R 逻辑回归

@TOC
1 应用场景
逻辑回归被广泛应用在目标变量是二值变量的场合 (0, 1)
2 公式
– P(y=1|x) 表示 y = 1的概率
– 从而得到 y = 1 对 y = 0 概率的比值
3 模型估计
– 极大似然估计

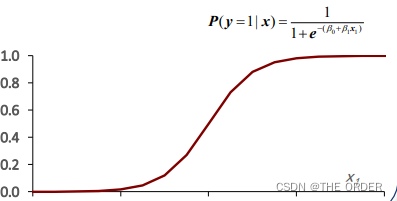
模型阐释/评估
– 一个解释变量的阐释图
4 读取与整理数据
整理数据格式,将数值变量和因子变量分类
data0=read.csv("accepts.csv",na.strings = "",colClasses = newcolclass)
str(data0)
nrow(data0)
summary(data0)
#定义目标角色
target0="bad_ind"
colclass=sapply(data0,class)
newcolclass=ifelse(colclass=="character","factor","numeric")
#找出data0中变量时numeric的名称
numerics=names(which(sapply(data0,is.numeric)))
length(numerics)
#找出data0是factor的变量名称,集合的差
factors=setdiff(names(which(sapply(data0,is.factor))),target0)
length(factors)
5 变量筛选
5.1集中度和分类数筛选
###取值集中在某一取值
maxper=sapply(data0, function(x) max(table(x)/length(x)))
summary(maxper)
centors=names(which(maxper>0.95))
#分类太多的可以考虑合并
maxperf=sapply(data0[,factors], function(x) max(table(x)/length(x)))
summary(maxperf)
5.2 缺失值分析
nanumber=sapply(data0,function(x) sum(is.na(x)))
summary(nanumber)
#查找大于80%的缺失值
missings3=names(which(nanumber>=0.7*nrow(data0)))
#查找大于50%的缺失值
missings2=names(which(nanumber>=0.5*nrow(data0)))
#查找大于30%的缺失值
missings1=names(which(nanumber>=0.3*nrow(data0)))
修改缺失值的值,数值型用中位数填补,因子型用众数填补
#修改数值型和因子型列缺失值
modifyna=function(x){
for (i in 1:length(x)) {
if(sum(is.na(data0[,i]>0))){
if(class(data0[,i])=="numeric"){
x[,i][is.na(x[,i])]=median(x[,i],na.rm = T)
}else{
a=table(x[,i])
b=which(a==max(a))
x[,i][is.na(x[,i])]=names(b)
}
}
}
x
}
data1=modifyna(data0)
填补后缺失值为0
#将y放在第一列
name=colnames(data1)
match("bad_ind",name)
data2=data1[,c(3,1:2,4:length(data1))]
5.3 频率筛选
#根据业务删除与y无关的
nrow(data2)
colname2=colnames(data2)
match(c("application_id","account_number"),colname2)
data3=data2[,c(-2,-3)]
对过多种类的分类变量进行处理
lvls=sapply(data2[factors],function(x) length(levels(x)))
summary(lvls)
manylvls=names(which(lvls>8))
manylvls
data2$vehicle_make
factors=setdiff(factors,manylvls)
*删除数值类型少的numeric变量,并把二分类变量变为logic因子变量
concret=names(which(lev!=2 & lev<30))
concret
#logic变量
logic=names(which(lev==2))
logic
data3[,logic]=as.data.frame(lapply(data3[,logic],as.factor))
colnames(data3)[2]="vehicle_year"
#确定第一次删除的变量
ignores=c(centors,missings3,manylvls,concret,target0)
input=setdiff(names(data3),ignores)
IV(信息价值)通常应用于评分模型,是基于WOE(证据权重)计算的,
反应的是单个自变量自身与因变量之间的关系,衡量自变量的预测能力,
是筛选变量参考的指标。
计算变量的IV值,ln(bad/good)*(bad-good)
x=data3$age_oldest_tr
target=data3[,1]
summary(x)
x=binning(x,bins=8,method="quantile")
temp1=table(x,target)
temp1
#频数统计表转化为数据框,矩阵的长度为水平的个数
temp2=as.data.frame(matrix(temp1,length(unique(x)),2))
length(unique(temp1))
#计算比例
temp3=as.data.frame(sapply(temp2, function(x) x/sum(x)))
#权重
woe=log(temp3[,2]/temp3[,1])*100
woe
#IV值
iv=sum((temp3[,2]-temp3[,1])*woe)
###自编函数
var.iv=function(x,target){
if(is.numeric(x)){
#分箱
x=binning(x,bins=8,method = "quantile")
#频数表
x=table(x,target)
#转列表
x=as.data.frame(matrix(x,nrow(x),ncol(x)))
#比例矩阵
x=sapply(x,function(x) x/sum(x))
if(!is.matrix(x)){Iv=0} else{
#权重
woe=log(x[,2]/x[,1])*100
#IV值
Iv=sum((x[,2]-x[,1])[!is.infinite(woe)]*woe[!is.infinite(woe)])
}
return(Iv)
}
}
var.iv(data3[,12],target)
data4=data3[input]
class(data4)
#计算输入数据的IV值
iv.value=sapply(data4,function(x) var.iv(x,target))
IV=unlist(iv.value)
#增加IV等于0的为因子变量
factors=append(factors,"used_ind")
class(IV)
summary(IV)
#列表转向量
as.vector(unlist(iv.value))
#修改数据框某一列的数据类型
data4$used_ind=as.factor(data4$used_ind)
#选择IV大于10,bad和good差较大的变量
ninput=names(which(IV>10))
length(ninput)
对于分类型变量,也应该筛选IV>10比较合适,这里是为了后面逐步回归比较AIC值,选择大于1的IV值
fvar.iv=function(x,target){
if(is.factor(x)){
#分箱
#频数表
x=table(x,target)
#转列表
x=as.data.frame(matrix(x,nrow(x),ncol(x)))
#比例矩阵
x=sapply(x,function(x) x/sum(x))
#权重
woe=log(x[,2]/x[,1])*100
#IV值
fIv=sum((x[,2]-x[,1])[!is.infinite(woe)]*woe[!is.infinite(woe)])
return(fIv)
}
}
fvar.iv(data4[,1],target)
fiv.value=sapply(data4,function(x) fvar.iv(x,target))
Fiv=unlist(fiv.value)
class(Fiv)
###确定最终进入模型的变量
finput=names(which(Fiv>1))
input=append(ninput,finput)
data_input=data4[,input]
str(data_input)
summary(data_input)
###确定最终进入模型的变量
finput=names(which(Fiv>1))
input=append(ninput,finput)
data_input=data4[,input]
str(data_input)
summary(data_input)
#分割数据设置,训练集和测试集
set.seed(1)
n=nrow(data_input)
train_number=sample(1:n,round(n*0.8))
##构建训练集
train=data_input[train_number,]
train_y=target[train_number]
table(train_y)
test=data_input[-train_number,]
test_y=target[-train_number]
构建模型
logitfit=glm(train_y~.,data=train,family="binomial")
summary(logitfit)
coef(logitfit)
#系数的含义优势比的增加量
sapply(coef(logitfit), function(x) round(exp(x),3))
logitfitstep=step(logitfit)
logitfit=glm(train_y ~ age_oldest_tr + tot_rev_line + fico_score + ltv,data=train,family = "binomial")
通过逐步回归,选择能使AIC最小的变量进入模式

AIC,即赤池信息量准则,是衡量统计模型拟合优良性的一种标准。
●赤池信息量准则建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
AIC= =2k- 2Ln(L)
其中k是模型参数个数,L是似然函数。通常选择AIC最小的模型为最优模型。
●当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。
BIC,即贝叶斯信息准则,与AIC相似,用于模型选择。
训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
BIC= kLn(n)- 2Ln(L)
… 其中,k为模型参数个数,n为样本数量,L为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
6 对模型进行样本内外预测
library(gtools)
library(gmodels)
#样本内预测
logit_train_fit=fitted(logitfit)
summary(logit_train_fit)
summary(target)
###########################################样本外预测
logit_test_fit=predict(logitfit,newdata = test,type="response") #加responce输出是P,否则是y值
summary(logit_test_fit)
###########################################样本外预测
logit_test_fit=predict(logitfit,newdata = test,type="response") #加responce输出是P,否则是y值
summary(logit_test_fit)
#预测效果检验
##########################################逻辑分类-样本内
p=table(train_y)/length(train_y)
##以p[2]作为临界值划分
logit.cluster=factor(logit_train_fit>p[2],levels=c(F,T),labels=c(0,1))
table(logit.cluster)
#预测准确率
per.pre.train=table(train_y,logit.cluster,dnn=c("Actual","predicted"))
per.pre.train
p11=per.pre.train[2,2]/sum(per.pre.train[2,])
p11
p00=per.pre.train[1,1]/sum(per.pre.train[1,])
p00
accuracy=(per.pre.train[1,1]+per.pre.train[2,2])/sum(per.pre.train)
accuracy
分别查看11,00和总体的正确率
#######################################样本外
#p.pred=exp(logit_test_fit)/(1+exp(logit_test_fit)) 没有responce的概率处理
p.pred=logit_test_fit
summary(p.pred)
pt=table(test_y)/length(test_y)
pt
log(pt[2]/pt[1])
logit.pred=factor(p.pred>p[2],levels=c(F,T),labels=c("0","1"))
table(logit.pred)
#对比预测与真实值
table_pre.test=table(test_y,logit.pred,dnn = c("Actual","predicted"))
table_pre.test
pt11=table_pre.test[2,2]/sum(table_pre.test[2,])
pt11
pt00=table_pre.test[1,1]/sum(table_pre.test[1,])
pt00
accuracyp=(table_pre.test[1,1]+table_pre.test[2,2])/sum(table_pre.test)
accuracyp
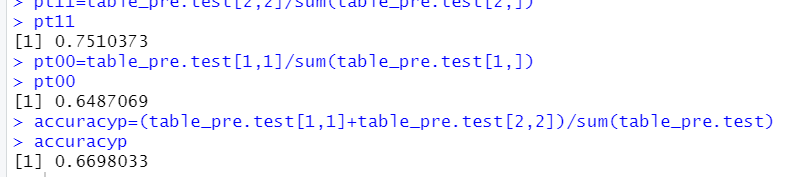
这里的预测阈值采用的是训练集中1发生概率的阈值做比较,效果一般
7ROC曲线检验模型
#####################################预测效果检验
library(colorspace)
library(pROC)
modelroc=roc(test_y,logit_test_fit,plot=T)
plot(modelroc,print.auc=T,auc.polygon=T,grid=c(0.1,0.2),grid.col=c("green","red"),max.auc.polygon=T,auc.polygon.col="skyblue",print.thres=T)
modelauc=auc(modelroc)
modelauc
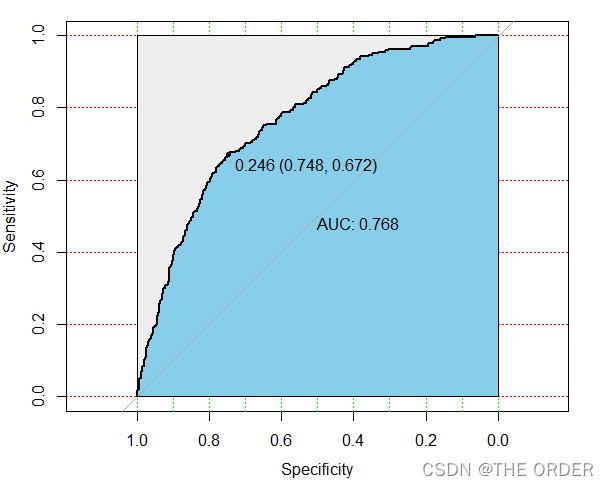
通过roc曲线可以选择最适合的阈值

- 点赞
- 收藏
- 关注作者
评论(0)