R 多元线性回归

@[TOC](R 多元线性回归)
#影响收入的因素多元线性回归 Multiple linear regression of fators affecting income
1,读取数据集 Read dataset
library(openxlsx)
dataO=read.xlsx("2.xlsx")
data0=na.omit(dataO)
2 根据业务排除不相关的自变量 Exclude irrelevant variables according to business
data1=data0[,4:9]
class(data)
3 整理数据集,使y在第一列 Organize the data set so that y is the first column
name=colnames(data2)
match("income",name)
data2=data1[,c(3,1,2,4:5)]
name=colnames(data2)
4 对y跑x个数的一元回归
删选最不相关的变量,直接使用循环一元线性回归很慢,直接使用相关系数删选,并观察x的共线性
这样做效率并不高,太慢了
#Select the most irrelevant variables by univariate regression for y,Direct circular univariate regression is very slow,direct use of correlation coefficient,And observe the collinearity of X
# for (i in name) {
#
# unifit=lm(data1$income~data1$i)
# print(summary(unifit))
# }
library(mvtnorm)
library(kernlab)
library(corrgram)#画图包
round(cor(data2),2)
corrgram(data2,order=T,lower.panel=panel.shade,upper.panel=panel.pie,text.panel=panel.txt,main="plot")
corrgram(data2, lower.panel=panel.pts, upper.panel=panel.conf,
diag.panel=panel.density)
corrgram(vote, order=TRUE, upper.panel=panel.cor)
#排除address和共线性 Exclude address and colinearity
data3=data2[,-match("address",name)]
round(cor(data3),2)
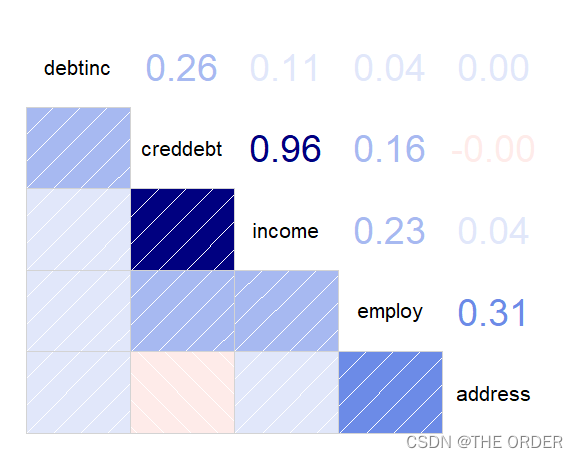
发现income和address相关很小可以删除address变量
其它相关系数矩阵发现数据还可以
x于x之间没有明显的相关性
对于相关性较高的x,可以尝试做标识变量
对于多个高度相关的数据可以尝试做主成分分析
多重共线性会导致β系数不稳定,一定要消除
5 创建训练集和测试集 Create training and test sets
num=sample(1:nrow(data),round(nrow(data1)*0.8))
train=data2[num,-match("address",name)]
test=data2[-num,-match("address",name)]
6使用测试集创建多元回归方程
Create multiple regression equations using test sets
fit1=lm(income~.,data=train)
summary(fit1)
#后退法,删除最不显著的backward,Delete the least significant
stepfit=step(fit1)
summary(stepfit)
confint(fit1)
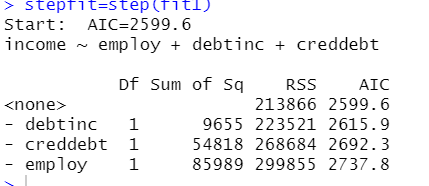
通过后退法发现再把变量拿出去,会使AIC值变大,(AIC越小越好)
7 残差分析 residual analysis
7.1检验残差 Check residuals
summary(fit1$residuals)
par(mfrow=c(2,2))
plot(fit1)

通过画图观察残差,发现是有部分离群点,异常值的
7.2残差直方图判断残差的正态性
# Normality of histogram judgment residuals
residplot=function(fit,nbreak=10){
z=rstandard(fit)
hist(z,breaks=nbreak,freq=F,xlab="Resuduals",main="Distribution of Errors")
curve(dt(x,1),
add=T,col="blue",lwd=2)
curve(dnorm(x,mean =mean(z),sd=sd(z)),add=T,col="green",lwd=2)
legend("topright",legend=c("Normal Curve","t curve"),lty=1:2,col=c("green","blue"),cex=0.8)
}
qqnorm(fit1$residuals)
qqline(fit1$residuals)
residplot(fit1)

发现图像还是有一点右偏分布的
#用统计量检验正态性 原假设正态的 不符合加大样本量 Testing normality with statistics ,the original hypothesis is normal
ks.test(fit1$residuals,"pnorm",0,sd(fit1$residuals))
ks.test(fit1$residuals,"pt",1)
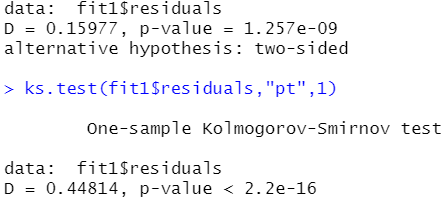
发现结果并不符合正态分布
#检验残差的不同 difference of residuals
#标准化残差和学生化残差差别图
r2=rstandard(fit1)
r3=rstudent(fit1)
diff=r2-r3
hist(diff,breaks=20,freq = F,xlab="difference",main="difference between resudial"

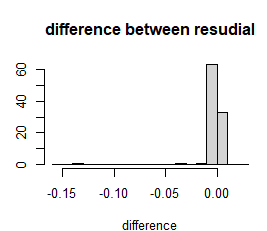
发现还是有异常值的影响,残差有一点右偏分布
7.3 独立性检验

#7.3 残差的独立性 Independence of residuals
library(car)
#独立性检验 原假设独立的 Independent test .The original hypothesis is independent
durbinWatsonTest(fit1)

7.4 齐次方差检验
#齐次方差检验 Same variance test 原假设齐次的 the original assumption is that the variance is same.Non~constant error variance 不符合进行y变换 if variance isn't same,transform it.收益率取对数可以相加 The logarithm of the rate of return can be added.
library(nloptr)
library(car)
ncvTest(fit1)
spreadLevelPlot(fit1)
summary(fit1$fitted.values)
crPlots(fit1)
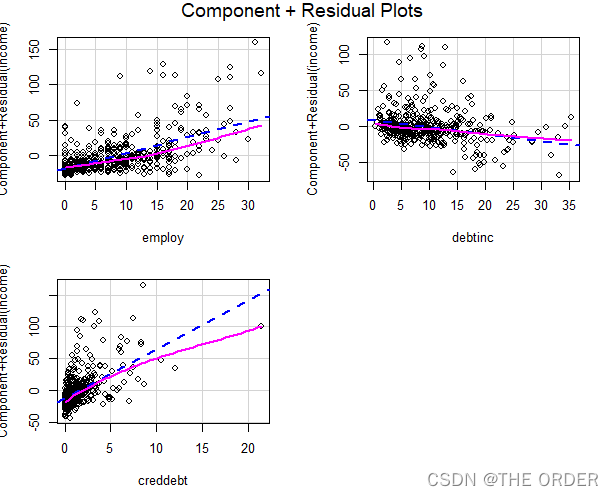
发现其次性也被异常值干扰
7.5 共线性检验VIF
crPlots(fit1)
#大于2可能存在多重共线性
sqrt(vif(fit1))>2




共线性结果较好,说明不存在多重共线性
现在要解决残差问题
8 找异常点与修剪
#8.1 找异常点 find outliers
uniouts=outlierTest(fit1)
unirem=names(uniouts$rstudent)# 离群点残差的编号 Number of outlier residuals
uniouts=outlierTest(fit1)
unirem=names(uniouts$rstudent)# 离群点残差的编号 Number of outlier residuals
#修订的测试集 Revised test set
train_pruned=data3[setdiff(num,unirem),]#setfidd是取不同的元素,只取num中不同的
class(unirem)
t=as.numeric(rownames(train_pruned))
nrow(train_pruned)
#新建的多元回归模型 New multiple regression equation
fit1_pruned=lm(income~.,data=train_pruned)
par(mfrow=c(2,2))
plot(fit1)
plot(fit1_pruned)
summary(fit1)
summary(fit1_pruned)
spreadLevelPlot(fit1_pruned)
#高杠杆点 High leverage point
hat=hatvalues(fit1_pruned)
hat
plot(hat)
abline(h=6/nrow(train_pruned),col="red",lwd=3)
identify(1:length(hat),hat,names(hat))#identify 识别
hat.plot=function(fit){
k=length(coefficients(fit))#系数项
n=length(fitted(fit))#样本长度
plot(hatvalues(fit),main="Index plot of Hat values")
abline(h=c(2,3)*k/n,col=c("green","red"),lty=2)
identify(1:n,hatvalues(fit),names(hatvalues(fit)))
}
r2=hat.plot(fit1_pruned)
length((fitted(fit1_pruned)))
#修订的测试集 Revised test set
train_pruned=train_pruned[setdiff(t,132),]
nrow(train_pruned)
#新建的多元回归模型 New multiple regression equation
fit1_pruned=lm(income~.,data=train_pruned)
summary(fit1_pruned)
#用dffits距离检查 Distance check
dff_cri=2*sqrt((ncol(train_pruned)+1)/nrow(train_pruned))
#找出哪些些样本的diffts距离较大 Find out which samples are more distant
which(dffits(fit1_pruned)>dff_cri)
#利用cook距离查找强影响到哪,cutff去掉cook‘s距离标准为4/(n-k-1),标出 Strong influence point
cooks=cooks.distance(fit1_pruned)
cutoff=4/(nrow(train_pruned)-length(fit1_pruned$coefficients))#默认10个
which(cooks>cutoff)
##画cook距离图 Draw distance map
cutoff=4/(nrow(train_pruned)-length(fit1_pruned$coefficients))
plot(fit1_pruned,which=4)
abline(h=cutoff,lty=2,col="red")
##用影响度检查 Use influence to check
fitedditinfluence=influence.measures(fit1_pruned)
summary(fitedditinfluence)

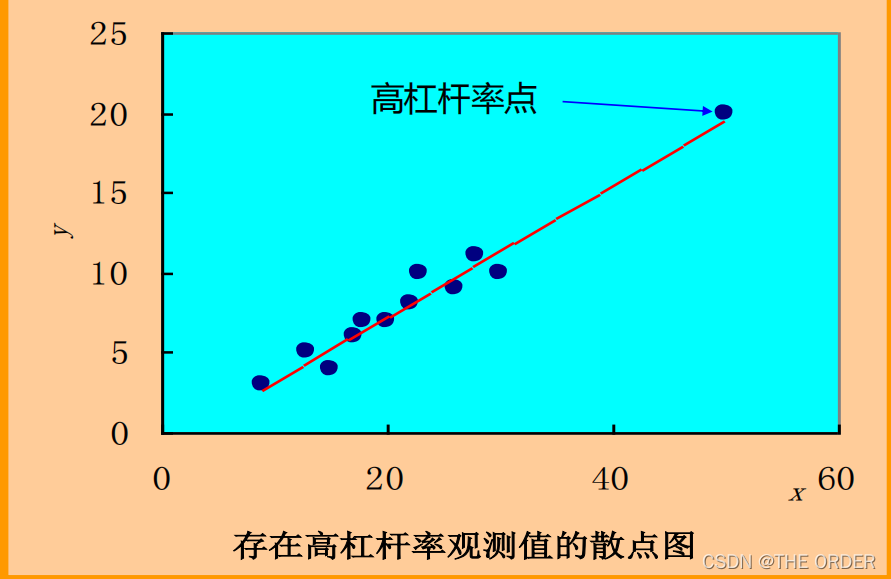

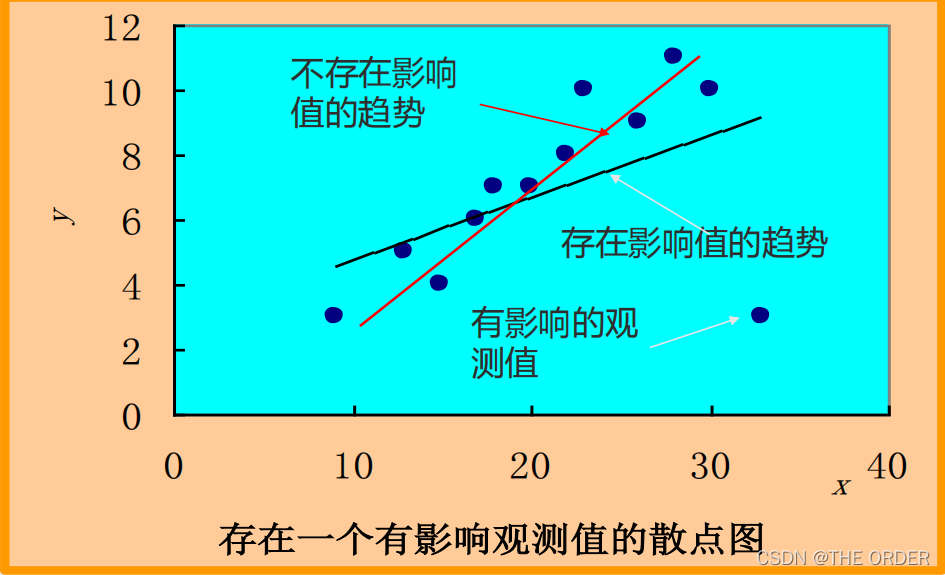
可以使用多种方法找异常值尝试修改,也可以把离群点,杠杆值和强影响点整合到一张图上
##influencePlot() 将离群点、杠杆值和强影响点整合到一张图 Integrate outliers,leverage points and strong influence points into one map
influencePlot(fit1_pruned,id.method="identify",main="Influence Plot",sub="Circle size if proportion to cook's distance")

##influencePlot() 将离群点、杠杆值和强影响点整合到一张图 Integrate outliers,leverage points and strong influence points into one map
a=influencePlot(fit1,id.method="identify",main="Influence Plot",sub="Circle size if proportion to cook's distance")
a1=influencePlot(fit1_pruned,id.method="identify",main="Influence Plot",sub="Circle size if proportion to cook's distance")
#修订的测试集 Revised test set
a=rownames(a)
a1=rownames(a1)
b=rownames(train_pruned)
c=as.character(setdiff(num,a))
class(c)
c1=as.character(setdiff(b,a1))
train_pruned=train[c,]
train_pruned=train[c1,]
nrow(train)
nrow(train_pruned)
#新建的多元回归模型 New multiple regression equation
fit1_pruned=lm(income~.,data=train_pruned)
summary(fit1_pruned)
summary(fit1)
去除部分强影响点后,对模型进行优化
再次预览模型残差
summary(fit1$residuals)
#总览残差
summary(fit1_pruned$residuals)
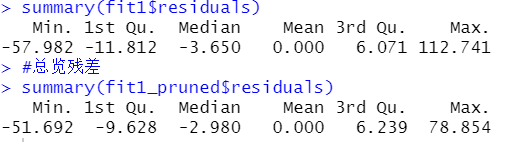
发现残差明显减小

图形比原先要好一些

残差偏态要轻一些了
9 拟合
#样本内拟合 In sample fitting
fitv1=fitted(fit1)
yllim=min(fitv1,train[,1])
yulim=max(fitv1,train[,1])
plot(train[,1],fitv1,ylim=c(yllim,yulim))
#修订后的拟合 Modified fitting
fitv1p=fit1_pruned$fitted.values
yllim=min(fitv1p,train[,1])
yulim=max(fitv1p,train[,1])
plot(train_pruned[,1],fitv1p,ylim = c(yllim,yulim))
样本外拟合,这里对y进行了区间预测
predict_test=predict(fit1_pruned,newdata = test[,-1],interval = "confidence")
summary(predict_test)



10 模型评估
par(mfrow=c(2,2))
predict_test0=predict(fit1,newdata = test[,-1],interval = "confidence")
plot(fit1)
diff_test0=test[,1]-predict_test0[,1]
summary(diff_test0)
hist(diff_test0,main="样本外测试残差")
#修订后
predict_test=predict(fit1_pruned,newdata = test[,-1],interval = "confidence")
plot(fit1_pruned)
diff_test=test[,1]-predict_test[,1]
summary(diff_test)
hist(diff_test,main="样本外测试残差")
对修订前后的样本外预测残差分析

发现残差中位数减小了,但残差均值增大,模型优化效果不好评定
对其进行可控范围内的残差正确比分析
#原先的多元线性回归 The original multiple regression equation
fit1=lm(income~.,data=train)
summary(fit1)
predict_test0=predict(fit1,newdata=test[,-1],interval="confidence")
diff_test0=test[,1]-predict_test0[,1]
#误差小于0.5的比例 THe error is small in proportion to 0.5
predict_error0=ifelse(test[,1]!=0,diff_test0/test[,1],1)
summary(diff_test0)
summary(predict_error0)
m0=length(which(abs(predict_error0)<0.5))
proportion0=round(m0/nrow(test),2)
优化前
误差小于0.5的比例 THe error is small in proportion to 0.5

优化后
误差小于0.5的比例 THe error is small in proportion to 0.5

发现把误差控制在真实值50%以内的情况下,优化后模型有所提升
其它模型
#其它模型
#交互项观察
install.packages("effects")
library(effects)
cross.fit=lm(income~employ+debtinc+creddebt+employ:debtinc,data=train_pruned)
summary(cross.fit)
m=mean(train_pruned$debtinc)
sig=sd(train_pruned$debtinc)
plot(effect("employ:debtinc",cross.fit,,list(debtnic=c(m-sig,m+sig))),mulyiline=T)
#cross.fit,,二个空逗号
#画散点矩阵图
scatterplotMatrix(train_pruned,main="scatter plot matrix")
#交互项非线性关系,可以取平方,有平方的线性回归
x.fit=lm(income~employ+debtinc+creddebt+I(employ^2),data=train_pruned)
summary(x.fit)
##不考虑截距项的回归
nointfit=lm(income~.-1,data=train_pruned)
summary(nointfit)
#高斯模型的广义线性回归模型
mgl=glm(income~.,data=train_pruned,family=gaussian)
summary(mgl)
anova(mgl,fit1_pruned)
#Poisson模型的广义线性回归
da=data.frame(warpbreaks)
structure(da)
rs1=glm(breaks~tension,family="poisson",data=warpbreaks)
rs1
qnorm(0.95)
pnorm(1.96)

- 点赞
- 收藏
- 关注作者
评论(0)