R Bagging & Boosting详解

@[TOC](Bagging & Boosting详解)
1 弱学习器和强学习器
弱学习器:分类不够精确
强学习器:分类精确
在机器学习领域中,关键的问题就是如何利用观测数据通过学习得到精确估计。
目前,随着计算机硬件技术的迅猛发展,学习准确率比运算速度显得更为重要。但是,在实际应用领域中,构造一个高精度的估计几乎是不可能的。
实际运用中,人们根据生产经验可以较为容易的找到弱学习方法,但是很多情况下要找到强学习方法是不容易的。有时候人们倾向于通过先找到弱学习然后把它转换为强学习的方式获取强学习方法,而Valiant证明了这种方式的可行性。
怎样实现弱学习转为强学习
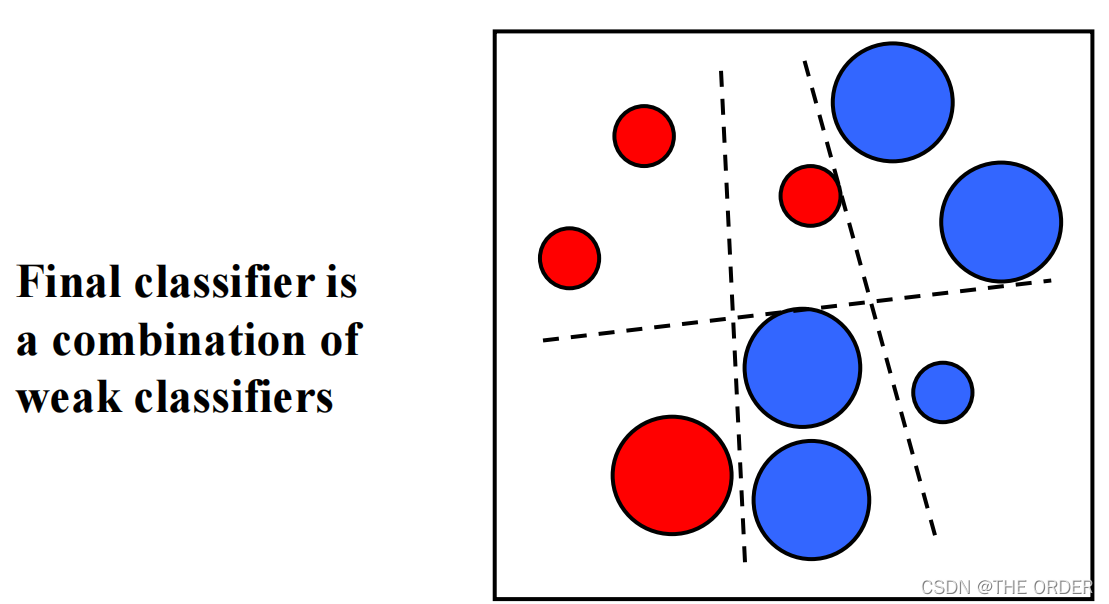
核心思想:通过组合使弱学习互补。
学习是不适定问题,在有限的样本上,不同的学习方法得到不同的“规则”,并在不同的情况下失效,没有一种学习算法总是在任何领域产生最好的分类效果。
例如:学习算法A在a情况下失效,学习算法B 在b情况下失效,那么在a情况下可以用B算法,
在b情况下可以用A算法解决。这说明通过某种合适的方式把各种算法组合起来,可以提高准确率。
为实现弱学习互补,面临两个问题:
(1)怎样获得不同的弱分类器?
(2)怎样组合弱分类器?
(1)怎样获得不同的弱分类器使用不同的弱学习算法得到不同基学习器
参数估计、非参数估计…
使用相同的弱学习算法,但用不同的超参数K-Mean不同的K,神经网络不同的隐含层… 使用不同的训练集
装袋(bagging)
提升(boosting)
(2)怎样组合弱分类器
多专家组合
一种并行结构,所有的弱分类器都给出各自的预测结
果,通过“组合器”把这些预测结果转换为最终结果。
eg.投票(voting)及其变种、混合专家模型
多级组合
一种串行结构,其中下一个分类器只在前一个分类器
预测不够准(不够自信)的实例上进行训练或检测。
eg. 级联算法(cascading)
bagging在给定样本上随机抽取(有放回)训练子集,在每个训练子
集上用不稳定的学习算法训练分类不同弱分类器。
boosting在前一个弱分类器错分的实例在后续的弱分类器上得到更大
的重视。 从训练子集的获取方式上看:
bagging靠“运气”,boosting有“依 据”!
所谓不稳定学习算法是指训练集很小的变化会引起所产生的分类器变化很大,即学习算法高方差。
例如,决策树。
Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合 为一个分类器的方法,即boostrapping方法和bagging方法。
2 Bagging
基本思想:
给定一个弱学习算法,和一个训练集;
单个弱学习算法准确率不高;
将该学习算法使用多次,得出预测函数序列,进行
投票; 最后结果准确率将得到提高
算法:
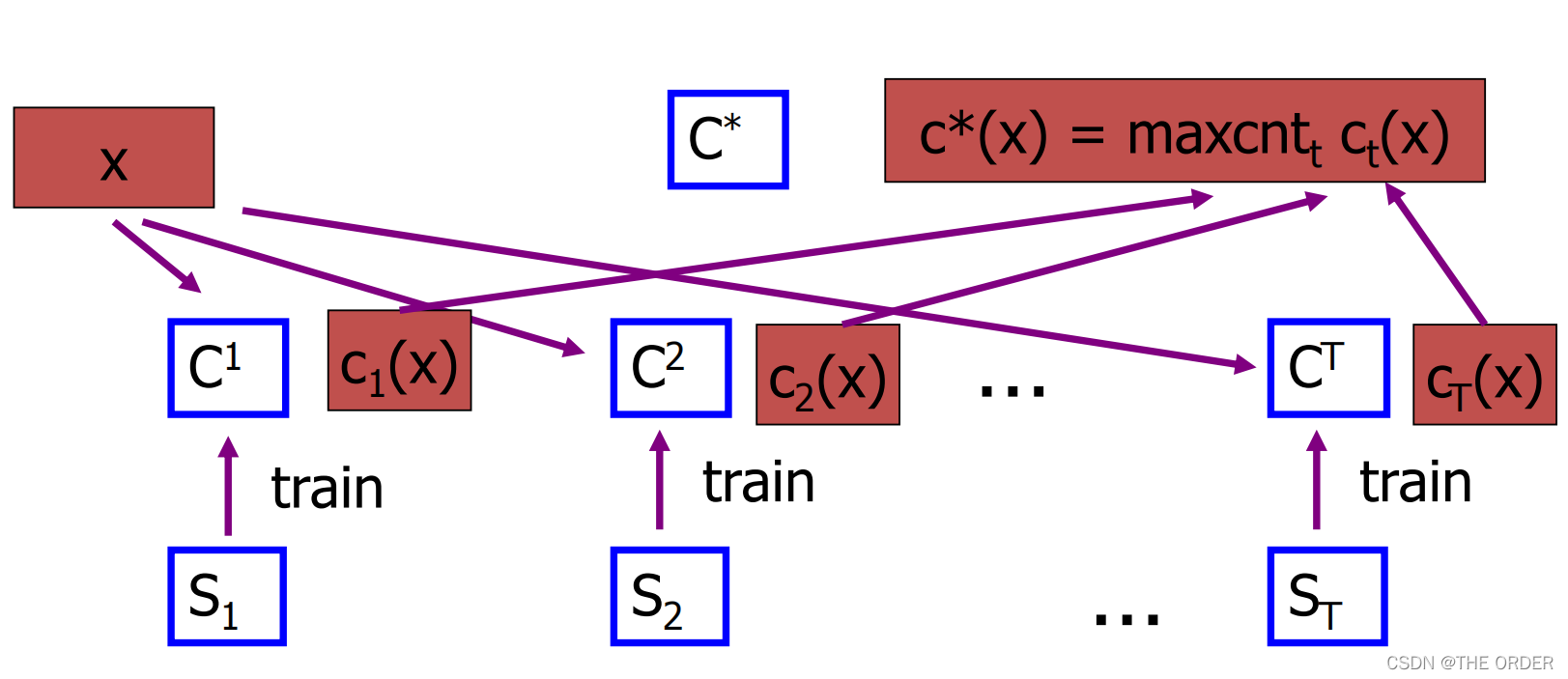
For t = 1, 2, …, T Do 从数据集S中取样(放回选样)
训练得到模型Ht, 对未知样本X分类时,每个模型Ht都得出一个分类,
得票最高的即为未知样本X的分类,也可通过得票的平均值用于连续值的预测
Bagging
3 Boosting
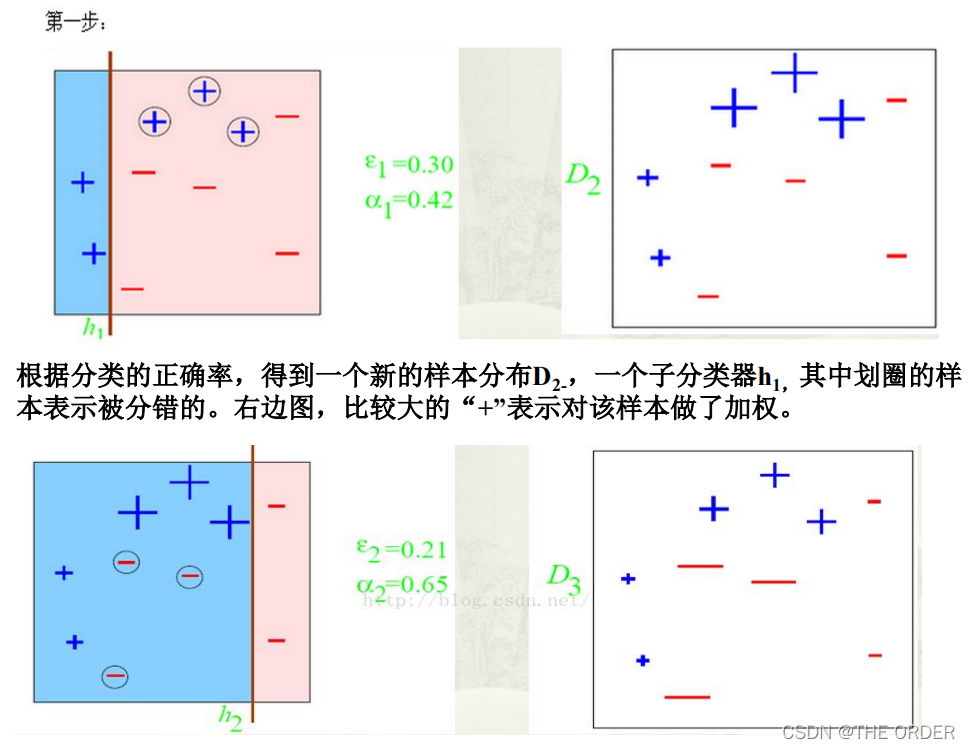
基本思想:
每个样本都赋予一个权重T次迭代,每次迭代后,对分类错误的样本加大
权重,使得下一次的迭代更加关注这些样本。
首先给出任意一个弱学习算法和训练集 (x1 , y1 ) , ( x2 , y2 ) , ⋯, ( xn ,
yn ) , xi ∈X, X 表示某个实例空间,在分类问题中是一个带类别标志的集合,
yi∈Y = { + 1, - 1}。
初始化时, Adaboost为训练集指定分布为1 /n, 即每个训练例的权重都相
同为1 /n。
接着,调用弱学习算法进行T 次迭代,每次迭代后, 按照训练结果更新训练
集上的分布,对于训练失败的训练例赋予较大的权重,使得下一次迭代更加关
注这些训练例,从而得到一个预测函数序列h1 , h2 , ⋯, ht ,每个预测函数ht 也
赋予一个权重, 预测效果好的, 相应的权重越大。
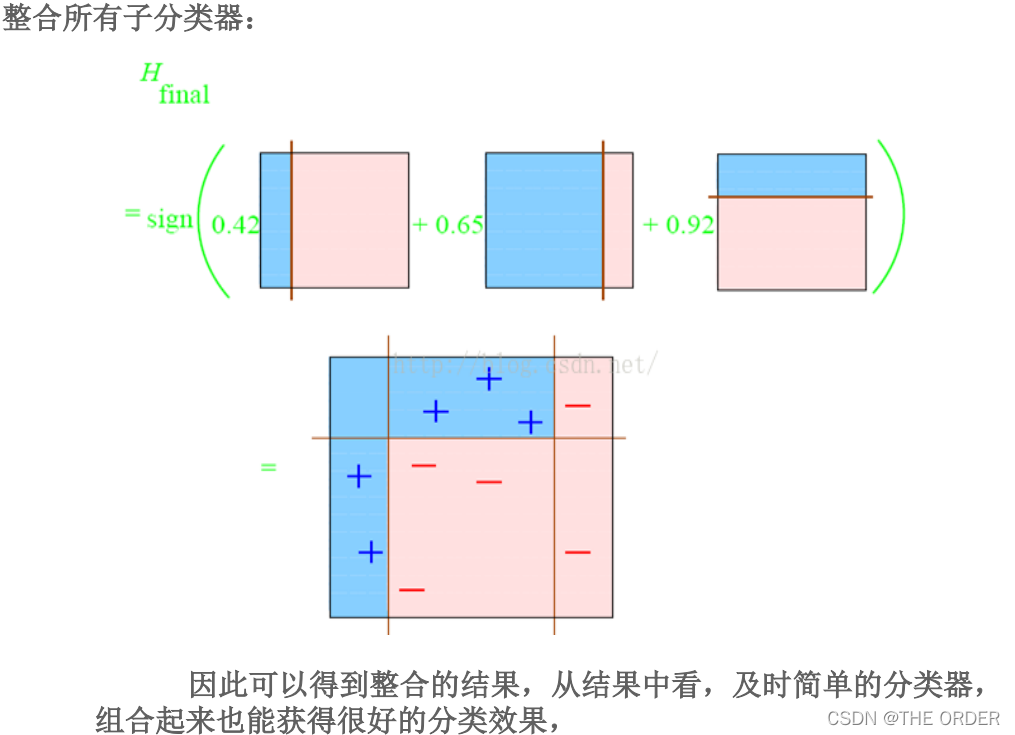
T 次迭代之后,在分类问题中最终的预测函数 H 采用带权重的投票法产
生。
单个弱学习器的学习准确率不高,经过运用 Boosting 算法之后,最终结果
准确率将得到提高。
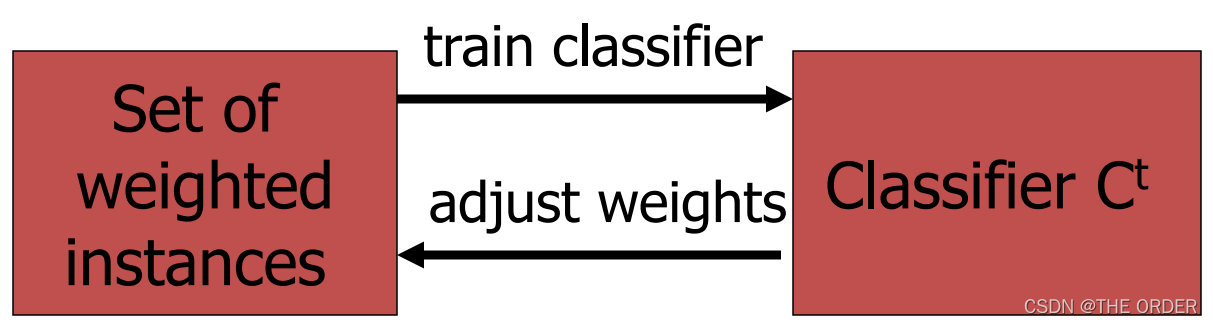
过程:
在一定的权重条件下训练数据,得出分类法Ct
根据Ct的错误率调整权重
AdaBoost的核心思想
“关注”被错分的样本,“器重”性能好的弱分类器 怎么实现
(1)不同的训练集调整样本权重
(2)“关注”增加错分样本权重
(3)“器重”好的分类器权重大
(4)样本权重间接影响分类器权重
核心思想
样本的权重
没有先验知识的情况下,初始的分布应为等概分布,也就是训练集如
果有N个样本,每个样本的分布概率为1/N
每次循环后提高错误样本的分布概率,分错样本在训练集中所占权重
增大, 使得下一次循环的弱学习机能够集中力量对这些错误样本进行
判断。
弱学习机的权重
准确率越高的弱学习机权重越高
循环控制:损失函数达到最小
在强学习机的组合中增加一个加权的弱学习机,使准确率提高,损失
函数值减小。








理论分析–最优化

The AdaBoost Algorithm


AdaBoost特性分析
特性1: 训练误差的上界,随着迭代次数的增加,会逐渐下降。
特性2: adaboost算法即使训练次数很多,也不会出现过度拟合
(over fitting)的问题。
AdaBoost特性分析

AdaBoost特性分析





Boosting其它应用
Boosting易受到噪音的影响;
AdaBoost 可以用来鉴别异常;
具有最高权重的样本即为异常.
Bagging 和boosting的区别
训练集: Bagging:随机选择,各轮训练集相互独立
Boosting:各轮训练集并不独立,它的选择与前轮的学习结
果有关
预测函数: Bagging:没有权重;可以并行生成
Boosting:有权重;只能顺序生成
很多实验与实践证明:
Boosting比Bagging效果更好!!!
文本分类
AdaBoost (weak learner: NB, C4.5等)
排序学习
RankBoost
4 R实现boosting权重计算
第一次boosting划分的误差和权重
#first
n=10
d=1/n
a=0.5*log((1-e)/e)
e=0.3
对分类正确的和错误的重新计算权重
#for T
dit1=d*exp(-1*a)
#for f
dif1=d*exp(a)
z1=7*dit1+3*dif1
z1
第二次划分的类型分为二次正确,一次正确,一次正确一次错误三种情况和权重的计算
#second
e1=3*dit1/z1
e1
w1=0.5*log((1-e1)/e1)
w1
dit2t=dit1*exp(-1*w1)
dit2f=dif1*exp(-1*w1)
dif2=dit1*exp(w1)
z2=4*dit2t+3*dit2f+3*dif2
z2
第三次的错误数量和权重
#third
e3=3*dit2t/z2
e3
a3=0.5*log((1-e3)/e3)
a3

- 点赞
- 收藏
- 关注作者
评论(0)