Scrapy中Chrome和PhantomJS设置代理

【摘要】
需求是对 一些小规模的数据,在搜狗微信上搜索关键词的文章数量。 为了避开搜狗非人的爬虫检测策略。我采用了 Selenium来完成这个业务。
首先在 middlewares 定义了一个 WebDriv...
需求是对 一些小规模的数据,在搜狗微信上搜索关键词的文章数量。
为了避开搜狗非人的爬虫检测策略。我采用了 Selenium来完成这个业务。
首先在 middlewares 定义了一个 WebDriverMiddleware 中间键:

settings 中 需要开启中间键:

在scrapy中的 中间键定义Webdriver,这样在每次请求都会切换IP 启动驱动。
下面分别介绍下两种驱动设置代理的方法:
Chrome :
from selenium import webdriver
from scrapy.http import HtmlResponse
from selenium.webdriver import ChromeOptions
from scrapy.downloadermiddlewares.retry import RetryMiddleware
class WebDriverMiddleware(RetryMiddleware): # RetryMiddleware 重试类
option = ChromeOptions() # 实例化驱动通信参数
option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) #不加载图片
option.add_argument('connection="close"') # 关闭连接状态
option.add_experimental_option('excludeSwitches', ['enable-automation']) # 开发者模式(可不使用)
def process_request(self, request, spider):
if spider.name == 'SouGou_Wechect':
proxies = '111.11.11.1:1111'
self.option.add_argument('--proxy-server=http://{}'.format(proxies)) # 添加代理
browser = webdriver.Chrome(options=self.option)
browser.get(request.url)
data = browser.page_source.encode('utf-8')
browser.quit()
return HtmlResponse(request.url, body=data, encoding='utf-8', request=request)
# TODO 当IP被ban掉之后,返回request,重新请求
def process_response(self, request, response, spider):
if spider.name == 'SouGou_Wechect':
proxy_error = re.findall('我们的系统检测到您网络中存在异常访问请求',response.text,re.S)
if proxy_error:
return self._retry(request, response.body, spider) or response
else:
return response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
完成了,在spider中,只需要调用 respnse.body 就可以获取请求到的页面内容了。
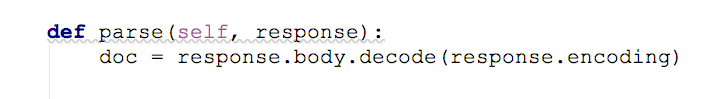
PhantomJS:
其实基本上是一样的,自行查看。
import re
from selenium import webdriver
from scrapy.http import HtmlResponse
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class WebDriverMiddleware(RetryMiddleware):
def process_request(self, request, spider):
if spider.name == 'SouGou_Wechect':
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/603.2.4 (KHTML, like Gecko) Version/10.1.1 Safari/603.2.4',
'Connection': 'close'
}
cap = DesiredCapabilities.PHANTOMJS.copy()
for key, value in headers.items():
cap['phantomjs.page.customHeaders.{}'.format(
key)] = value
browser = webdriver.PhantomJS(
desired_capabilities=cap, # 设置请求头部
service_args= [
'--proxy=%s' % ‘111.11.11.1:1111’, # 设置代理IP
'--proxy-type=https', # 声明代理方法
'--load-images=no', # 关闭图片加载
]
)
browser.get(request.url)
data = browser.page_source
data = data.encode('utf-8')
browser.quit()
return HtmlResponse(request.url, body=data, encoding='utf-8', request=request)
def process_response(self, request, response, spider):
if spider.name == 'SouGou_Wechect':
proxy_error = re.findall('我们的系统检测到您网络中存在异常访问请求',response.text,re.S)
if proxy_error:
return self._retry(request, response.body, spider) or response
else:
return response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/102518306

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)