R代码一元线性回归

【摘要】 R一元线性回归
@TOC
1 数据预览
当我们拿到一分新数据的时候先预览下数据的情况,这里先以一份收入相关数据简单演示下
cre=read.csv("creditcard_exp.csv")
names(cre)
str(cre)
summary(cre)
2 y值的确定以及偏态数据的处理
s=hist(cre$Income,freq = F)
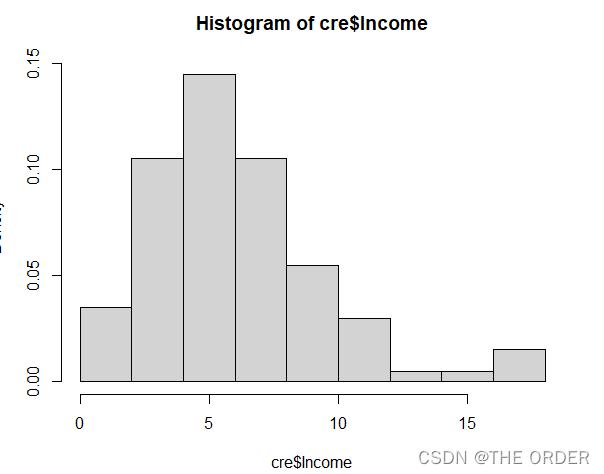
我们关注的收入指标比较正常,可以不做处理
如果明显右偏数据可以进行对数处理,左偏数据可以进行开方处理
3 数据整理
观察下数据
View(cre)
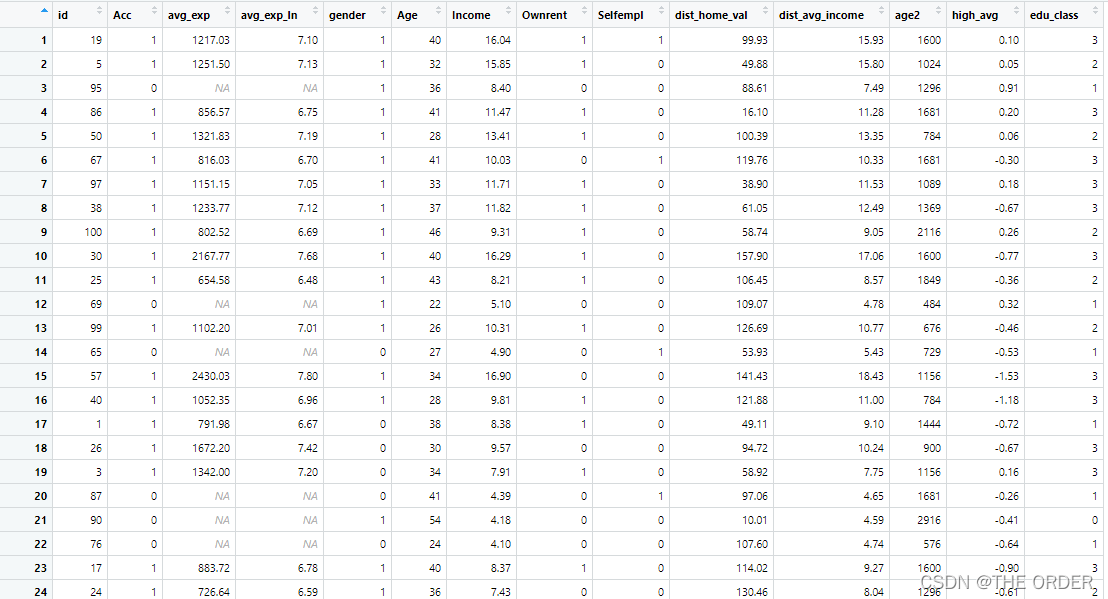
可以看到我们想要的y,并不在第一列,并且数据还有很多缺失值
我们可以删除此数据缺失数据(这里基础教程只是最简单的处理方式),对于缺失值的处理我们后面在讲解
cre=na.omit(cre)
which(colnames(cre)=="Income")
cre=data.frame(cre$Income,cre[,-7])
View(cre)
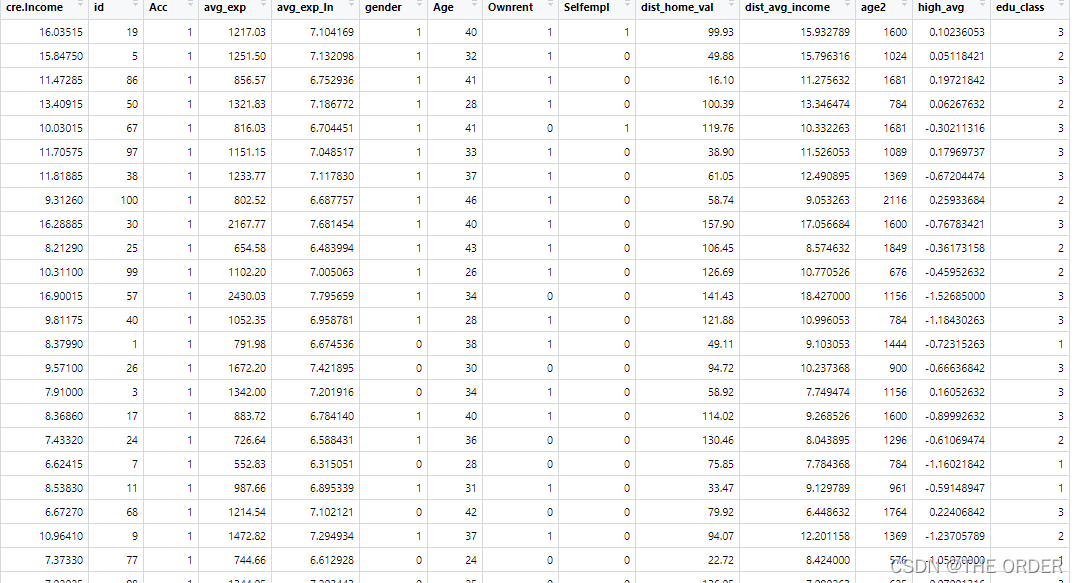
再次view数据
发现数据干净多了
4 绘图参数
pch=17,
col="red",
col.axis="green",
col.main="brown",
col.sub="blue",
fg="blue",
cex=1.5,
cex.axis=0.8,
cex.lab=1.2,
cex.main=1.5,
lwd=5
)
绘图参数只要便于数据和模型理解可以凭喜好设置
5 相关分析
correlationanalysis=cor(cre)#相关系数矩阵 correlation coefficient matrix
correlationanalysis=round(correlationanalysis,2)
View(correlationanalysis)
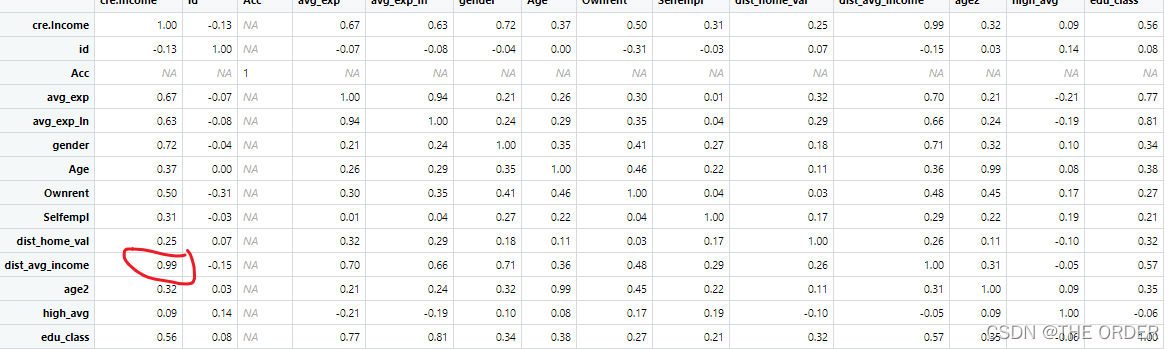
可以观察到
dist_avg_income与我们的income相关很高,如果只选一个变量的话就选它
对于Acc变量的NA值我们可以观察下
table(cre$Acc)
console
1
70
只有一个类型的数据所以相关分析有NA出现
我们还可以图形可视化相关系数
a=which(colnames(cre)=="Acc")
cre=cre[,-a]
corrgram(iris,order=T,lower.panel=panel.shade,upper.panel=panel.pie,text.panel=panel.txt,main="plot")
corrgram(iris, lower.panel=panel.pts, upper.panel=panel.conf,
diag.panel=panel.density)
corrgram(vote, order=TRUE, upper.panel=panel.cor)

6 构建模型
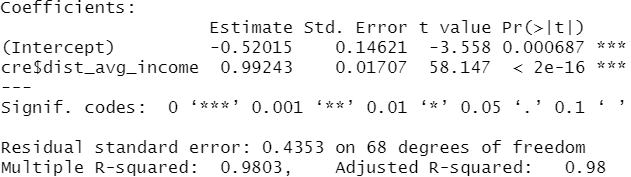
a=lm(cre$Income~cre$dist_avg_income)
summary(a)
plot(a) #对模型结果画图
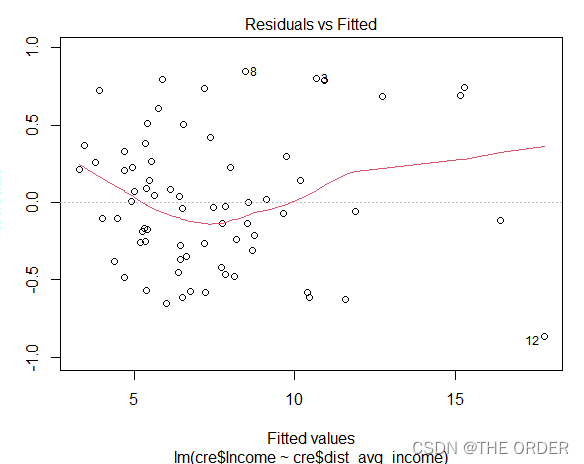
观察拟合值和残差,发现在y大时,齐方差性没那么好,结合summary的结果R方0.98
模型结果还可以
此次采用的是特殊数据,,在下篇文章详细进行数据处理,敬请关注

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)