python 线程 ~~ ~~~为面试开辟VIP通道~~~~~测试、死锁、全局变量共享、守护主线程等。。。。。。

线程(英语:thread)是操作系统能够进行运算调度的最小单位。线程很重要,通过本篇文章可以让你们很好的了解线程的传参、线程执行规则、守护主线程、线程间共享全局变量、进程互斥锁、死锁进程怎么解决。希望对你们有所帮助。
在了解线程之间的操作及进程死锁之前先来了解一下什么是进程?以下是官方的解释。
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如Win32线程;由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;或者由内核与用户进程,如Windows 7的线程,进行混合调度。
同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
一个进程可以有很多线程,每条线程并行执行不同的任务。
在多核或多CPU,或支持Hyper-threading的CPU上使用多线程程序设计的好处是显而易见,即提高了程序的执行吞吐率。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,从而提高了程序的执行效率。
看着是不是非常的晕,没关系,下面让我们用实例来享受线程带来的舒适。
**
1、线程之元组传参
**
没错,你没有看错,和前面所说的进程一样,线程也可以用元组传参。这样说吧,只要有函数的存在基本上都能以元组传参。下面来看一下元组是怎么传参的
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
# TODO 元组
import threading
import time
def task(count):
for i in range(count):
print("正在工作")
time.sleep(0.2)
else:
print("工作结束")
if __name__ == '__main__':
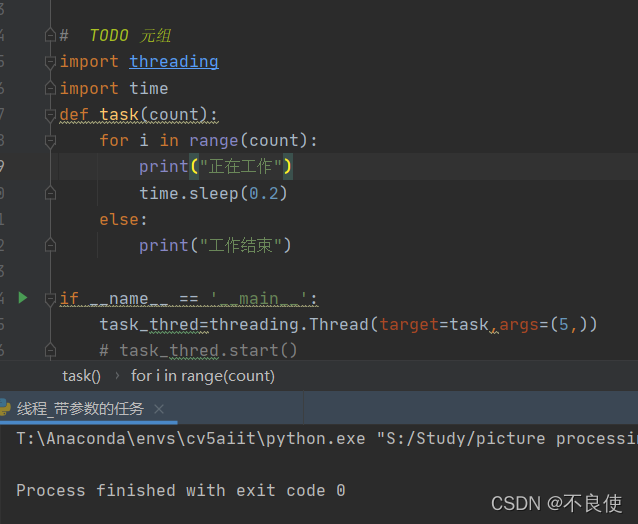
#创建子线条程
task_thred=threading.Thread(target=task,args=(5,))
task_thred.start()
结果:
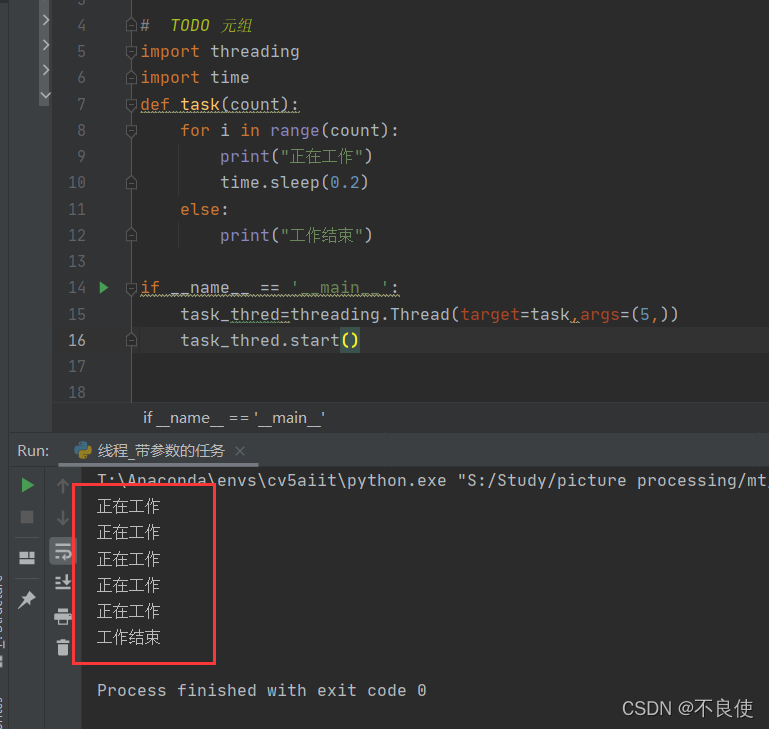
因为传入的元组是5 ,(5,)是元组的传参操作,参数为一个元素时候一定不能忘掉了逗号。
task_thred=threading.Thread(target=task,args=(5,))创建子线程并将元组(5,)传给task(count)函数,函数中count形参接收。其中target=task,target就是目标,也就是目标函数的意思。
task_thred.start()就是将上面创建的线程开启,注意一定要开启线程,不然线程开启不了程序无法执行。
time.sleep(0.2),休眠0.2秒,看起来卡顿卡顿的,更好的看出进程执行的过程
**
2、线程之字典传参
**
# TODO 字典
import threading
import time
def task(count):
for i in range(count):
print("正在工作")
time.sleep(0.2)
else:
print("工作结束")
if __name__ == '__main__':
#创建子进程
task_thred=threading.Thread(target=task,kwargs={"count":6})
task_thred.start()
结果:
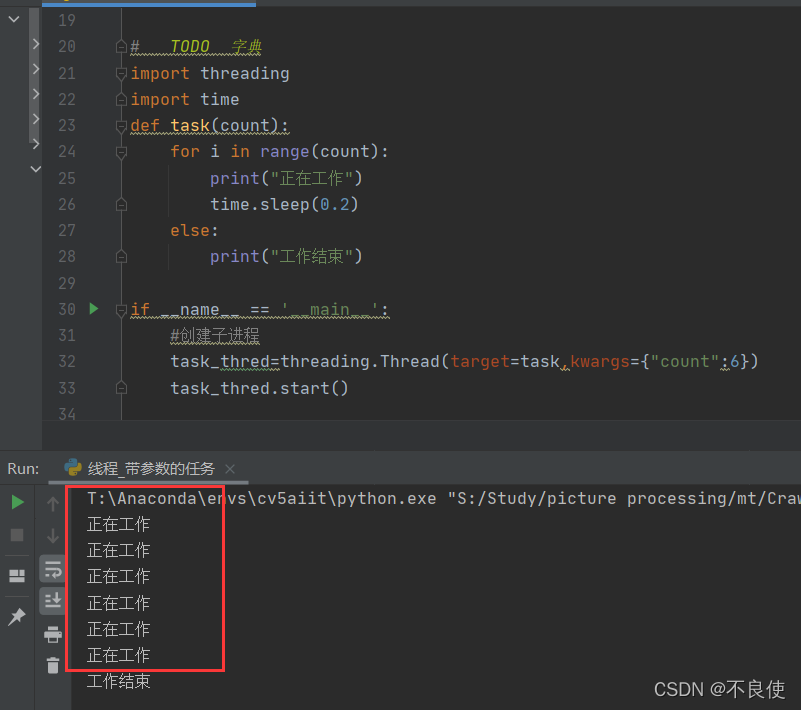
task_thred=threading.Thread(target=task,kwarg={"count":6})创建子线程并将字典{“count”:6}传给task(count)函数,函数中count形参接收。其中target=task,target就是目标,也就是目标函数的意思。字典就类似于json字符串,找个网页单机右键检查找到网络下面的全部,找一个js文件打开(可以不一定是js文件,其他的也可以)刷新一下你就可以发现标头里的都是以字符串显示的
task_thred.start()就是将上面创建的线程开启,注意一定要开启线程,不然线程开启不了程序无法执行。
time.sleep(0.2),休眠0.2秒,看起来卡顿卡顿的,更好的看出进程执行的过程
**
3、线程执行规则
**
很显然是无序的,线程和进程都是用于资源调度,是随机分配的,所以是都是无序的。下面通过例子来看一下。
# TODO 线程之间执行时无序的
import threading
import time
def work1():
time.sleep(1)
print("当前的线程是:",threading.current_thread().name)
if __name__ == '__main__':
for _ in range(5):
work_thred=threading.Thread(target=work1)
work_thred.start()
结果:
第一次执行结果
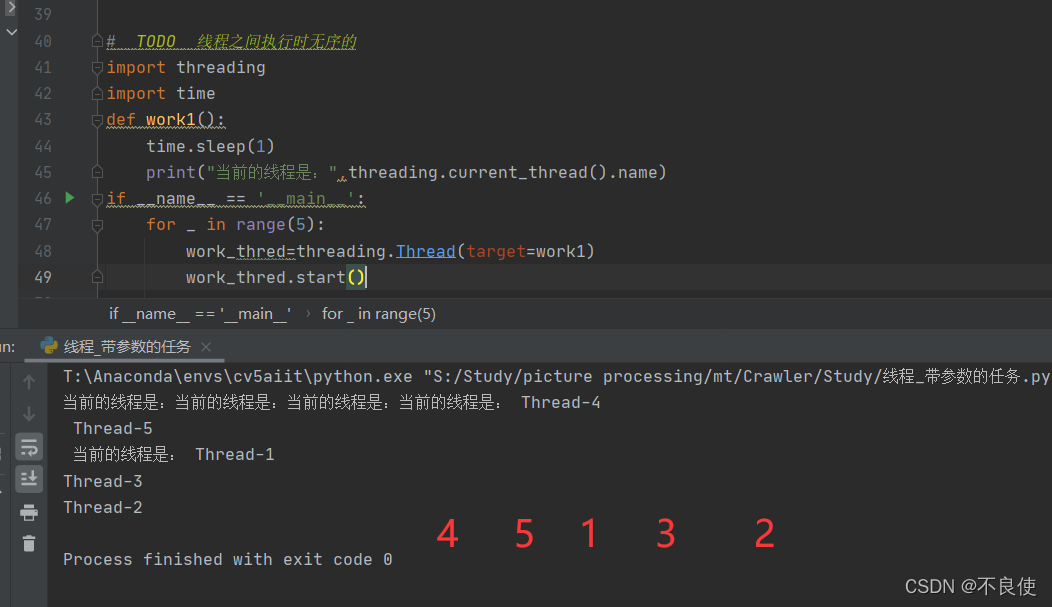
第二次执行结果

我们对比两次的执行结果可以发现第一次执行的线程顺序是: 4->5->1->3->2,而蒂维茨执行的县城顺序是: 3->5->2->1->4,很显然两次的执行顺序不一致,所以线程的执行是没有顺序的
**
4、测试主次线程权限,如何消除权限???又如何巩固主线程的掌控权
**
测试主线程是否会等待子线程执行完毕关闭,通过下面的例子你可以很好的了解。
# TODO 测试主线程是否会等待子线程执行完毕关闭
import time
import threading
def show_info():
for i in range(5):
print("test,",i)
time.sleep(1)
if __name__ == '__main__':
show_thted=threading.Thread(target=show_info)
show_thted.start()
time.sleep(1.5)
print("结束")
**
结果:
**
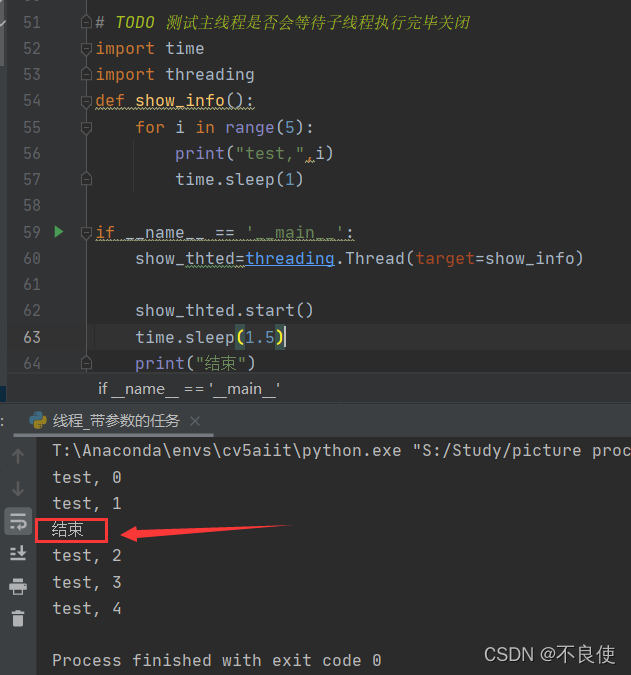
主线程都结束了,子线程还在执行,是不是感觉很懵。这还了得,这就相当于诱敌深入的时候将军叫你撤退,你还一股劲地往前冲,这不是打乱计划,瞎搞吗?纳闷怎么解决这个问题了。
4.1、方法一:
创建进程的时候加入守护进程daemon
# TODO 测试主线程是否会等待子线程执行完毕关闭
import time
import threading
def show_info():
for i in range(5):
print("test,",i)
time.sleep(1)
if __name__ == '__main__':
show_thted=threading.Thread(target=show_info,daemon=True)
show_thted.start()
time.sleep(1.5)
print("结束")
结果:
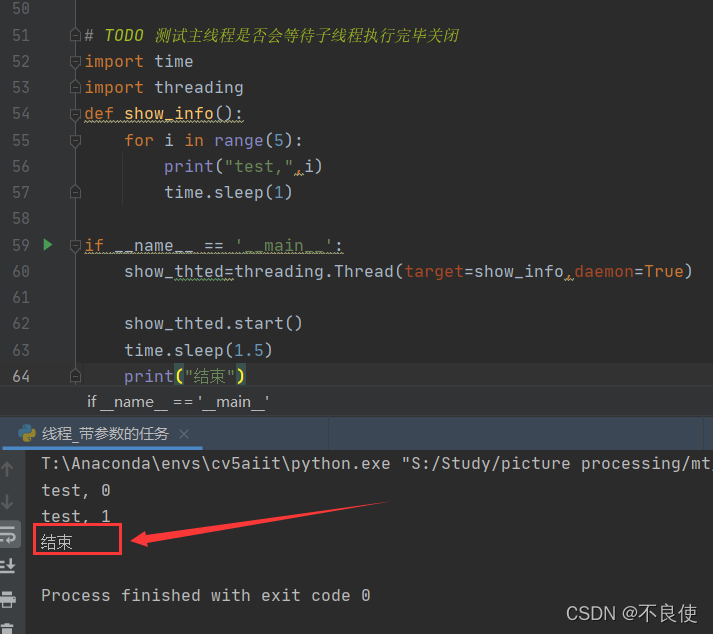
我们可以发现主线程结束后,子进程也停止了执行,达到预期目的,方法可行。
4.2、方法二
难道必须在创建进程的时候就要放入守护进程吗?
# TODO 测试主线程是否会等待子线程执行完毕关闭
import time
import threading
def show_info():
for i in range(5):
print("test,",i)
time.sleep(1)
if __name__ == '__main__':
show_thted=threading.Thread(target=show_info)
show_thted.setDaemon(True)
show_thted.start()
time.sleep(1.5)
print("结束")
结果:
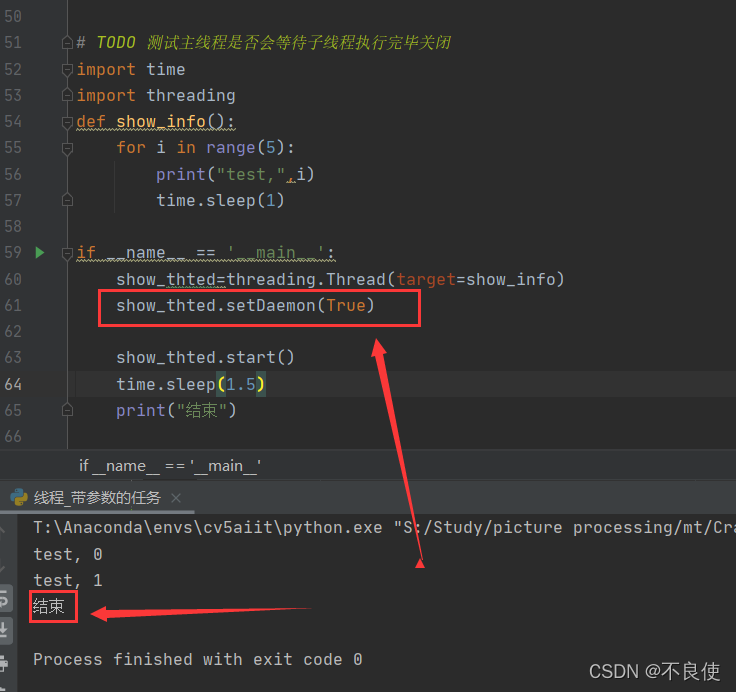
这样是不是也可以确保主线程停止后子线程跟着停止,ok,达到效果,方法可行。但是你们有没有发现这样很多余,明明一行代码就可以实现的,为什么要多行代码执行呢,但是作为一个方法,记住还是很有必要的。
**
5、线程之间共享全局变量
**
# TODO 线程之间共享全局变量
import threading
import time
my_list=[]
#写入数据
def write_data():
for i in range(5):
my_list.append(i)
time.sleep(0.1)
print("write_data",my_list)
# 读取数据
def read_data():
print("read_data",my_list)
if __name__ == '__main__':
# 创建写入数据线程
write_dataThred=threading.Thread(target=write_data)
# 创建读取数据线程
read_dataThred=threading.Thread(target=read_data)
#开启进程
write_dataThred.start()
# 主线程等待写入线程执行完成以后代码再继续往下执行
write_dataThred.join()# 等待子线程执行之后再执行下一次代码,不加这行你会发现read_data 读不到数据
print("开始读取数据")
结果:
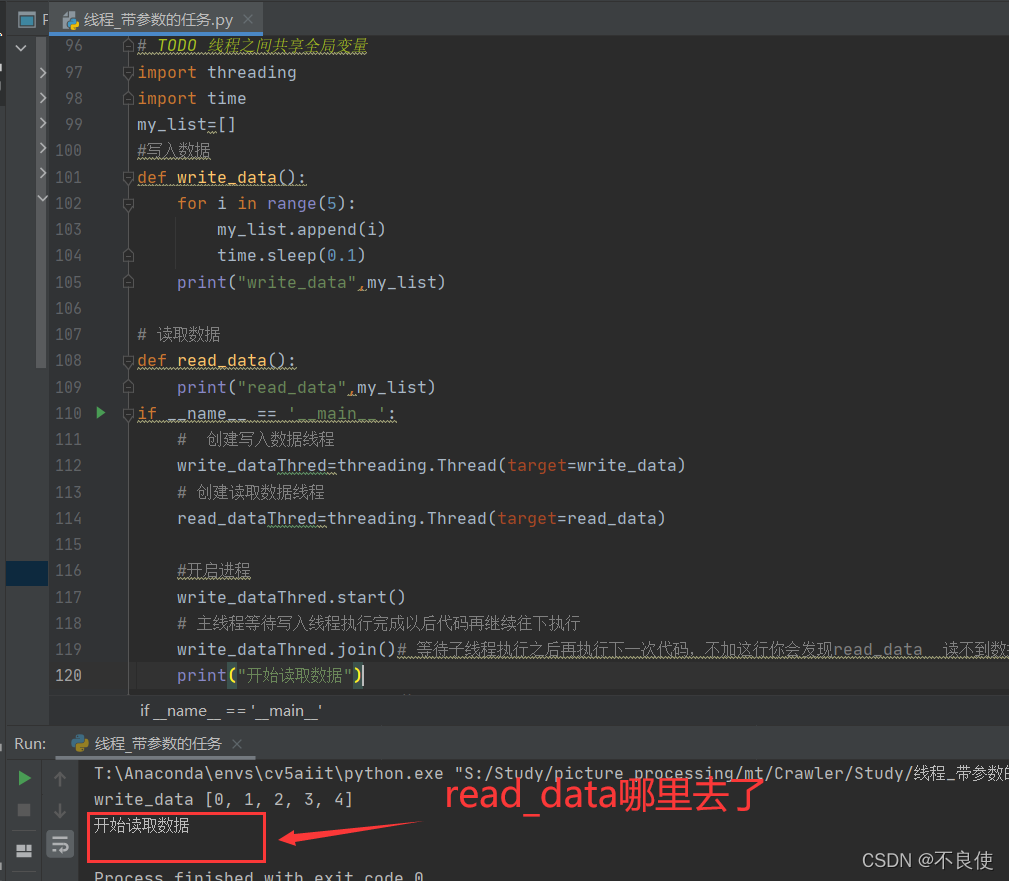
read_data 哪去了??????
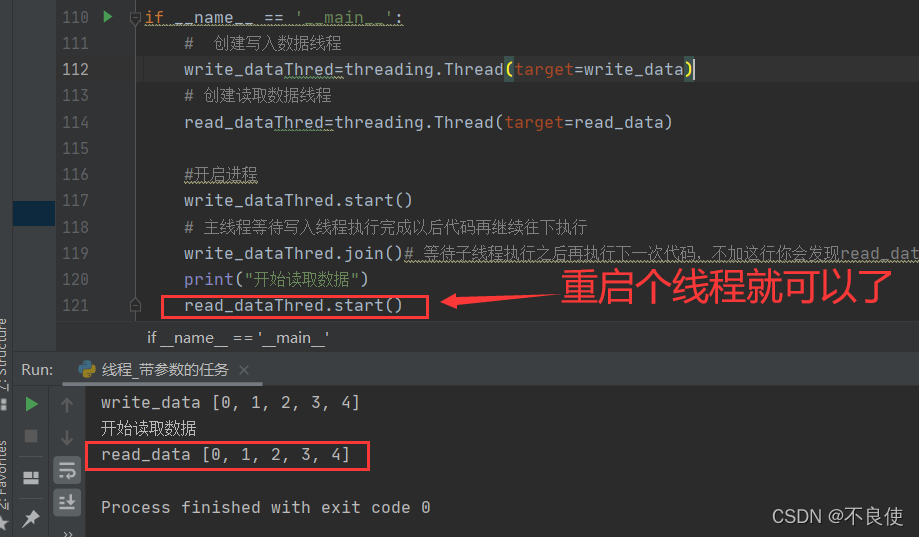
从上图可以发现只要重新启动read_dataThred线程就可以了
你难道认为这样就可以了吗,太天真了。-_-
下面再引入一个例子。
# TODO 线程之间共享全局变量出现问题 问题:线程不一致,交替拿变量 解决方法 保持线程同步,同一时刻只能有一个线程去操作全局变量 两种方式 线程等待 + 互斥所
import threading
# 创建函数,实现循环100万次,每次全局变量加一
g_num=0
# 每次全局变量加一
def sun_num():
for i in range(1000000):
global g_num
g_num+=1
print("sun_num",g_num)
# 每次全局变量加一
def sun_num2():
for i in range(1000000):
global g_num
g_num+=1
print("sun_num2", g_num)
if __name__ == '__main__':
sun_numThred=threading.Thread(target=sun_num)
sun_num2Thred=threading.Thread(target=sun_num2)
#开启线程
sun_numThred.start()
sun_num2Thred.start()
结果:
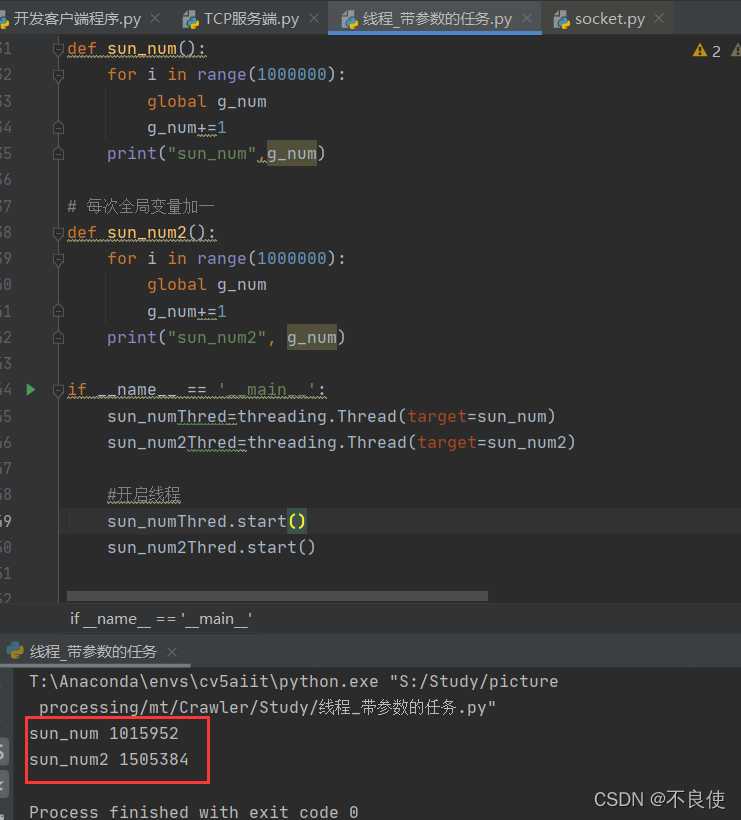
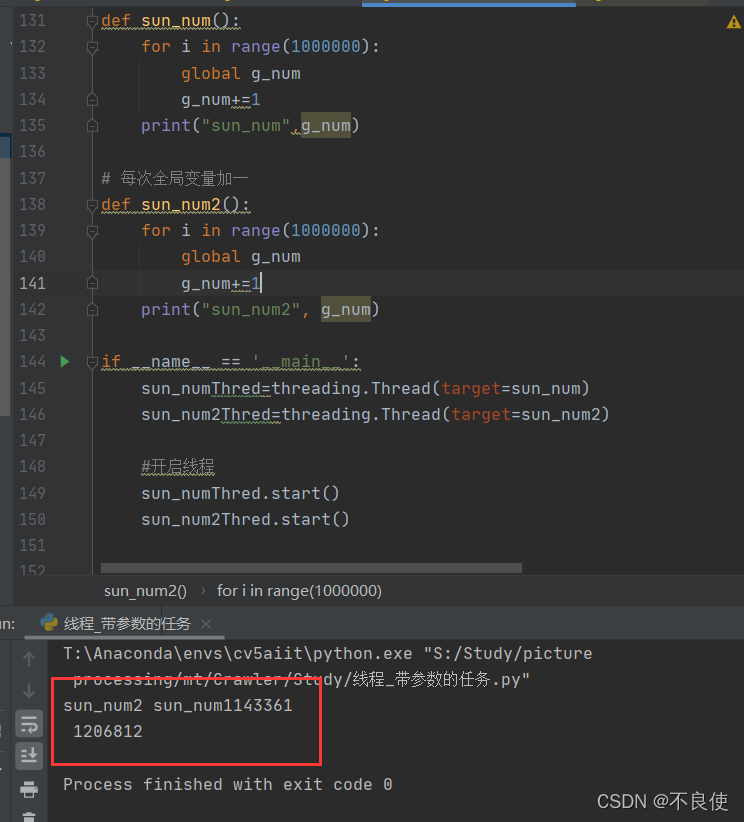
结果是出结果了,但是你们细看一下代码,你们不感觉这个答案有问题吗?
有没有这样一个疑问,for循环,遍历共享变量,最后应该是1000000和2000000啊,怎么打印出来的是1000000和1456202,而且细心的你还会发现每次的大男孩不一样。想要解决问题应该怎么办呢?
问题总结:线程不一致,交替拿变量 解决方法 保持线程同步,同一时刻只能有一个线程去操作全局变量 两种方式 线程等待 + 互斥所
线程等待:join出场
# TODO 线程之间共享全局变量出现问题 问题:线程不一致,交替拿变量 解决方法 保持线程同步,同一时刻只能有一个线程去操作全局变量 两种方式 线程等待 + 互斥所
import threading
# 创建函数,实现循环100万次,每次全局变量加一
g_num=0
# 每次全局变量加一
def sun_num():
for i in range(1000000):
global g_num
g_num+=1
print("sun_num",g_num)
# 每次全局变量加一
def sun_num2():
for i in range(1000000):
global g_num
g_num+=1
print("sun_num2", g_num)
if __name__ == '__main__':
sun_numThred=threading.Thread(target=sun_num)
sun_num2Thred=threading.Thread(target=sun_num2)
#开启线程
sun_numThred.start()
# # TODO 方法一
sun_numThred.join()
sun_num2Thred.start()
结果:
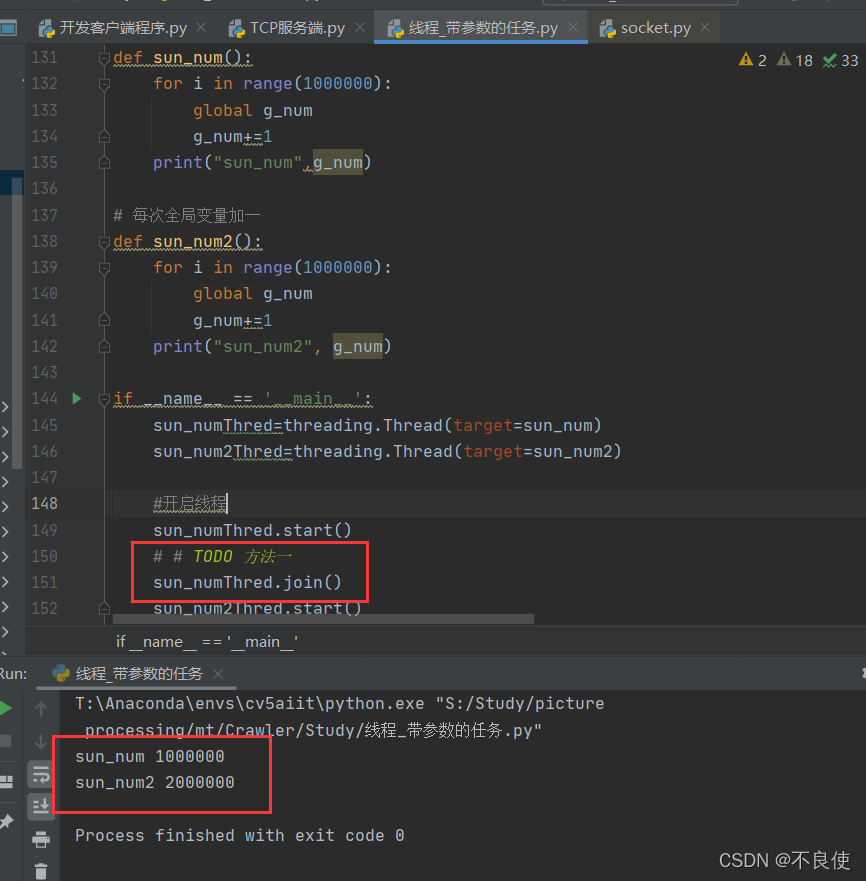
线程等待,当前线程等待其他线程执行某些操作,典型场景就是生产者消费者模式,在任务条件不满足时,等待其他线程的操作从而使得条件满足。等到其他线程完成操作释放后再分配线程。当前线程获得资源继续执行操作。
**
6、互斥锁
**
****互斥锁 Lock():在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
互斥锁三步骤 ~~~ 创建一把锁==》上锁==》释放锁 三步走
# TODO 互斥锁 Lock()
import threading
# # TODO 创建一把锁==》上锁==》释放锁 三步走
# mutext=threading.Lock()
# mutext.acquire()
# mutext.release()
#定义全局变量
g_num=0
# 创建一把锁
mutext=threading.Lock()
# 每次全局变量加一
def sun_num():
# TODO 上锁
mutext.acquire()
for i in range(1000000):
global g_num
g_num+=1
print("sun_num",g_num)
# TODO 释放锁
mutext.release()
# 每次全局变量加一
def sun_num2():
# TODO 上锁
mutext.acquire()
for i in range(1000000):
global g_num
g_num+=1
print("sun_num2", g_num)
if __name__ == '__main__':
sun_numThred=threading.Thread(target=sun_num)
sun_num2Thred=threading.Thread(target=sun_num2)
#开启线程
sun_numThred.start()
sun_num2Thred.start()
结果:
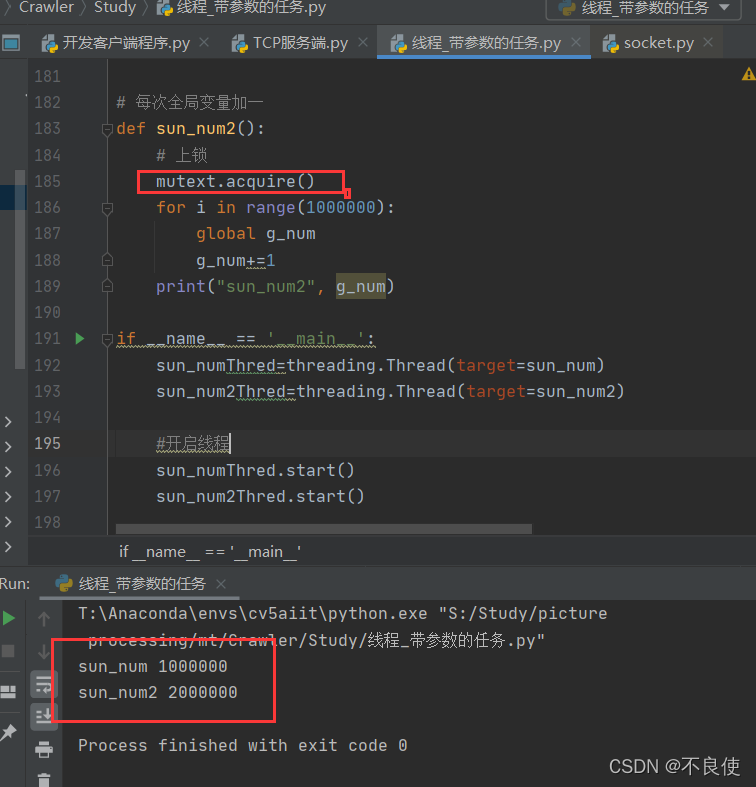
是不是非常神奇。
主义事项:
一、互斥锁就三步骤 1、创建一把锁 2、上锁 3、释放锁 。
二、保证共享数据操作的完整性
三、等当前上锁线程执行完成,释放锁后其他线程才能申请资源
**
7、死锁
**
死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去
# TODO 死锁
import threading
import time
# 创建互斥锁
lock=threading.Lock()
def get_value(index):
#上锁
lock.acquire()
print(threading.current_thread())
my_list=[3,4,7,2]
# 根据下标释放取值
if index>=len(my_list):
print("下标越界:",index)
# TODO 当下标越界了释放锁,让后面线程继续取值
# lock.release()
return
value=my_list[index]
print(value)
time.sleep(0.2)
#释放锁
# lock.release()
if __name__ == '__main__':
#模拟大量线程取值
for i in range(30):
sub_thred=threading.Thread(target=get_value,args=(i,))
sub_thred.start()
结果:
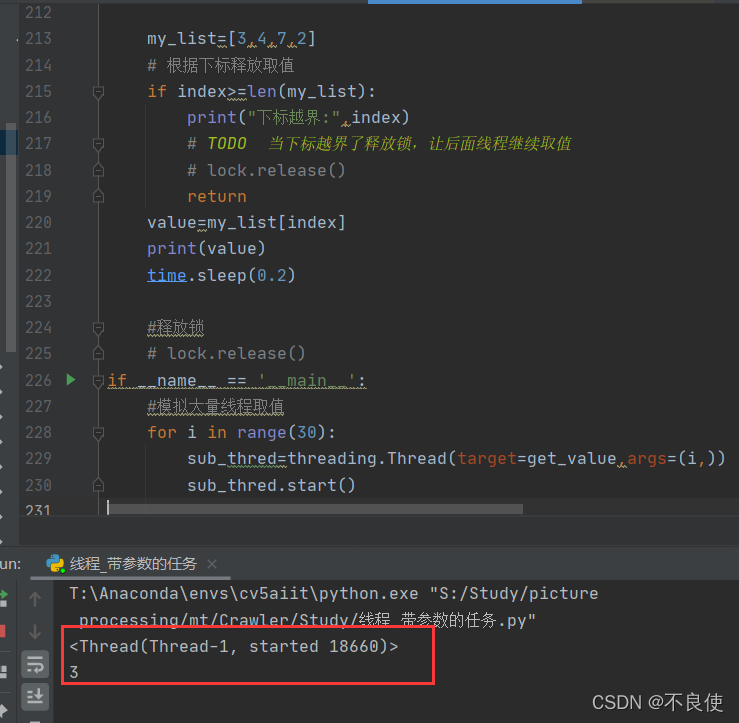
注释掉释放锁的操作,线程刚执行就卡住了,产生了死锁。
打开释放所操作
# TODO 死锁
import threading
import time
# 创建互斥锁
lock=threading.Lock()
def get_value(index):
#上锁
lock.acquire()
print(threading.current_thread())
my_list=[3,4,7,2]
# 根据下标释放取值
if index>=len(my_list):
print("下标越界:",index)
# TODO 当下标越界了释放锁,让后面线程继续取值
lock.release()
return
value=my_list[index]
print(value)
time.sleep(0.2)
#释放锁
lock.release()
if __name__ == '__main__':
#模拟大量线程取值
for i in range(30):
sub_thred=threading.Thread(target=get_value,args=(i,))
sub_thred.start()
结果:
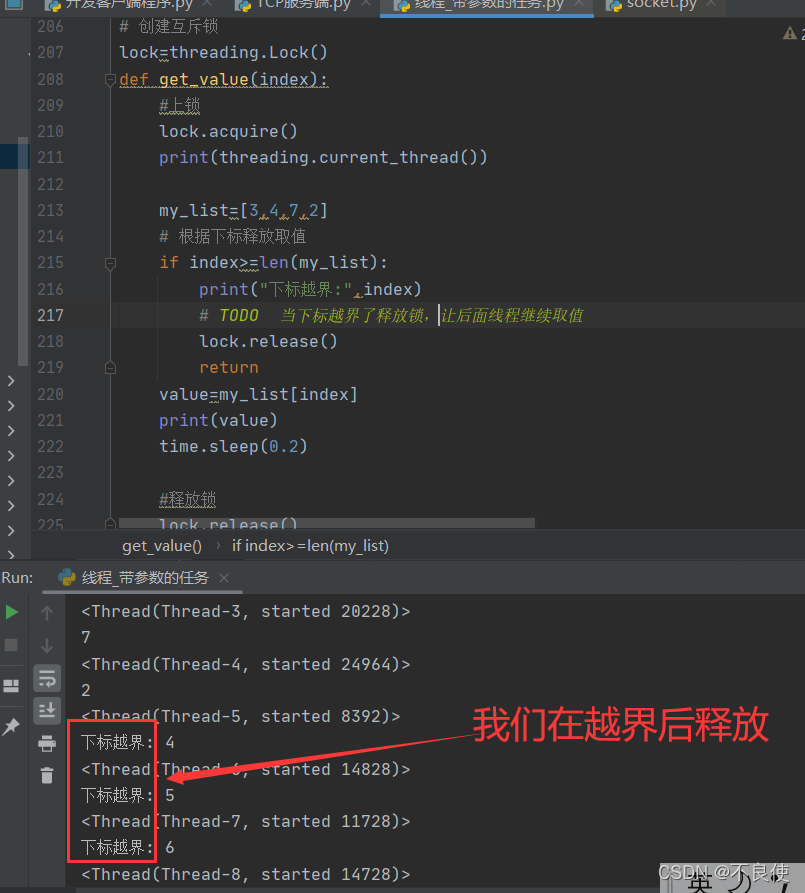
1、因为我们是用方式传参,循环30次,索引0~29。
2、我们会发现我们在判断越界后,因为释放锁所以仍会输出。
3、加入互斥锁解除了死锁危机。
觉得还不错的话就一键三连吧 __^__

- 点赞
- 收藏
- 关注作者
评论(0)