001:网络爬虫基础理论整合

本篇文章整合了网络爬虫的基础知识,文章内容简明易懂。适合用来复习爬虫知识或者初识爬虫的人。
下面步入正题:
网络爬虫又被称为网络机器人,可以代替人们自动的在互联网中进行数据信息的采集与整理。在大数据时代,数据复杂度及采集数据效率是非常重要的。所以可以使用网络爬虫对数据信息进行自动采集并整合。
要学习网络爬虫,首先要认识网络爬虫,在本篇中,我来介绍一下几种典型的网络爬虫,并了解其各种常见功能。
初始网络爬虫:
网络爬虫可以自动化的浏览网络中的信息,并按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。Python语言可以很方便的写出爬虫程序,进行互联网的信息自动化检索。
每一个搜索引擎都离不开爬虫,百度的搜索引擎爬虫叫做百度蜘蛛,360的爬虫叫做360pider,搜狗的爬虫叫做Sogouspider,必应的爬虫叫Bingbot。
网络爬虫的组成:
网络爬虫主要由控制节点、爬虫节点、资源库构成。
控制节点,也叫作爬虫的中央控制器,主要负责根据URL地质分配线程,并调用爬虫节点按照相关的算法,对网页进行具体的爬行。并将对应的结果储存到对应的资源库中。
网络爬虫的类型:
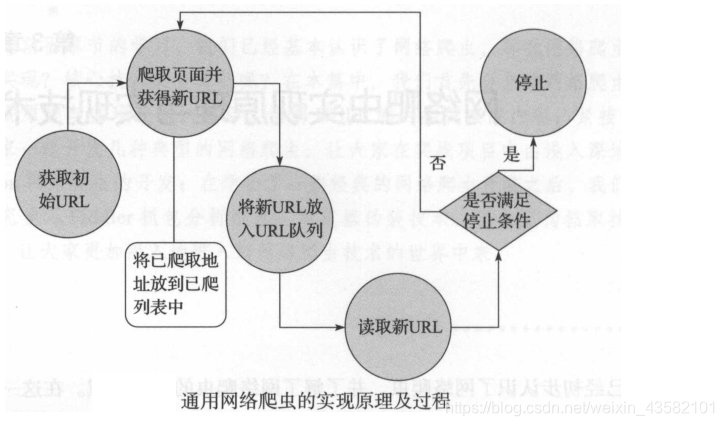
通用网络爬虫:也叫全网爬虫。顾名思义,爬取的资源在全网中。通用爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。
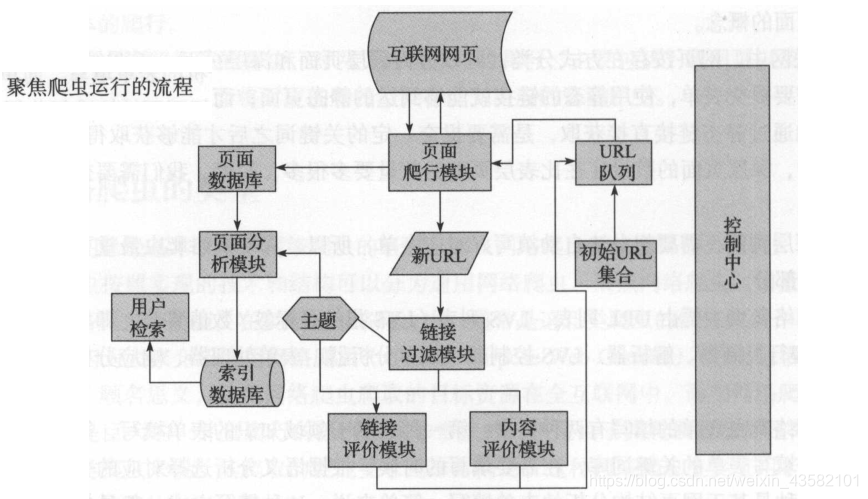
聚焦网络爬虫,主要应用在对特定信息的爬取中。将爬取的目标网页定位在与主题相关的页面中。聚焦网络爬虫主要由:URL集合、URL队列、页面爬行模块、页面分析模块、数据库、链路过滤模块等构成、
增量式网络爬虫:在网页更新的时候只更新其改变的地方,而未改变的地方则不更新。
只爬取内容发生变化的网页或者新产生的网页。
深层网络爬虫:可以爬取互联网中的深层页面。
在互联网中,网页按照存在方式进行分类,可以分为表层页面和深层页面。
所谓的 表层页面 ,指的是不需要提交表单,使用静态的链接就能够达到的静态页面。而 深层页面 则隐藏在表单后面,需要提交一定的关键词之后才能获取得到的页面。
深层网络爬虫主要由URL页面,LVS列表(;LVS指的是标签数值集合,即是填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分构成。
深层网络爬虫表单的填写有两种类型:
第一种是基于领域知识的表单填写。
第二种是基于网页结构分析的表单填写。
网络爬虫技能总览图:
搜索引擎核心:
爬虫与搜索引擎的关系是密不可分的
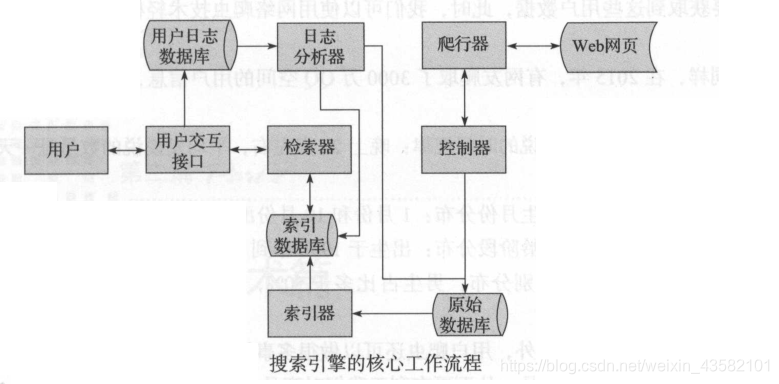
首先搜索引擎会利用爬虫模块去爬取互联网。
然后将爬取到的网页储存在原始数据库中。
接着对原始数据库中的数据进行索引、
通过用户交互借口输入对应的信息。
(用户交互借口,相当于搜索引擎的输入框)
用户输入对应信息的同事,也会将用户的行为储存到用户日志数据库,日志分析器会根据大量的用户数据去调整原始数据和索引数据库,改变其排名结果或进行其他操作。
用户爬虫的一些事:
用户爬虫也是网络爬虫中的一种类型。
专门来爬虫互联网中用户数据的一种爬虫。
比如爬取淘宝的用户信息,对知乎的用户数据进行爬取等。
爬虫的出现,可以在一定的程度上代替手工访问网页。
网络爬虫实现原理详解:
不同类型的网络爬虫,其实现的原理也是不同的。
我在此以两种典型的网络爬虫为例。(通用网络爬虫和聚焦网络爬虫),分析下网络爬虫的是实现原理。
通用网络爬虫:
1、获取初始的URL
2、根据初始的URL爬取页面并获取新的URL
3、将新的URL放到URL队列中。
4、从URL队列中读取新的URL、并根据新的URL爬取网页。同时从新网页上获取新URL,重复爬取过程。
5、满足爬虫系统设置的停止条件时,停止爬取。
- 1
- 2
- 3
- 4
- 5
聚焦网络爬虫:
聚焦网络爬虫,由于其需要有目的地进行爬取,必须要增加对目标的定义和过滤机制。
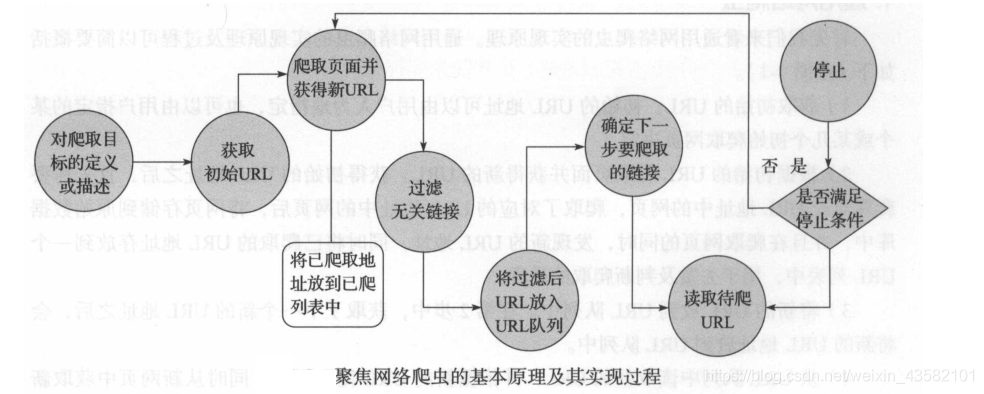
1、对爬取目标的定义和描述。
2、获取初始的URL
3、根据初始的URL爬取页面并获取新的URL
4、从新的URL中过滤掉与爬取目标无关的链接。
5、讲过滤后的链接放到URL队列中。
6、从URL队列中根据搜索算法、确定URL的优先级。并确定下一步要爬取的URL地址。
7、根据新的URL爬取网页。同时从新网页上获取新URL,重复爬取过程。
8、满足爬虫系统设置的停止条件时,停止爬取。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
爬行策略:
爬行策略简意来说是爬行的顺序。
主要由深度优先爬行策略,广度优先爬行策略、大站优先策略、反链策略、其他爬行策略等。
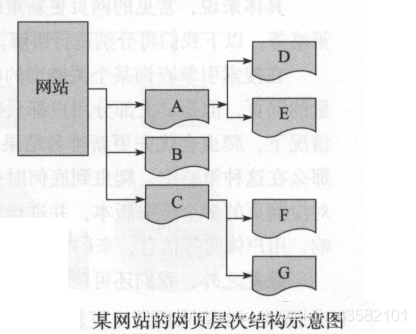
假如此时网页ABCDEFG都在爬行队列中,name按照不同的爬行策略,其爬取的顺序是不同的。
若按深度优先爬行策略,爬行顺序是A>D>E>B>C>F>G
按照广度优先爬行策略去爬取,顺序是A>B>C>D>E>F>G
我们还可以采用大战爬行策略。也是说网页数量越多的网站,爬取的优先级越高。
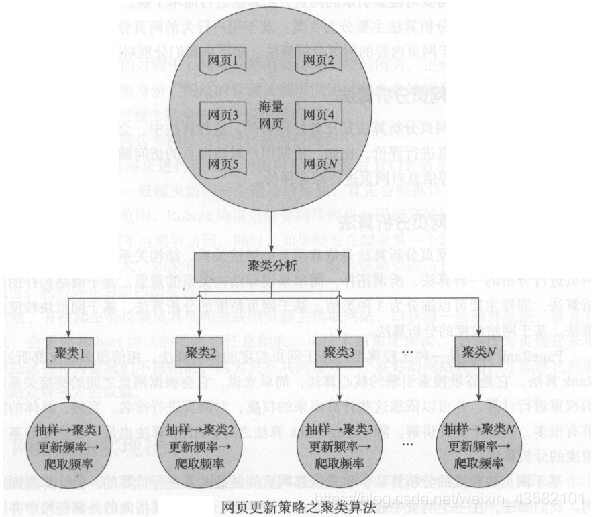
网页更新策略:
作为爬虫放,在网页更新后,我们也需要针对更新的网页部分进行调整,重新爬取。爬虫也需要根据对应策略,让不同的网页具有不同的更新优先级,优先级搞的网页更新,将获得较快的爬行响应。
**聚类分析策略。**将共性较多的聚为一类。既依据“物以类聚”的思想去实现。
网页分析算法:
搜索引擎的网页分析算法主要分为3类:基于用户行为的网页分析算法,基于网络拓扑的网页分析算法,基于网页内容的网页分析算法。
1:基于用户行为的网页分析算法
这种算法师根据用户对这些网页的访问行为,对这些网页进行评价。
2:基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是依靠网页的链接关系、结构关系、已知网页或数据进行分析的一种算法。
3:基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会依据网页的数据,文本等网页内容特征,对网页进行相应的评价。
身份识别:
身份识别是很有趣的一块,在爬虫对网页爬取的过程中,爬虫必须要访问对应的网页,正规的爬虫一般都会告诉对应网站站长其爬虫身份,网站的管理员则可以通过爬虫告知的身份信息对爬虫的身份进行识别。这个过程就是爬虫的身份识别过程。
一般来说,爬虫在对网页进行爬取访问的时候,会通过HTTP请求中的User Agent字段告知自己的身份信息。一般爬虫访问一个网站的时候,首先会根据该站点下的Rbots.txt文件来确定可爬取的网页范围,Robots协议是需要网络爬虫共同遵守的协议。对于一些禁止的URL地址,网络爬虫不应爬取访问。同时,如果爬取某一个站点时陷入死循环,造成该站点的服务压力过大,如果有正确的身份设置,name改站点的站长则可以想办法联系到改爬虫方,然后停止对应的爬虫程序。
当然,有些爬虫会伪装成其他爬虫或浏览器去爬取网站,去获得一些额外数据,或者有些爬虫会无视Robots协议的限制而任意爬取。从技术的角度来说,这些行为实现起来并不难,但是这些行为是不提倡的!
因为只有共同遵守一个良好的网络规则,才能够达到爬虫方和站点服务方的双赢。
内容总结:
本篇内容介绍了什么是网络爬虫,网络爬虫技能总览,及网路爬虫实现原理和实现技术等概念。
如果对文章内容感兴趣的话,可以查看后续文章或留言联系我。
ps----本文一部分内容自python网络爬虫书籍中。我阅读了一遍后,重新挑出了其重要部分进行整合,言简意赅。
下一篇内容:Python爬虫之Urllib全方位解析
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/86563910

- 点赞
- 收藏
- 关注作者
评论(0)