R关联分析——Apriori算法 介绍

@TOC
1 相关概念


2 常用衡量指标
2.1支持度(Support)
:支持度计数除于总的事务数,表示
该规则在全部交易记录中出现的比率。
• 该指标是建立强关联规则的第一个门槛,衡量了所考察
关联规则在“量”上的多少。
• 关联规则相对于全部数据必须具有一定的普遍性(即具
显著性),才是有效的信息。
• 支持度(SUPPORT)的一个关键性质:一个项集的支持
度不会超过它的子集的支持度。
项集{A,B,C}:{A,B}是它的一个子集,A,B,C同时发生
的频数肯定不会超过A,B同时发生的频数。
2.2 置信度(Confidence)
表示在先决条件X发生的条件下,关
联项目Y发生的条件概率。
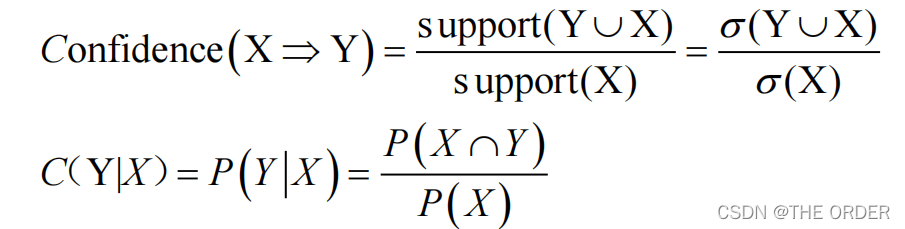
• 表示对当前提项目X发生时,可推得结果项目Y的规则的正
确性的信心程度。
• 置信度是衡量关联规则可信度的指标;因此,置信度须达
到一定水平(mincon) (通常为0.5),利用最小置信度为
门槛去除正确概率较低的关联规则。
2.3 提升度(lift)
表示在含有X的条件下同时含有Y的可能性与没
有X这个条件下项集中含有Y的可能性之比
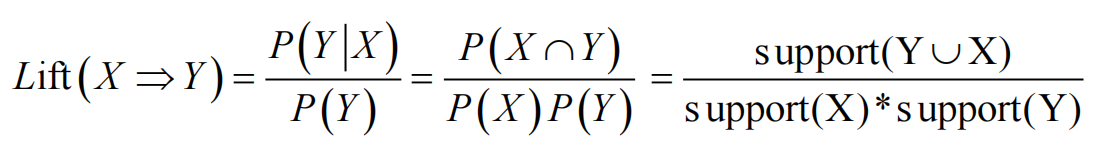
用于比较置信度与结果项目Y单独发生时两者概率间的大小
以衡量该规则的价值和相对效益.因此增益值至少要大于1。
增益大于1表示该关联规则的预测结果比原本表现好。
• 注意:
挖掘的基本设置
• 最小阈值(minsup):剔除占比较低的无意义规则,保留出现
较为频繁的、具代表性的关联规则用于实务应用。满足最小支
持度阈值的规则构成的项集称作频繁项集(frequent itemset)。 • 最小置信度:置信度考察关联规则在“质”上的可靠性,设定最 小置信度为门槛可以去除正确概率较低的关联规则。大于或等
于最小支持度阈值和最小置信度阈值的规则叫做强关联规则。 • 最低提升度。由于X与Y之间独立时,规则X–>Y提升度等于1, 即X的出现没有提高Y的出现。提升度大于1,且值越大说明X对 Y的影响越大,关联性也就越强。通常把最低提升度设置为1.
3 Apriori算法原理
3.1算法原理
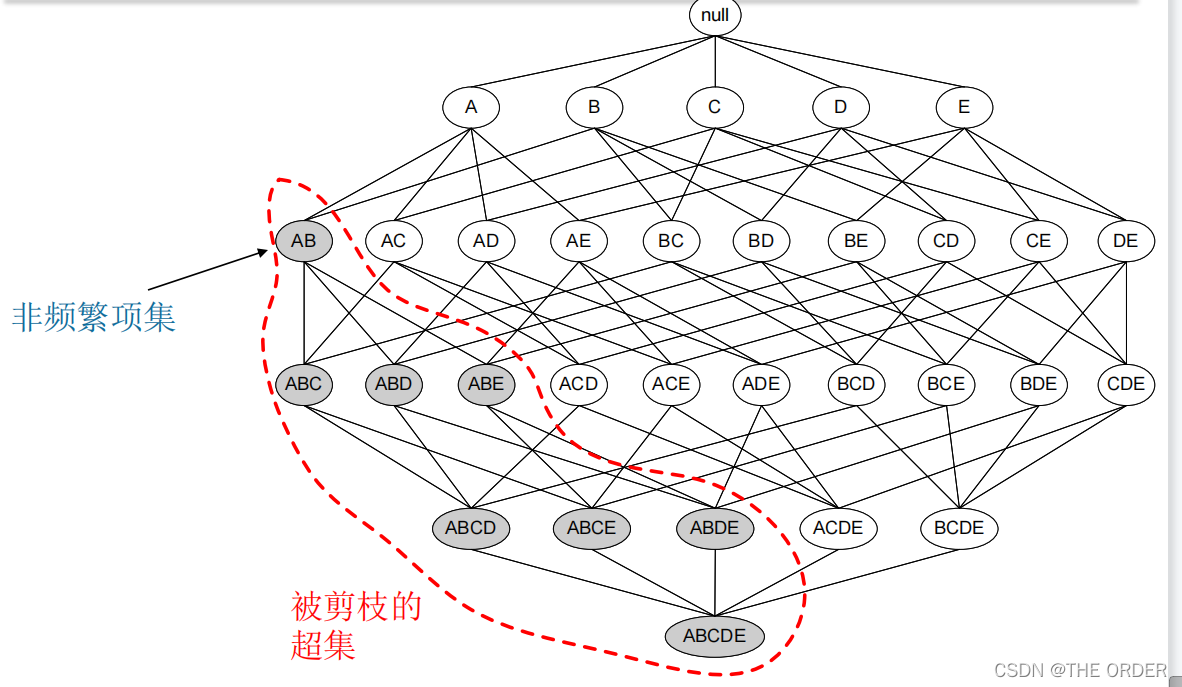
(1)如果一个项集是频繁的,则它的所有子集一定
也是频繁的(这个性质也称支持度度量的反单调性)。
也就是说如果当前的项集不是频繁的,那么它的超集
也不再是频繁的。
(2)频繁项集的所有子集也一定是频繁的,其逆否
命题为一个项集如果不是频繁项集,其超项集也一定
不是频繁项集。利用该性质可以大大减少算法对数据
的遍历次数。
3.2 规则的产生
一般两步:
• (1)第一步,找出频繁项集。n个items,最多可以产生2^n- 1 个项
集(itemsets)。利用指定的最小支持度可过滤掉非频繁项集。频
繁项集算法大致步骤:
• 算法初始通过单遍扫描数据集,确定每个项的支持度。一旦完成这
一步,就得到所有频繁1项集的集合F1; • 使用上一步迭代发现的频繁(k-1)项集,产生k项集;
• 对包含在每一个事务t中的所有可能的k项集进行支持度计数;
• 删除支持度计数小于阈值的所有项集,得到新的频繁项集; • 当没有新的频繁项集产生时,算法结束
大多数关联规则挖掘算法通常采用的一种策略是,
将关联规则挖掘任务分解为如下两个主要的子任务:
- 频繁项集产生(Frequent Itemset Generation) – 其目标是发现满足最小支持度阈值的所有项集,这些
项集称作频繁项集。 - 规则的产生(Rule Generation) – 其目标是从上一步发现的频繁项集中提取所有高置信
度的规则,这些规则称作强规则(strong rule)。
− 去重
第二步,找出第一步的频繁项集中的规
则。n个items,总共可以产生3^n - 2^(n+1) + 1
条规则。基本步骤:
• 将一个频繁项集Y划分成两个非空的子集X和 Y-X,使得X->Y-X满足置信度阈值。
• 用指定最小置信度过滤掉弱规则。
4 Apriori算法R实现过程
4.1 安装相关的包并读取数据
install.packages("gridBase")
install.packages("arules")
install.packages("arulesViz")
install.packages("graphlayouts")
library(gridBase)
library(arules)
library(arulesViz)
#现有购买记录
tr_list=list(c("Bread", "Milk"),
c("Bread", "Diaper", "Beer", "Eggs"),
c("Milk","Diaper", "Beer", "Coke"),
c("Bread", "Milk","Diaper","Beer"),
c("Bread", "Milk", "Diaper","Coke"))
#命名各个购物车
names(tr_list)=paste("tr",c(1:length(tr_list)),sep="")
tr_list
4.2 把链表转化为事务类型,apriori可以处理的格式
#调用as函数,将链表转化为事务类型
trans=as(tr_list,"transactions")
trans
summary(trans)
#####展示事务
##使用LIST函数
LIST(trans)
###查看数据
inspect(trans)
#调用image函数可视化检查事务数据
image(trans)
trans@data
trans@data@i
trans@data@p
trans@itemInfo#data.frame model
trans@itemInfo$labels#factor vector model
trans@itemsetInfo#data.frame model
trans@itemsetInfo$transactionID # shopping cart transactionID
#查看每个篮子的商品个数
size(trans)
###根据事务大小进行筛选
filter_trans=trans[size(trans)>=3]
inspect(filter_trans)
查看transaction里面的数据需要使用@
4.3转化为transaction的其它方式
###将矩阵格式的数据转化为事务类型
tr1=c(0,1,rep(0,3),1)
tr2=c(1,1,0,1,1,0)
tr3=c(1,0,1,1,0,1)
tr4=c(1,1,0,1,0,1)
tr5=c(0,1,1,1,0,1)
tr_matrix=matrix(cbind(tr1,tr2,tr3,tr4,tr5),byrow=T,nrow=5)
dimnames(tr_matrix)=list(paste("tr",c(1:nrow(tr_matrix)),sep=""),c("Bear","Bread","Coke","Diaper","Eggs","Milk"))
tr_matrix
trans2=as(tr_matrix,"transactions")
inspect(trans2)
trans2@data
#将数据框类型的数据转换成事务类型
trID=c(rep(1,2),rep(2:5,each=4))
item=c("Bread", "Milk",
"Bread", "Diaper", "Beer", "Eggs",
"Milk","Diaper", "Beer", "Coke",
"Bread", "Milk","Diaper","Beer",
"Bread", "Milk", "Diaper","Coke")
tran=cbind(trID,item)
tran
trans3=as(tran,"transactionss")#错误做法 Wrong pratice
#True
tr_df=as.data.frame(tran)
tr_df=as.data.frame(tran)
tr_split=split(tr_df[,"item"],tr_df[,"trID"])
trans3=as(tr_split,"transactions")
#也可以这样做
tr_dataf=data.frame(trID=c(rep(1,2),rep(2:5,each=4)),item=c("Bread", "Milk",
"Bread", "Diaper", "Beer", "Eggs",
"Milk","Diaper", "Beer", "Coke",
"Bread", "Milk","Diaper","Beer",
"Bread", "Milk", "Diaper","Coke"))
tr_dataf
trans4=as(split(tr_dataf[,"item"],tr_dataf[,"trID"]),"transactions")
trans4
inspect(trans4)
as.data.frame(tr_dataf[,1])
4.4 读取一个购物车文件并进行处理
library(openxlsx)
#loading data
readt=read.xlsx("shoppingcart.xlsx")
readt
#view data type
apply(readt,2,class)
#Transform the data into a form that the apriori algorithm can process
trans5=as(split(readt[,"ProID"],readt[,"UserId"]),"transactions")
inspect(trans5)
read2=read.transactions("shoppingcart2.csv",format="single",sep=",",cols=c("UserId","ProId"),header=T)
inspect(read2)
4.5 查看支持度
#View the support of each item
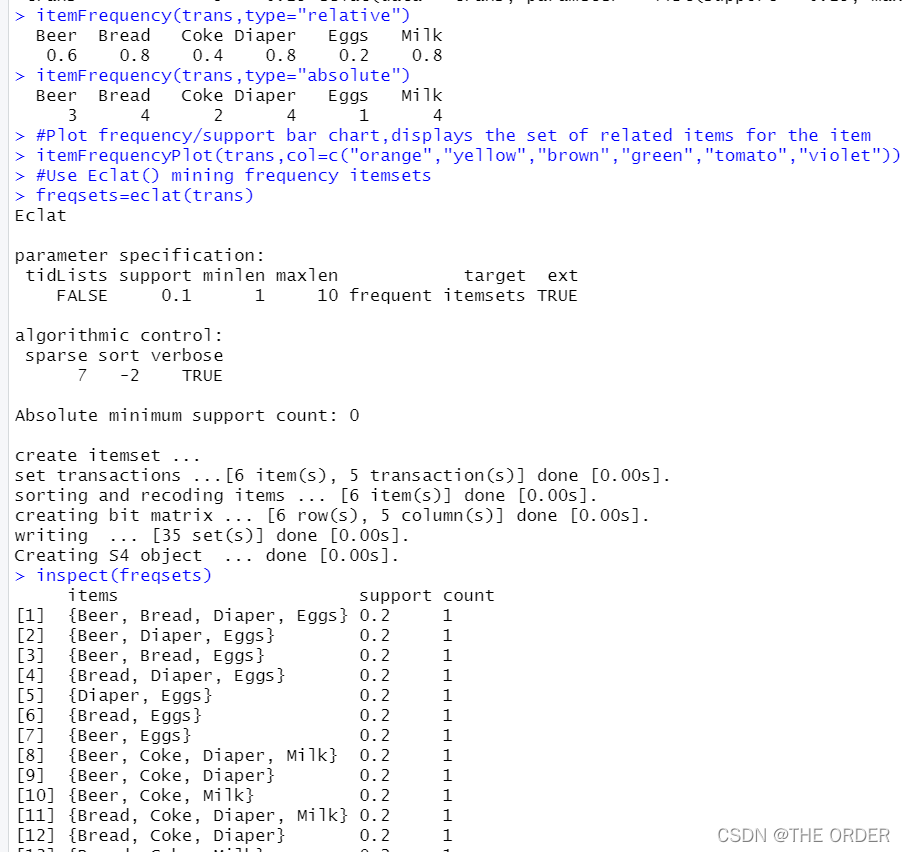
itemFrequency(trans,type="relative")
itemFrequency(trans,type="absolute")
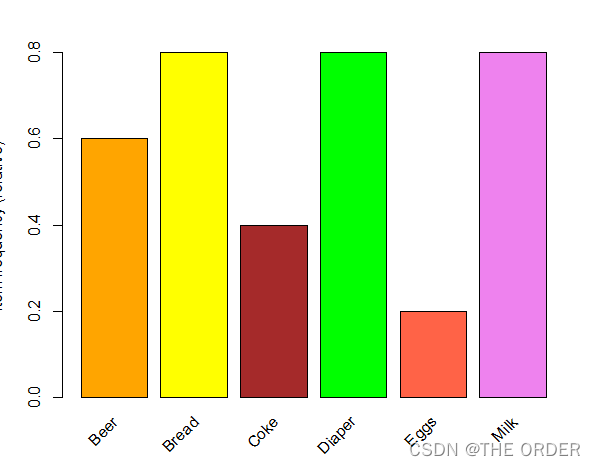
#Plot frequency/support bar chart,displays the set of related items for the item
itemFrequencyPlot(trans,col=c("orange","yellow","brown","green","tomato","violet"))
#Use Eclat() mining frequency itemsets
freqsets=eclat(trans)
inspect(freqsets)
#you also can add parameter restrictions
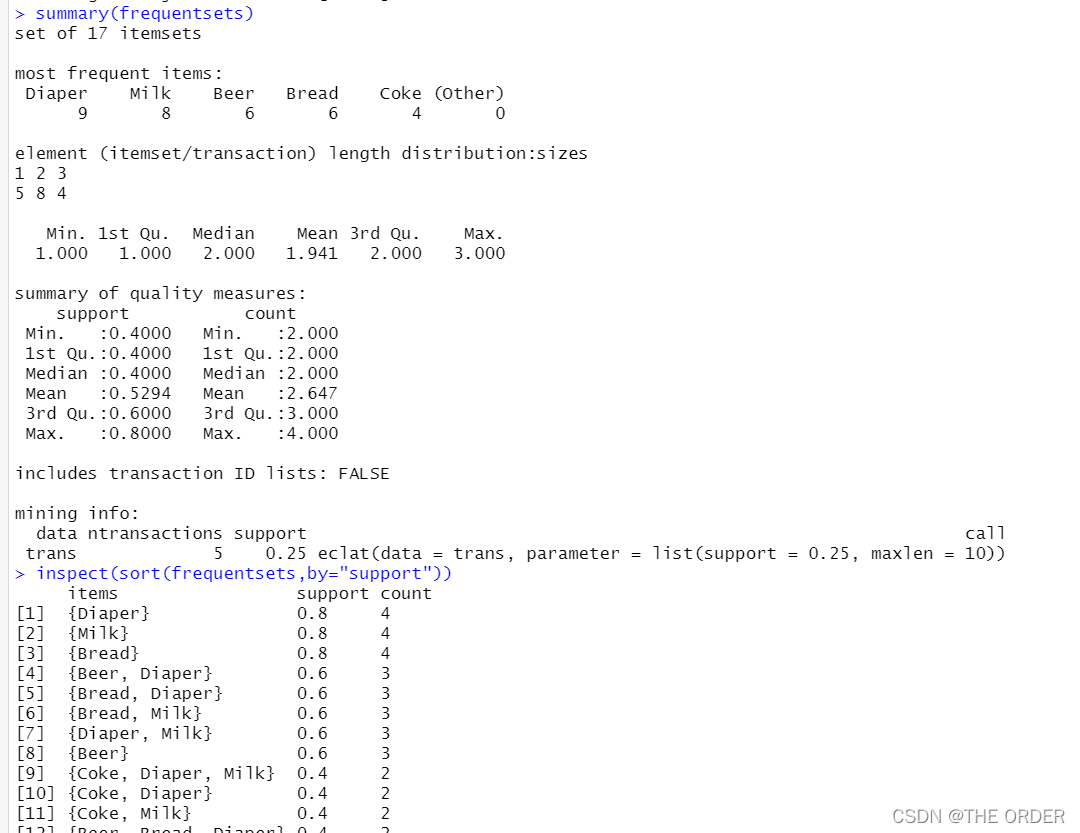
frequentsets=eclat(trans,parameter = list(support=0.25,maxlen=10))
summary(frequentsets)
inspect(sort(frequentsets,by="support"))
4.6生成规则
###generate association rules-------------------------------------------------------------------
# n items,it has up to 2^n -1 items,up to 3^n-2^(n+1) rules
rules=apriori(trans,parameter =list(support=0.25,confidence=0.5,target="rules"))
inspect(rules)
summary(rules)
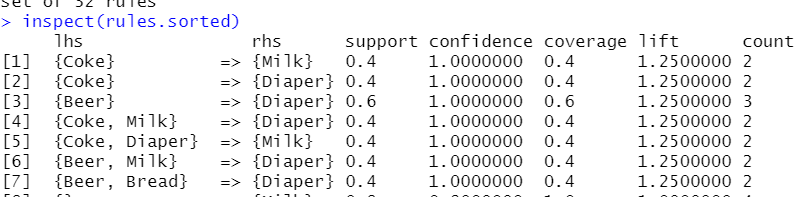
#Sort rules according to confidence,and view some of the previous rules
rules.sorted=sort(rules,by="confidence",decreasing = T)
rules.sorted
inspect(rules.sorted)
4.7 去掉冗余的规则
#Judge whether the rule is redundance
redundant=is.redundant(rules.sorted)
redundant
#Find redundant rules
rules.redundant=rules.sorted[redundant]
inspect(rules.redundant)
#drop redundant rules
rules.pruned=rules.sorted[!redundant]
inspect(rules.pruned)
#relation diagram
sortrules=sort(rules,by="lift")
inspect(sortrules)
比如2和4,无论有没有milk都会推荐diaper,存在冗余

4.8 关联规则的可视化
library(arulesViz)
plot(rules.pruned,measure="confidence",method="graph",control=list(type="items"),shading="lift")
#interactive
plot(rules,measure = c("support","lift"),shading = "confidence",interactive = T)
#View one rule
Milk_rule=apriori(data=trans,parameter = list(support=0.2,confidence=0.5,minlen=2),appearance = list(default="rhs",lhs="Milk"))
inspect(Milk_rule)
plot(Milk_rule,by="lift",main="Milk_rule by lift",method="graph",control =list(type="items"))
#Draw a balloon diagram of association rules,more than two rules can be drawn
plot(c(rules.pruned,Milk_rule),main="Milk_rules by grouped")
plot(c(rules.pruned,Milk_rule),method="grouped",main="Milk_rules by grouped")
# Using Apriori algorithm to generate the right milk rule
Rhs_Milk=apriori(data=trans,parameter = list(support=0.2,confidence=0.5,minlen=2),
appearance = list(default="lhs",rhs="Milk"))
inspect(Rhs_Milk)
redundant1=is.redundant(Rhs_Milk)
Rhr=Rhs_Milk[!redundant1]
inspect(Rhr)
5 关联规则的可视化
tr_dataf=data.frame(trID=c(rep(1,2),rep(2:5,each=4)),item=c("Bread", "Milk",
"Bread", "Diaper", "Beer", "Eggs",
"Milk","Diaper", "Beer", "Coke",
"Bread", "Milk","Diaper","Beer",
"Bread", "Milk", "Diaper","Coke"))
tr_dataf
trans4=as(split(tr_dataf[,"item"],tr_dataf[,"trID"]),"transactions")
trans4
inspect(trans4)
attributes(trans4)
itemFreq=itemFrequency(trans4)
orderItemFreq=sort(itemFreq,decreasing = T)
itemFrequencyPlot(trans4,topN=10,horiz=T,col="pink",border="lightblue",fg="deepskyblue3",col.axis="deepskyblue4",col.lab="deepskyblue4")
library(wordcloud2)
tabletr=table(tr_dataf$item)
tabletr=sort(tabletr,decreasing = T)
wordcloud2(tabletr,size=0.5,shape = "star")
####################################### generate association rules#####################
rules.tr=apriori(trans4,parameter = list(minlen=2,support=0.5,confidence=0.5),target="rules")
inspect(rules.tr)
inspect(head(rules.tr@lhs))
library(arulesViz)
plot(rules.tr)
plot(rules.tr,method = "grouped")
#####Extract rules of interest
rules.trs=sort(rules.tr,decreasing = T,by="lift")
inspect(rules.trs)
plot(rules.tr,method = "graph",lty=10)
####################################find redundant rules
redundant0=is.redundant(rules.trs)
which(redundant0)
##### drop dedundant rules
rules.trp=rules.trs[!redundant0]
plot(rules.trp)
###### Generate specific rules
inspect(rules.trp)
rulesspecial=apriori(trans4,parameter=list(minlen=2,support=0.5,confidence=0.5),
appearance=list(rhs=c("Milk","Bread"),default="lhs") )
#Milk_rule=apriori(data=rules.trp,parameter = list(support=0.2,confidence=0.5,minlen=2),appearance = list(default="rhs",lhs="Milk"))
inspect(rulesspecial)
rulesspeciall=apriori(trans4,parameter=list(minlen=2,support=0.5,confidence=0.5),
appearance=list(lhs=c("Milk","Bread"),default="rhs"))
inspect(rulesspeciall)
plot(rulesspecial,measure = "confidence",method="graph",control = list(type="items"),shading = "lift")

- 点赞
- 收藏
- 关注作者
评论(0)