FAQ 问答系统(新冠病毒/寝室)《《让电脑理解我说的话》》------更详细的了解和掌握自然语言知识(不再害怕面试~~~)

【摘要】 💋💋💋**如何让电脑听懂我说的话,或者说看懂我输入的文字,这时候自然语言处理该上台了。**
FAQ 问答系统(新冠病毒/寝室)《《让电脑理解我说的话》》------更详细的了解和掌握自然语言知识(不再害怕面试~~~)
💋💋💋如何让电脑听懂我说的话,或者说看懂我输入的文字,这时候自然语言处理该上台了。
🎁 背景
在当下人力费用还是挺贵的,但是我们只要将所有的问题和答案放在后台或者数据库中,当需要询问 问题的用户在控制台输入需要询问的问题,代码会自己提取到用户输入的文字与数据库或者提前准备的文本中的问题进行相似度计算,最后提取相似度最高的问题的输出给用户。当然,当问题相似度低于一定程度是就会输出无法找到的答案。
😘总结
✨1、人工费高,机器费用低。
✨2、查询问题不再死板,而是通过算法计算相似度。
✨3、复用性高。
✨4、更好的满足用户的需求。
🐱🏍流程图
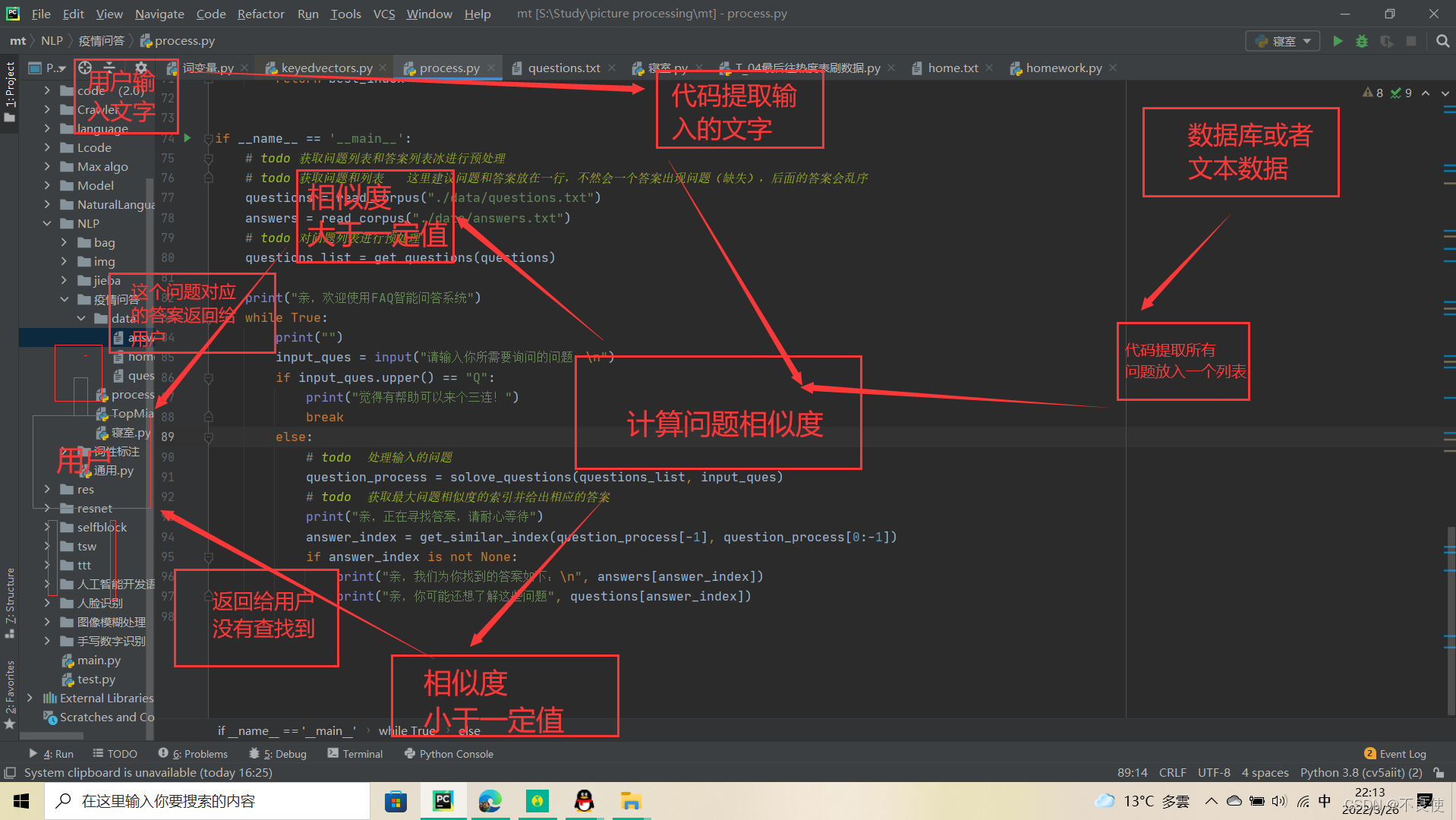
此系统的亮点就是不在像之前只能查询到死问题,就是输入的问题要在后台有100%匹配才返回找到问题并返回答案,途中只要你输错一个符号都是导致匹配失败。此系统不会出现这个问题。
👏新冠病毒的FAQ 问答系统
🚀代码
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
import re
import jieba
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
# todo 格式化代码快捷键 Alt+Ctrl+L
# todo 读取文件
def read_corpus(file):
list = []
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
for i in lines:
list.append(i)
return list
# todo 对问题进行分词、正则化处理
def get_questions(questions):
if len(questions) == 1:
# todo 正则化处理 ,过滤标点符号和无效字符
new_sent = re.sub(r'[^\w]', '', questions[0])
# todo isalnum()用来判断一个字符是否为数字或者字母
new_sent = " ".join(i for i in new_sent if i.isalnum())
new_sent = " ".join(jieba.lcut(new_sent))
return new_sent
else:
question_list = []
for setence in questions:
# todo 正则化处理 ,过滤标点符号和无效字符
new_sent = re.sub(r'^\w', "", setence)
# todo isalnum()用来判断一个字符是否为数字或者字母
new_sent = " ".join(i for i in setence if i.isalnum())
seg_list = " ".join(jieba.lcut(new_sent))
question_list.append(seg_list)
return question_list
# todo 定义函数输入处理输入的问题
def solove_questions(questions_list, input_ques):
# todo 输入问题正则化、jieba分词后加入到问题列表中
questions_list_use = questions_list.copy() # 备份
input_quession = [input_ques]
input_quessions = get_questions(input_quession)
questions_list_use.append(input_quessions)
# todo 用TF-IDF 向量化新的问题列表
vectorizer = TfidfVectorizer(analyzer="char")
vectorizer_relate_question = vectorizer.fit_transform(questions_list_use)
return vectorizer_relate_question
# todo 计算输入问题和列表之间的相似度并选出最大相似度的索引
def get_similar_index(input_ques, questions):
score = []
input_ques = (input_ques.toarray())[0]
for qustion in questions:
qustion = qustion.toarray()
num = float(np.matmul(qustion, input_ques))
# print(num)
demo = np.linalg.norm(qustion) * np.linalg.norm(input_ques)
cos = num / (demo + 1e-3)
score.append(cos)
if max(score) < 0.1:
print("亲,对不起,本FAQ中暂时还没有收录你所提到的问题,我们将会继续改进!")
else:
best_index = score.index(max(score))
return best_index
if __name__ == '__main__':
# todo 获取问题列表和答案列表冰进行预处理
# todo 获取问题和列表 这里建议问题和答案放在一行,不然会一个答案出现问题(缺失),后面的答案会乱序
questions = read_corpus("./data/questions.txt")
answers = read_corpus("./data/answers.txt")
# todo 对问题列表进行预处理
questions_list = get_questions(questions)
print("亲,欢迎使用FAQ智能问答系统")
while True:
print("")
input_ques = input("请输入你所需要询问的问题:\n")
if input_ques.upper() == "Q":
print("觉得有帮助可以来个三连!")
break
else:
# todo 处理输入的问题
question_process = solove_questions(questions_list, input_ques)
# todo 获取最大问题相似度的索引并给出相应的答案
print("亲,正在寻找答案,请耐心等待")
answer_index = get_similar_index(question_process[-1], question_process[0:-1])
if answer_index is not None:
print("亲,我们为你找到的答案如下:\n", answers[answer_index])
print("亲,你可能还想了解这些问题", questions[answer_index])
🚀数据
questions.txt
什么是冠状病毒、新冠病毒和新型冠状病毒?
人类可以感染动物来源的新型冠状病毒吗?
人感染冠状病毒后有什么症状?
目前有针对新型冠状病毒的疫苗吗?
有针对新型冠状病毒的治疗方法吗?
该怎么做才能保护自己?
新冠/新型冠状病毒在普通环境中能存活多久?
新冠/新型冠状病毒肺炎的传播途径是什么?
新冠/新型冠状病毒肺炎潜伏期有多长?
健康人在日常生活中防护应该戴什么样的口罩?
什么样的人群容易感染?
患新冠/新型冠状病毒肺炎有哪些症状?
相关症状如何就医?
有治疗新冠/新型冠状病毒肺炎的特效药吗?
新冠/新冠状病毒在普通环境中能存活多久?
专家说,这个病毒在56℃水中30分钟灭活。100℃开水中,多久灭活?
answer.txt
冠状病毒是一大类病毒,已知会引起疾病,患者表现从普通感冒到重症肺部感染不同,例如中东呼吸综合症(MERS)和严重急性呼吸综合症(SARS)。新型冠状病毒(nCoV)是一种先前尚未在人类中发现的新型冠状病毒,如此次中国武汉的新型冠状病毒2019-nCov。
根据既往详细调查发现,SARS-CoV在2002年从中国的果子狸传播给人类,而MERS-CoV在2012年从单峰骆驼传播到沙特阿拉伯人。另外有几种已知的冠状病毒在动物中传播流行,但尚未感染人类的。随着世界范围内监视的改善,可能会发现更多的冠状病毒。
症状取决于感染病毒的种类,但常见的症状包括呼吸道症状,发热、咳嗽、呼吸急促和呼吸困难。在更严重的情况下,感染会导致肺炎,严重的急性呼吸道综合症,肾衰竭甚至死亡。
新发疾病需要时间才能研发出接种的疫苗,而开发新疫苗可能需要数年时间。
对于由新型冠状病毒引起的疾病,没有特效的治疗方法。但是,许多症状都可以治疗,因此可以根据患者的临床状况进行治疗。此外,对感染者的支持治疗可能非常有效。
多种疾病的减少暴露和传播的标准建议包括保持基本的手和呼吸道卫生,以及安全的饮食习惯,并在可能的情况下避免与表现出呼吸道疾病症状(例如咳嗽和打喷嚏)的人密切接触。
新型冠状病毒室温下的存活时间目前仍不清楚。现有的认知多来自对SARS-CoV(SARS冠状病毒)和MERS-CoV(MERS冠状病毒)的研究,冠状病毒对紫外线和热敏感,56℃ 30 分钟、乙醚、75%乙醇、含氯消毒剂、过氧乙酸和氯仿等脂溶剂均可有效灭活病毒。
经呼吸道飞沫和接触传播是主要的传播途径,大家去公共场所一定要戴口罩和勤洗手。气溶胶和消化道等传播途径尚待明确。
目前的流行病学调查显示,潜伏期为1-14天,多为3-7天。
戴医用外科口罩已经可以起到很好的防护作用,一般不必要戴N95防护口罩。
目前的研究结果表明,人群普遍易感。
早期多数患者以发热、乏力、干咳为主要表现。少数患者伴有鼻塞、流涕、咽痛和腹泻等症状。重症患者可出现呼吸困难和/或低氧血症等严重表现。
建议就近前往定点医院的发热门诊就诊。
目前没有确认有效的抗病毒治疗方法。国家卫健委新型冠状病毒感染的肺炎诊疗方案(试行第五版)推荐的α-干扰素雾化吸入、洛匹那韦/利托那韦等可以试用。目前已经有近三十项新型冠状病毒感染的肺炎临床试验注册,并同步开展相关的临床研究,希望能取得好的结果用于本病治疗。
病毒只能存活于生物体细胞内,室温情况下基本不能存活。
病毒仅在动物体内存活,体外不能存活,所以物品不用煮。
该病毒不是消化道传播的,摸了门把手、手机,不去抠鼻子、摸眼睛就行。病毒离开
这些数据足以出现不错的结果,如果想需要更多的测试集可以私聊我或者直接下载 测试数据
🚀截图:
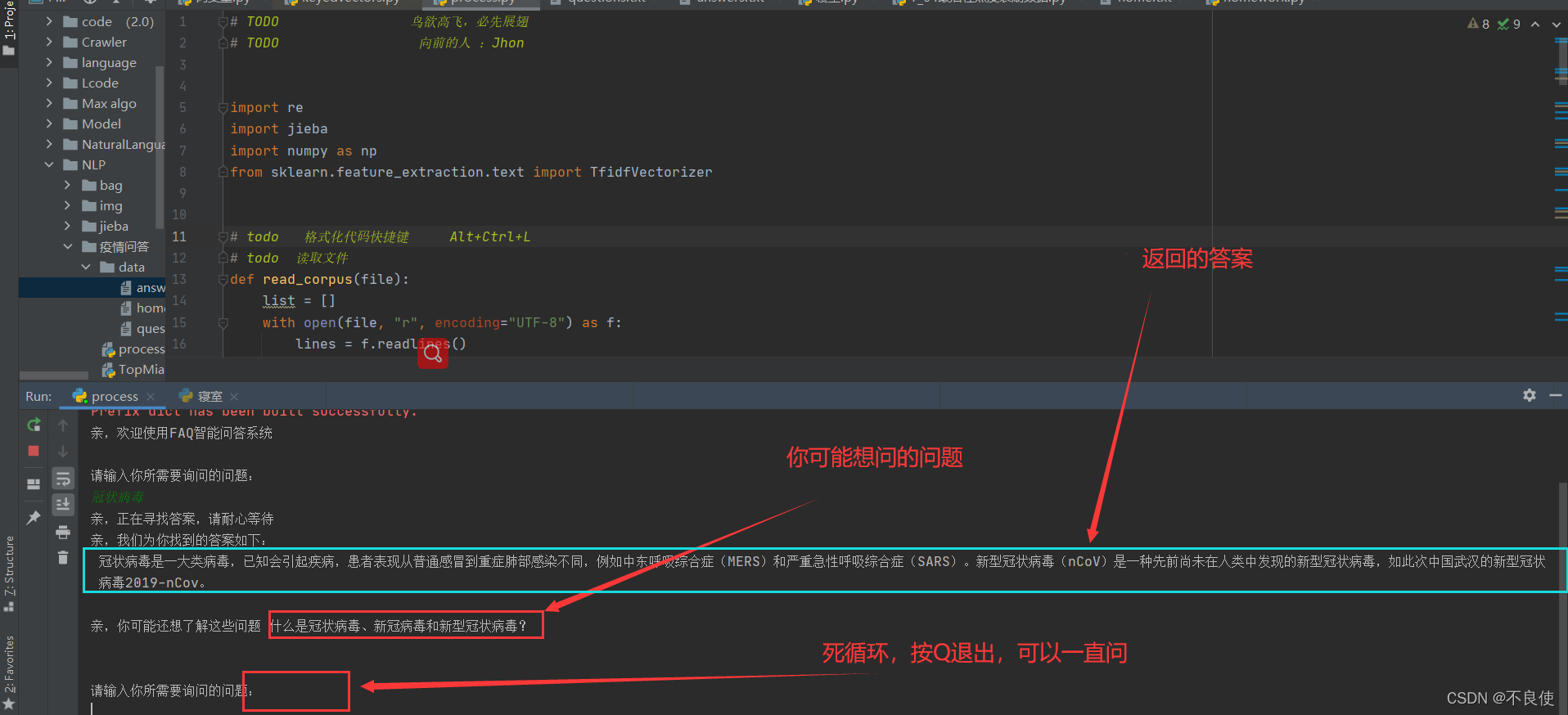
此系统的亮点就是不在像之前只能查询到死问题,就是输入的问题要在后台有100%匹配才返回找到问题并返回答案,途中只要你输错一个符号都是导致匹配失败。此系统不会出现这个问题。
👏寝室的的FAQ 问答系统
🛴代码
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
import re
import jieba
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
# todo 格式化代码快捷键 Alt+Ctrl+L
# todo 读取文件
def read_corpus(file):
list_questions = []
list_answers=[]
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
for i in lines:
txt = re.split(':', i)
list_questions.append(txt[0])
list_answers.append(txt[1])
return list_questions,list_answers
# todo 对问题进行分词、正则化处理
def get_questions(questions):
if len(questions) == 1:
# todo 正则化处理 ,过滤标点符号和无效字符
new_sent = re.sub(r'[^\w]', '', questions[0])
# todo isalnum()用来判断一个字符是否为数字或者字母
new_sent = " ".join(i for i in new_sent if i.isalnum())
new_sent = " ".join(jieba.lcut(new_sent))
return new_sent
else:
question_list = []
for setence in questions:
# todo 正则化处理 ,过滤标点符号和无效字符
# new_sent = re.sub(r'^\w', "", setence)
# todo isalnum()用来判断一个字符是否为数字或者字母
new_sent = " ".join(i for i in setence if i.isalnum())
seg_list = " ".join(jieba.lcut(new_sent))
question_list.append(seg_list)
return question_list
# todo 定义函数输入处理输入的问题
def solove_questions(questions_list, input_ques):
# todo 输入问题正则化、jieba分词后加入到问题列表中
questions_list_use = questions_list.copy() # 备份
input_quession = [input_ques]
input_quessions = get_questions(input_quession)
questions_list_use.append(input_quessions)
# todo 用TF-IDF 向量化新的问题列表
vectorizer = TfidfVectorizer(analyzer="char")
vectorizer_relate_question = vectorizer.fit_transform(questions_list_use)
return vectorizer_relate_question
# todo 计算输入问题和列表之间的相似度并选出最大相似度的索引
def get_similar_index(input_ques, questions):
score = []
input_ques = (input_ques.toarray())[0]
for qustion in questions:
qustion = qustion.toarray()
num = float(np.matmul(qustion, input_ques))
demo = np.linalg.norm(qustion) * np.linalg.norm(input_ques)
cos = num / (demo + 1e-3)
score.append(cos)
if max(score) < 0.1:
print("亲,对不起,本FAQ中暂时还没有收录你所提到的问题,我们将会继续改进!")
else:
best_index = score.index(max(score))
return best_index
if __name__ == '__main__':
# todo 获取问题列表和答案列表冰进行预处理
# todo 获取问题和列表 这里建议问题和答案放在一行,不然会一个答案出现问题(缺失),后面的答案会乱序
questions,answers=read_corpus("./data/home.txt")
# print(questions)
# print("*"*66)
# print(answers)
# todo 对问题列表进行预处理
questions_list = get_questions(questions)
print("亲,欢迎使用FAQ智能问答系统")
while True:
print("")
input_ques = input("请输入你所需要询问的问题:\n")
if input_ques.upper() == "Q":
print("觉得有帮助可以来个三连!")
break
else:
# todo 处理输入的问题
question_process = solove_questions(questions_list, input_ques)
# todo 获取最大问题相似度的索引并给出相应的答案
print("亲,正在寻找答案,请耐心等待")
answer_index = get_similar_index(question_process[-1], question_process[0:-1])
if answer_index is not None:
print("亲,我们为你找到的答案如下:\n", answers[answer_index])
print("亲,你可能还想了解这些问题", questions[answer_index])
🛴数据
寝室卫生怎么保持:多扫地
寝室怎么和谐:互相分享食物
寝室怎么保证没有违规电器:一起使用违规电器,一起写检讨
寝室几点关灯:12点
寝室违规电器:一起用
寝室违规电器怎么解决:感觉解决不了
寝室为什么会有违规电器:因为想吃自己做的饭
寝室为什么不能有违规电器:可能学校怕违规电器短路着火吧
寝室为什么还有违规电器:漏网之鱼太多太多
🛴结果
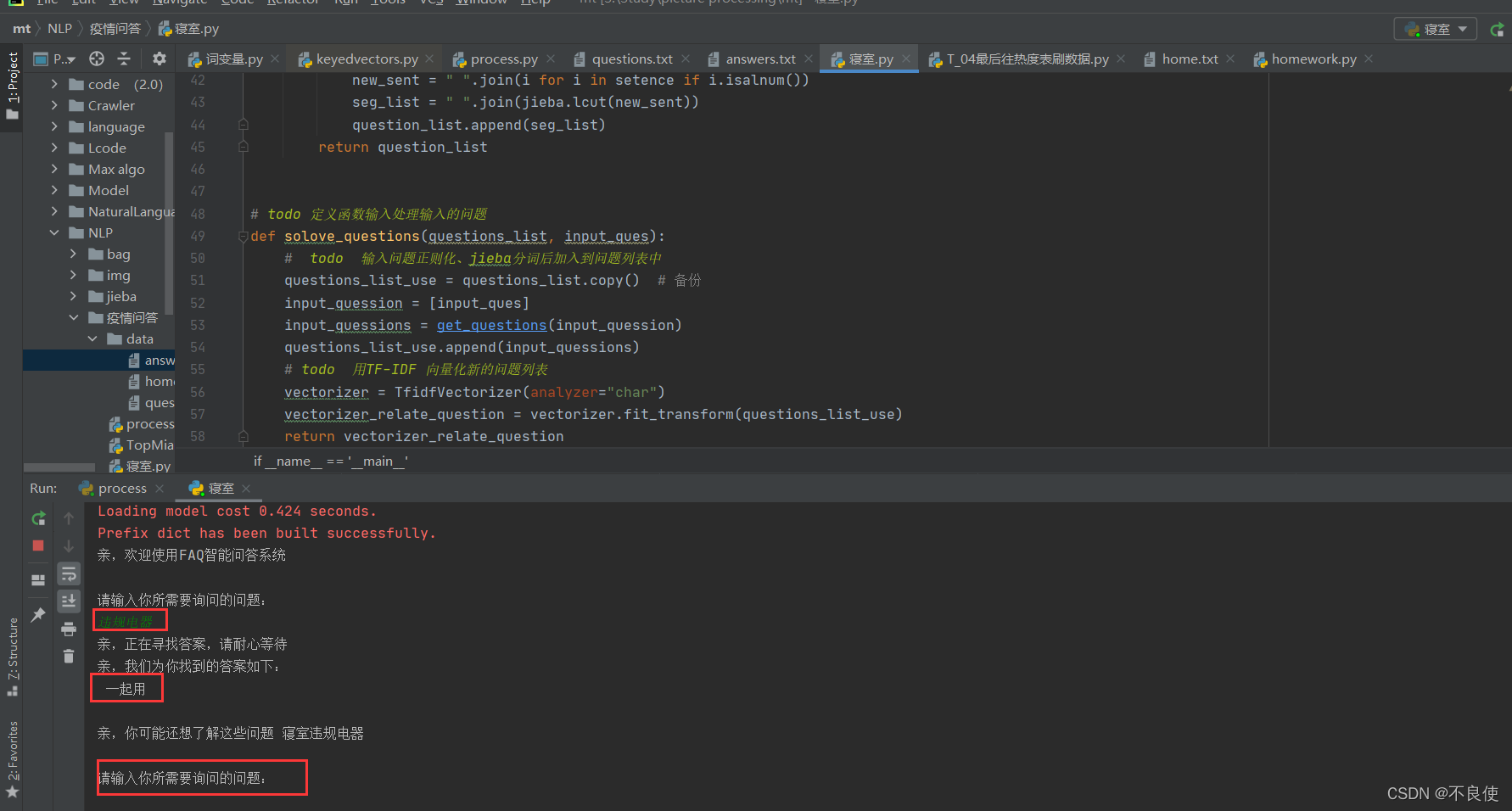
我们可以发现这个和之前的除了题库基本上没什么两样,但是如果你比较细心的话你就会发现这个的问题和答案是在一行的,在一个文本中的,不是分开的。这样的好处是避免因为读取数据而出现的乱序。
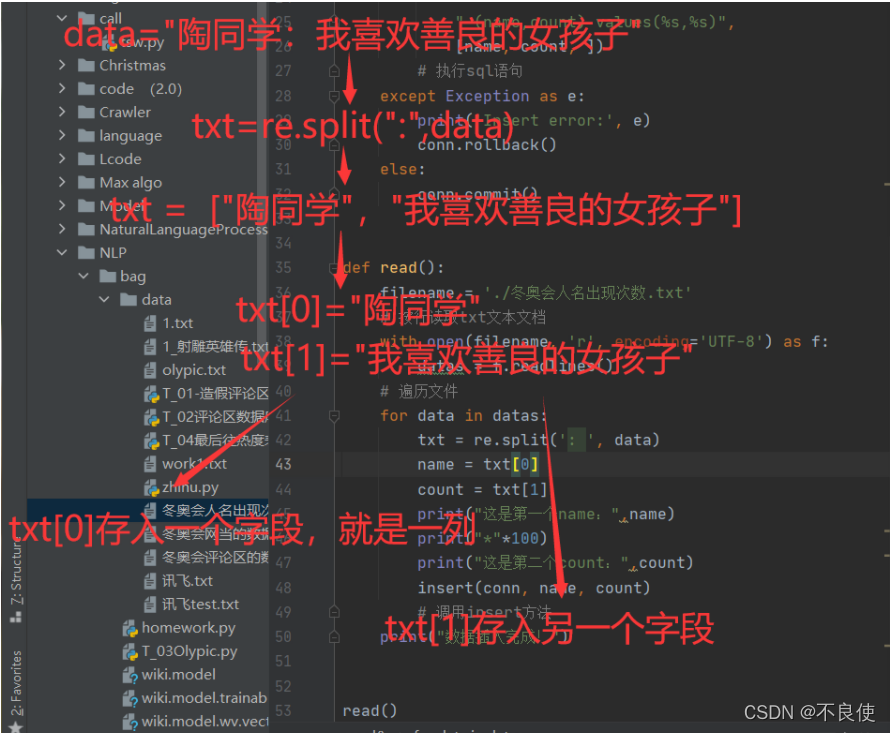
def read_corpus(file):
list_questions = []
list_answers=[]
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
for i in lines:
txt = re.split(':', i)
list_questions.append(txt[0])
list_answers.append(txt[1])
return list_questions,list_answers
redlines一行行的读,split通过中文的冒号将一行切为两端,然后前后两端分别存进不同的列表中,return 返回两个列表给后面使用。
想要很好的split可以访问下面文章
split+数据库
觉得有用的可以给个三连,关注一波!!!带你了解更多的自然语言处理小知识

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)