTO `student` VALUES ('1', 'student01'), ('2', 'student02'), ('3', 'student03'), ('4', 'student04'), ('5', 'student05'), ('6', 'student06');
COMMIT;
- 在pom.xml中增加mysql依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
- 新增MySQLDataSource.java,内容如下:
package com.bolingcavalry.customize;
import com.bolingcavalry.Student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MySQLDataSource extends RichSourceFunction<Student> {
private Connection connection = null;
private PreparedStatement preparedStatement = null;
private volatile boolean isRunning = true;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
if(null==connection) {
Class.forName("com.mysql.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:mysql://192.168.50.43:3306/flinkdemo?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
}
if(null==preparedStatement) {
preparedStatement = connection.prepareStatement("select id, name from student");
}
}
/**
* 释放资源
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
if(null!=preparedStatement) {
try {
preparedStatement.close();
} catch (Exception exception) {
exception.printStackTrace();
}
}
if(null==connection) {
connection.close();
}
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next() && isRunning) {
Student student = new Student();
student.setId(resultSet.getInt("id"));
student.setName(resultSet.getString("name"));
ctx.collect(student);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
- 上面的代码中,MySQLDataSource继承了RichSourceFunction,作为一个DataSource,可以作为addSource方法的入参;
- open和close方法都会被数据源的SubTask调用,open负责创建数据库连接对象,close负责释放资源;
- open方法中直接写死了数据库相关的配置(不可取);
- run方法在open之后被调用,作用和之前的DataSource例子一样,负责生产数据,这里是用前面准备好的preparedStatement对象直接去数据库取数据;
- 接下来写个Demo类使用MySQLDataSource:
package com.bolingcavalry.customize;
import com.bolingcavalry.Student;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichSourceFunctionDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为2
env.setParallelism(2);
DataStream<Student> dataStream = env.addSource(new MySQLDataSource());
dataStream.print();
env.execute("Customize DataSource demo : RichSourceFunction");
}
}
- 从上述代码可见,MySQLDataSource实例传入addSource方法即可创建数据集;
- 像之前那样,编译构建、提交到Flink、指定任务类,即可开始执行此任务;
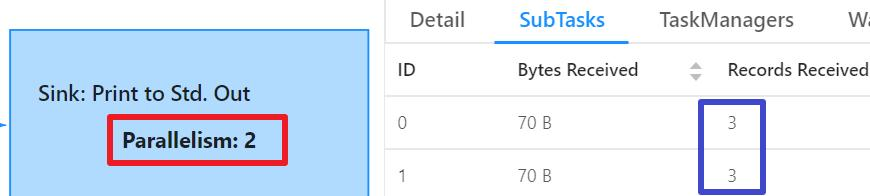
- 执行结果如下图,DataSource的并行度是1,一共发送六条记录,即student表的所有记录:
- 处理数据的SubTask一共两个,各处理三条消息:
- 由于代码中对数据集执行了print(),因此在TaskManager控制台看到数据输出如下图红框所示:

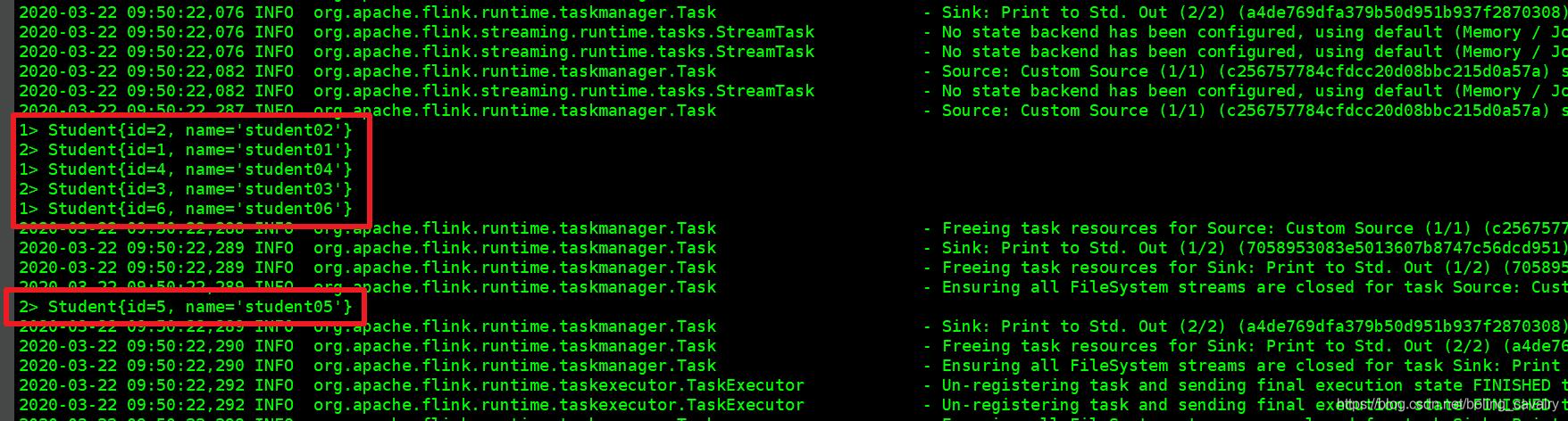
关于RichParallelSourceFunction
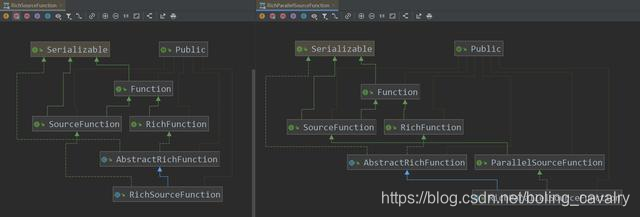
- 实战到了这里,还剩RichParallelSourceFunction这个抽象类我们还没有尝试过,但我觉得这个类可以不用在文中多说了,咱们把RichlSourceFunction和RichParallelSourceFunction的类图放在一起看看:
- 从上图可见,在RichFunction继承关系上,两者一致,在SourceFunction的继承关系上,RichlSourceFunction和RichParallelSourceFunction略有不同,RichParallelSourceFunction走的是ParallelSourceFunction这条线,而SourceFunction和ParallelSourceFunction的区别,前面已经讲过了,因此,结果不言而喻:继承RichParallelSourceFunction的DataSource的并行度是可以大于1的;
- 读者您如果有兴趣,可以将前面的MySQLDataSource改成继承RichParallelSourceFunction再试试,DataSource的并行度会超过1,但是绝不是只有这一点变化,DAG图显示Flink还会做一些Operator Chain处理,但这不是本章要关注的内容,只能说结果是正确的(两个DataSource的SubTask,一共发送12条记录),建议您试试;
- 至此,《Flink的DataSource三部曲》系列就全部完成了,好的开始是成功的一半,在拿到数据后,后面还有很多知识点要学习和掌握,接下来的文章会继续深入Flink的奇妙之旅;
欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)