R 决策树

1 数据分类
分类的过程
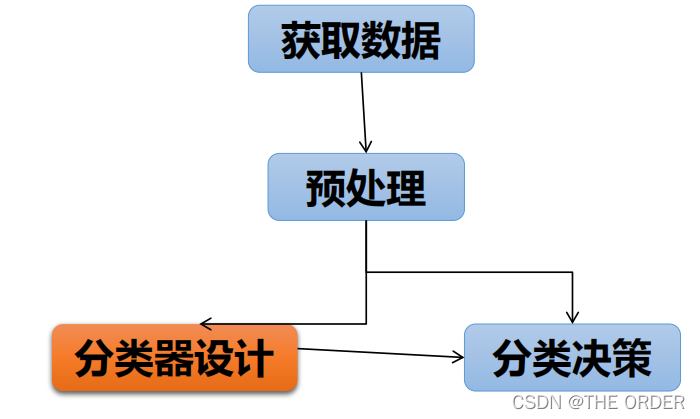
2 获取数据
数值型数据
• 病例中的各种化验数据
• 空气质量监测数据
描述性数据
• 人事部门档案资料
图片型数据
• 指纹、掌纹
• 自然场景图片
• 很多情况下,需要将上述数据统一转换为数值型数据序列,即
形成特征向量(特征提取)
3 预处理
为了提高分类的准确性和有效性,需要对分类所用的数据进行
预处理
• 去除噪声数据
• 对空缺值进行处理
• 数据降维(特征选择)–(PCA、LDA)
主成分分析 ( Principal Component Analysis , PCA )
线性鉴别分析(Linear Discriminant Analysis, LDA),有时也称Fisher线性
判别(Fisher Linear Discriminant ,FLD), 这种算法是Ronald Fisher 于 1936年发明的,是模式识别的经典算法。
4 分类器设计
1-划分数据集
• 给定带有类标号的数据集,并且将数据集划分为两个部分
• 训练集(training set) • 测试集(testing set) • 划分策略
1.当数据集D的规模较大时 ,训练集2|D|/3,测试集是1|D|/3
2.当数据集D的规模不大时,n交叉验证法(n-fold validation) • 将数据集随机地划分为n组 • 之后执行n次循环,在第i次循环中,将第i组数据样本作为测试集,其余的n-1组数据样本作为训练集,最终的精度为n个精度的平均值。
3.当数据集D的规模非常小时
每次交叉验证时,只选择一条测试数据,剩余的数据均作为训练集。
• 原始数据集有m条数据时,相当于m-次交叉验证。
• 是N-次交叉验证的一个特例。
分类器设计2-分类器构造
利用训练集构造分类器(分类模型)
• 通过分析由属性描述的每类样本的数据信息,从中总结出分类的规律性,建立判别公式或判别规则
• 在分类器构造过程中,由于提供了每个训练样本的类标号,这一步也称作监督学习(supervised learning)
分类器设计3-分类器测试
• 利用测试集对分类器的分类性能进行评估,具体方式是
• 首先,利用分类器对测试集中的每一个样本进行分类
• 其次,将分类得到的类标号和测试集中数据样本的原始类标号进行对比
• 由上述过程得到分类器的分类性能
在构造成功分类器之后(通过测试),则可以利用该分类器实
际执行分类
5 分类模型的评价
模型算法质量的评价是很重要的一部分。对分类模型和聚类模型的评价方法是不同的。
• 对于分类模型,通常用一些指标来进行模型评价和选择。通常采用的指标有: ROC曲线、Lift曲线。其本质都是与预测的准确性有关的。
• 分类模型评价的主要宗旨就是:减少误判(假阳性)和漏判(假阴性)。
• 我们可以对不同的分类算法,设置不同的参数,进行反复比较,根据在多个效果指标(比如ROC曲线的AUC值、Lift曲线)上是否有稳定的好的表现,选择一个最终落地应用的模型。
精确度(accuracy) • 是最常用的评价准则
• 代表测试集中被正确分类的数据样本所占的比例
• 反映了分类器对于数据集的整体分类性能
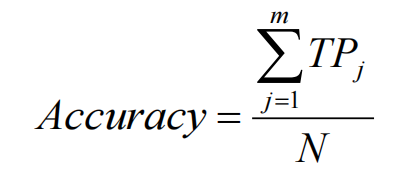
查全率(recall)
第j个类别的查全率(召回率)表示在本类样本中,被正确
分类的样本占的比例
代表该类别的分类精度

查准率(precision) • 第j个类别的查准率表示被分类为该类的样本中,真正属于
该类的样本所占的比例
• 代表该类别的分类纯度

• F-measure
• 可以比较合理地评价分类器对每一类样本的分类性能
• 它是查全率和查准率的组合表达式
• 其中参数β是可以调节的,通常取值为1
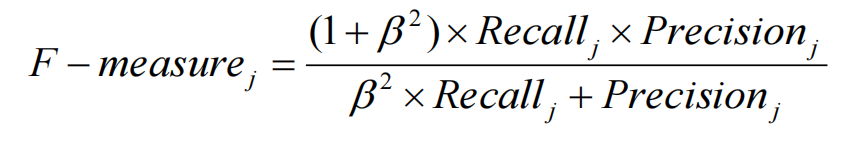
几何均值(G-mean)
• 它能合理地评价数据集的整体分类性能
• 是各个类别查全率的平方根,当各个类别的查全率都大时才
增大
• 同时兼顾了各个类别的分类精度
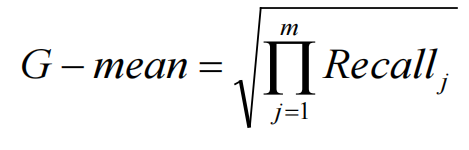
6 什么是决策树?
决策树(Decision Tree),又称为判定树,是数据挖掘技术中的一种重要的分类方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。
通过把实例从根节点排列到某个叶子节点来分类实
例; 叶子节点即为实例所属的分类;
树上每个节点说明了对实例的某个属性的测试节点的每个后继分支对应于该属性的一个可能值。
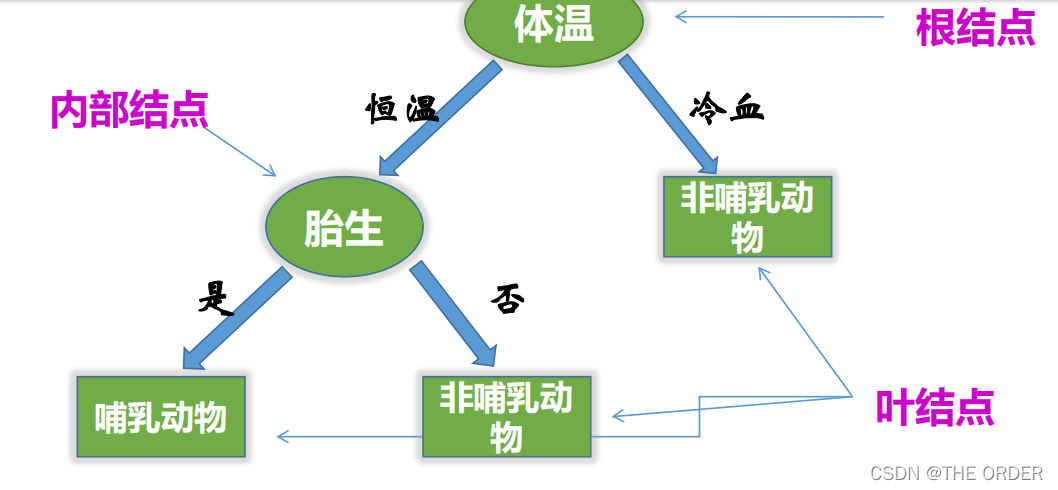
决策树形式
决策树主要有二元分支(binary split)树和多分支
(multiway split)树。一般时候采用二元分裂,因为二元
分裂在穷举搜索中更加灵活

7 决策树的构造
决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。
所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
决策树基本概念
一棵决策树是一棵有向无环树,它由若干个节点、分支、分裂谓词以及类别组成。
节点是一棵决策树的主体。其中,没有父亲节点的节点称为根节点;没有子节点的节点称为叶子节点。
一个节点按照某个属性分裂时,这个属性称为分裂属性。
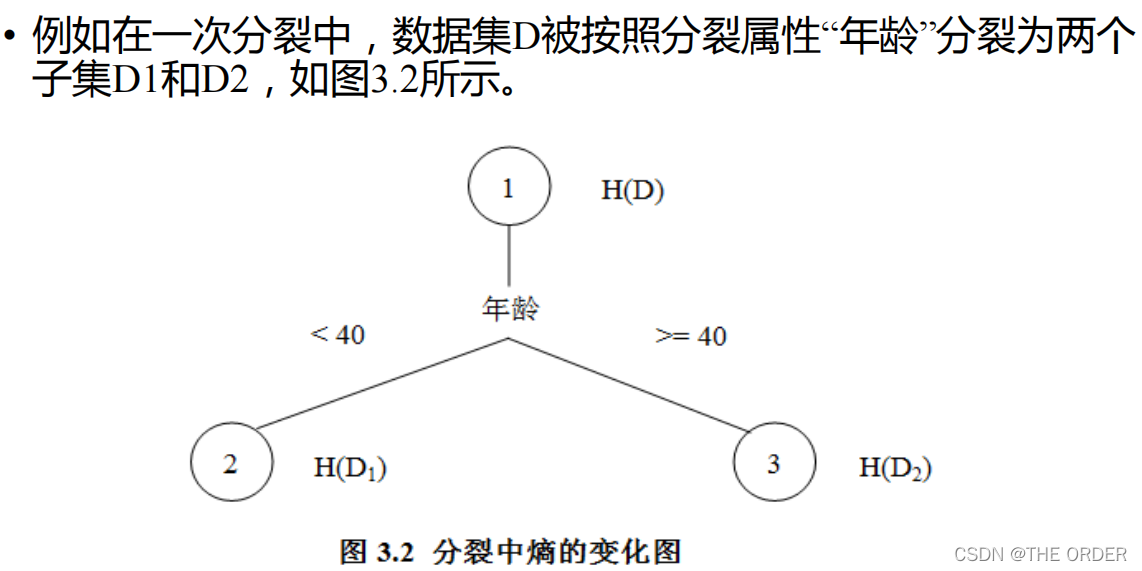
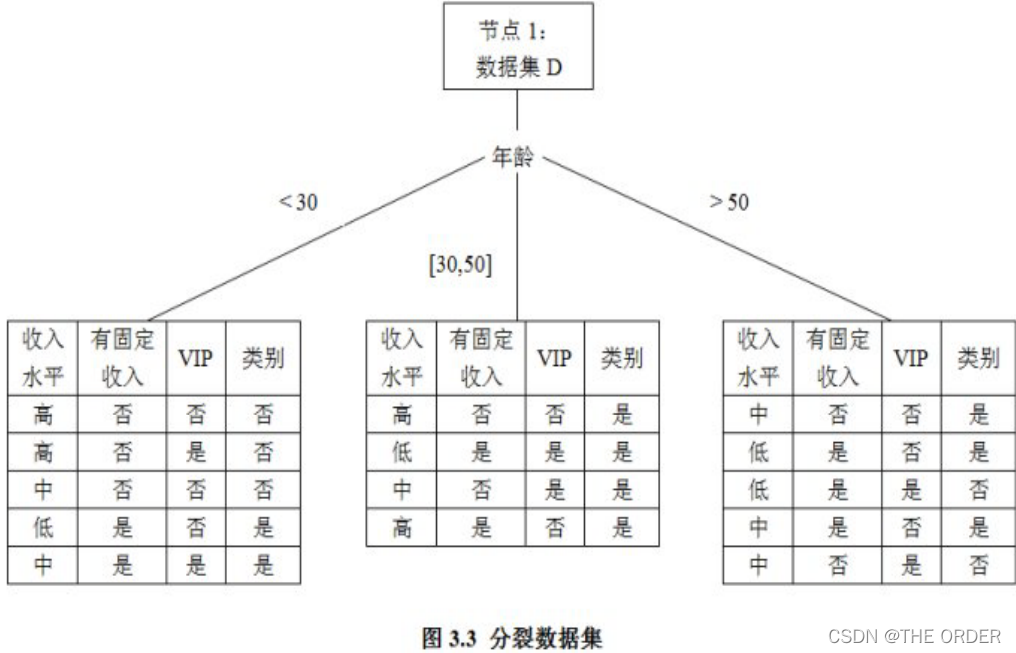
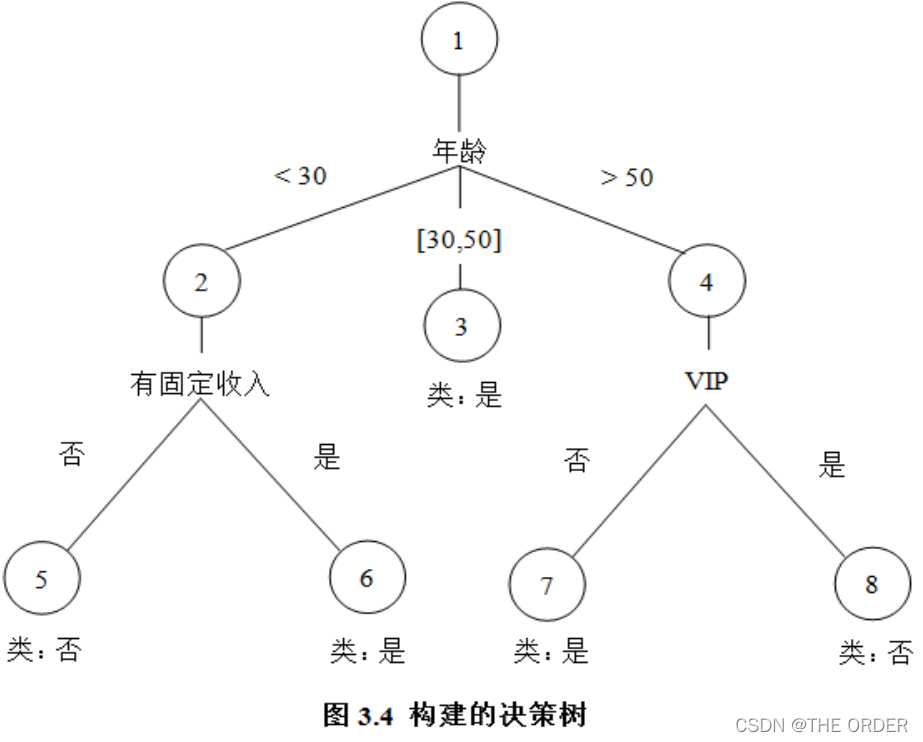
每一个分支都会被标记一个分裂谓词,这个分裂谓词就是分裂父节点的具体依据,例如在将节点1分裂时,产生两个分支,对应的分裂谓词分别是“年龄<40”和“年龄>=40”。
另外,每一个叶子节点都被确定一个类标号,这里是“优”、“良”或者“差”。

由此可以看出,构建一棵决策树,关键问题就在于,如何选择一个合适的分
裂属性来进行一次分裂,以及如何制定合适的分裂谓词来产生相应的分支。
各种决策树算法的主要区别也正在于此
属性选择度量

修剪决策树

生成规则
• 在生成一棵最优的决策树之后,就可以根据这棵决策树来生成一系列
规则。 • 这些规则采用“If…,Then…”的形式。从根节点到叶子节点的每一条路径,都
可以生成一条规则。这条路径上的分裂属性和分裂谓词形成规则的前件(If
部分),叶子节点的类标号形成规则的后件(Then部分)。
常用算法
ID3算法是最有影响力的决策树算法之一,由Quinlan提出。
D3算法的某些弱点被改善之后得到了C4.5算法;
C5.0则进一步改进了C4.5算法,使其综合性能大幅度提高。
但由于C5.0是C4.5的商业版本,其算法细节属于商业机密,因此没有被公开,
ID3算法
任何一个决策树算法,其核心步骤都是为每一次分裂确定一个分裂属性,即究竟按照哪一个属性来把当前数据集划分为
若干个子集,从而形成若干个“树枝”。
ID3算法采用“信息增益”为度量来选择分裂属性的。哪个属性
在分裂中产生的信息增益最大,就选择该属性作为分裂属性。
信息量的度量
当获取信息时,将不确定的内容转为确定的内容,因此信息伴着
不确定性。
从直觉上讲,小概率事件比大概率事件包含的信息量大。
如果某件事情是“百年一见”则肯定比“习以为常”的事件包含
的信息量大。
如何度量信息量的大小?
信息量的度量—–熵

ID3 –信息量大小的度量




ID3算法流程
ID3算法是一个从上到下、分而治之的归纳过程。
• ID3算法的核心是:在决策树各级节点上选择分裂属性时,通过计算信息增益来选择属性,以使得在每一个非叶节点进行测试
时,能获得关于被测试样本最大的类别信息。
• 其具体方法是:检测所有的属性,选择信息增益最大的属性产生决策树节点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树节点的分支,直到所有子集仅包括同一类别的数据为止。
• 最后得到一棵决策树,它可以用来对新的样本进行分类。




ID3 算法优缺点

C4.5算法



信息增益(Information Gain)


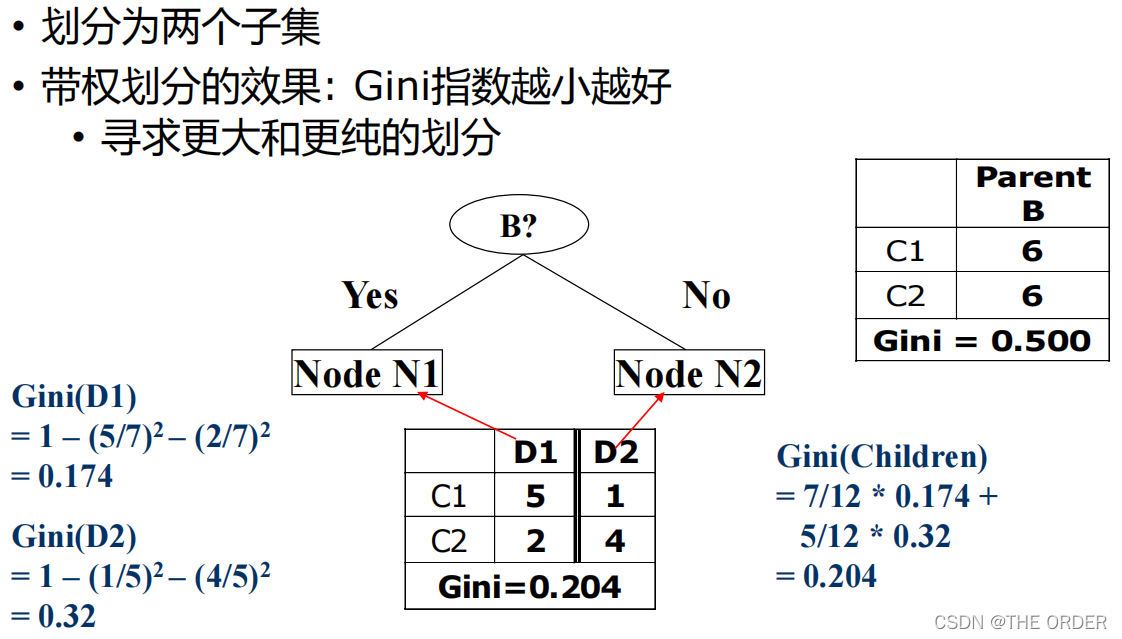
Gini指数


二值属性的Gini指数

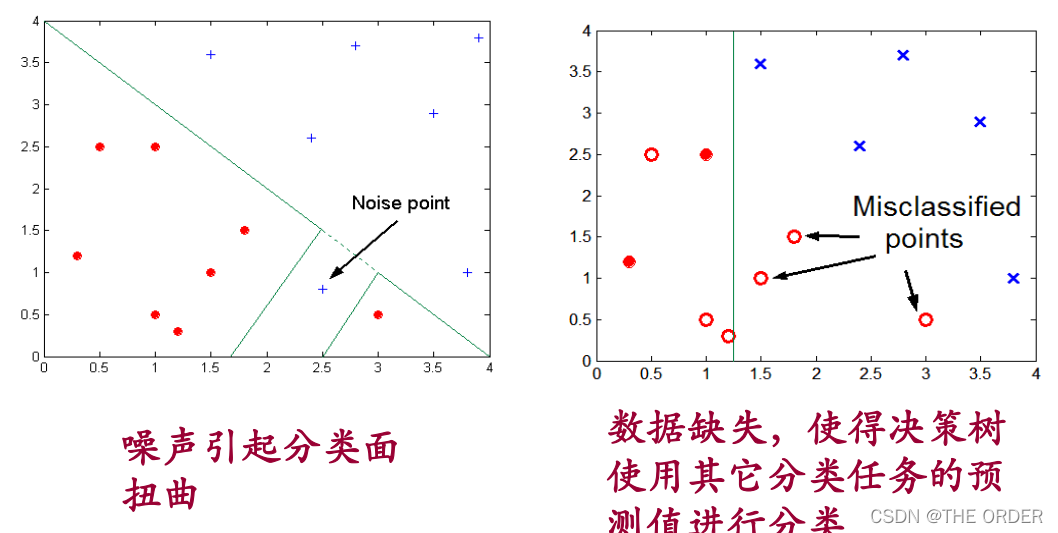
过拟合现象(Overfitting)
• 分支太多,由噪声或孤立点产生异常
• 分类未见数据时精度低
关于过渡拟合
分类模型的误差
一般可以将分类模型的误差分为:
1、训练误差(Training Error);
2、泛化误差(Generalization Error)
关于过渡拟合
模型过渡拟合的潜在因素
(1)噪声导致的过渡拟合; 错误的类别值/类标签,属性值等
(2)缺乏代表性样本所导致的过渡拟合 根据少量训练记录作出的分类决策模型容易受过渡拟合的 影响。由于训练样本缺乏代表性的样本,在没有多少训练 记录的情况下,学习算法仍然继续细化模型就会导致过渡拟合。
关于过渡拟合
1 及早停止树增长
由于决策树学习要从候选集合众选择满足给定标准的最大化属性,并且不回溯,也就是我们常说的爬山策略,其选择往往会是局部最优而不是全局最优。树结构越复杂,则
过渡拟合发生的可能性越大。因此,要选择简单的模型。Occan法则(又称Occan剃刀 Occan Razor):具有相同泛化误差的两个模型,较简单的模型比复杂的模型更可取。
后修剪法(后剪枝法)
在训练过程中允许对数据的过渡拟合,然后再对树进行修剪该方法称为后剪枝法。
8 R语言实现
准备相应的包,并设计好测试集和训练集
##########decision tree##########
install.packages("rpart")
install.packages("rpart.plot")
install.packages("rattle")
install.packages("RColorBrewer")
library(rpart)
library(rattle)
library(rpart.plot)
library(RColorBrewer)
###########model
index=sample(1:nrow(iris),0.7*nrow(iris))
train=iris[index,]
test=iris[-index,]
建立模型,画图检验,并测试正确率
# It can be classified or regressed,you should specify the method
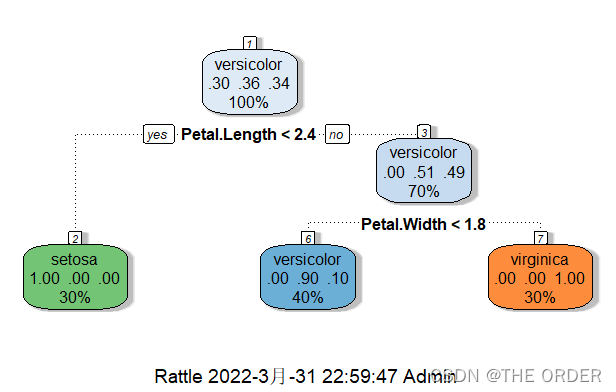
model1=rpart(Species~.,data=train,method="class")
model1
#Draw a picture,because the result is too difficult to understand
plot(model1)
text(model1)
iris
fancyRpartPlot(model1)
p1=predict(model1,test,type="class")
p1
A=as.matrix(table(p1,test$Species))
#Take out the diagonal of the matrix
diag(A)
acc=sum(diag(A))/sum(A)
acc

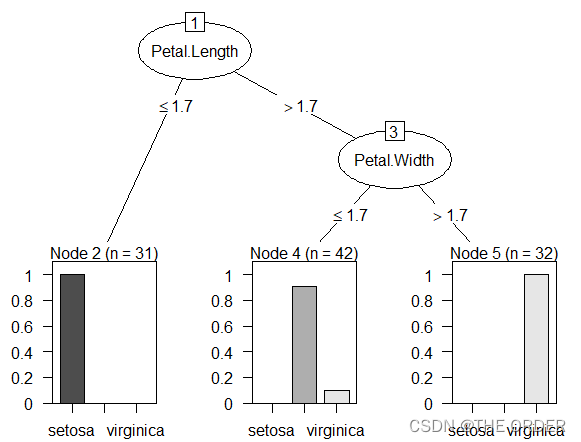
model2=rpart(Species~.,data=train,method='class',control=rpart.control(minsplit = 10,cp=0.2))
summary(model2)
plot(model2)
text(model2)
P2=predict(model2,test,type='class')
P2
A=as.matrix(table(P2,test$Species))
acc=sum(diag(A))/sum(A)
acc
C50算法实现
#install.packages('C50')
library(C50)
tc<-C5.0Control(subset =F,CF=0.55,winnow=F,noGlobalPruning=F,minCases =20)
model3=C5.0(Species~.,data=train,control=tc,rules=F)
model3
P3=predict(model3,test,type='class')
B=as.matrix(table(P3,test$Species))
acc=sum(diag(B))/sum(B)
acc
summary(model3)
plot(model3)
C5imp(model3)

- 点赞
- 收藏
- 关注作者
评论(0)