高并发之伪共享和缓存行填充(缓存行对齐)(@Contended)

✨ 我是喜欢分享知识、喜欢写博客的YuShiwen,与大家一起学习,共同成长!
📢 闻到有先后,学到了就是自己的,大家加油!
📢 导读:
本期总共有五个章节,
⛳️ 第一个章节是举例子,让大家感受一下使用缓存行(Cache Line)填充速度快到飞起的感jio;
⛳️ 第二个章节是关于内存、缓存与寄存器之间如何传输数据,让大家先掌握以下底层知识;
⛳️ 第三个章节是抛出伪共享这个问题,介绍了什么是伪共享;
⛳️ 第四个章节是如何解决缓存的伪共享问题(可以利用缓存行填充的方式或者@Contended注解);
⛳️ 第五个章节是完整的代码,关于缓存行(Cache Line)填充前后的完整代码。
大家可以利用这个来对代码进行调优,希望大家可以耐心看完,保证会有所收获,该篇文章笔者花费两天时间创作完成,质量不会差,大家加油!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.使用缓存行(Cache Line)填充前后对比
伪共享和缓存行填充,我们先看一个例子,让大家感受一下了解底层知识后,你的代码可以快到起飞的感jio:
在类中定义看似无用的成员属性,速度有质的提升。
如下是未使用缓存行(Cache Line)填充方法运行的结果,可以看到耗时是3579毫秒:

而在其变量x的前后加上7个long类型到变量(在变量x前56Byte,后面也是56Byte,这就是缓存行填充,下面章节会详细介绍),当然这个14个变量是不会在代码中被用到的,但是为什么速度会提升将近2倍呢,如下图所示,可以看到耗时为1280毫秒:

ps:上面两个截图中的完整代码见章节5,大家也可以直接跳转到章节去看下完整的代码。
为什么会这么神奇,这里为先提前说下结论,具体的大家可以往后看。
- 缓存一致性是根据缓存行(Cache line)为单元来进行同步的,即缓存中的传输单元为缓存行,一个缓存行大小通常为64Byte;
- 缓存行的内容一发生变化,就需要进行缓存同步;
- 所以虽然用到的不是同一个数据,但是他们(数据X和数据Y)在同一个缓存行中,缓存行的内容一发生变化,就需要进行缓存同步,这个同步是需要时间的。
2.内存、缓存与寄存器之间如何传输数据
为什么会这样呢?前面我们提到过缓存一致性的问题,见笔者该篇博文:“了解高并发底层原理”,面试官:讲一下MESI(缓存一致性协议)吧,点击文字即可跳转。
其中内存、缓存与寄存器之间的关系图大致如下:

硬盘中的可执行文件加载到寄存器中进行运算的过程如下:
- 硬盘中的可执行文件(底层存储还是二进制的)加载到内存中,操作系统为其分配资源,变成了一个进程A,此时还没有跑起来;
- 过了一段时间之后,CPU0的时间片分配给了进程A,此时CPU0进行线程的装载,然后把需要用到的数据先从内存中读取到缓存中,读取的单元为一个缓存行,其大小现在通常为64字节(记住这个缓存行大小为64字节,这个非常重要,在后面会多次用到这个数值)。
- 然后数据再从缓存中读取到寄存器中,目前缓存一般为三级缓存,这里不具体画出。
- 寄存器得到了数据之后送去ALU(arithmetic and logic unit)做计算。
这里说一下为什么要设计三级缓存:
- 电脑通过使用时钟来同步指令的执行。时钟脉冲在一个固定的频率(称为时钟频率)。当你买了一台1.5GHz的电脑,1.5GHz就是时钟频率,即每秒15亿次的时钟脉冲,一次完整的时钟脉冲称为一个周期(cycle),时钟并不记录分和秒。它以不变的速率简单跳动。
- 其主要原因还是因为CPU方法内存消耗的时间太长了,CPU从各级缓存和内存中读取数据所需时间如下:
| CPU访问 | 大约需要的周期(cycle) | 大约需要的时间 |
|---|---|---|
| 寄存器 | 1 cycle | 0ns |
| L1 Cache | 3—4 cycle | 1ns |
| L2 Cache | 10—20 cycle | 3ns |
| L3 Cache | 40—45 cycle | 15ns |
| 内存 | 60—90ns |
3.缓存中数据共享问题(真实共享和伪共享)
3.1 真实共享(不同CPU的寄存器中都到了同一个变量X)
首先我们先说数据的真实共享,如下图,我们在CPU0和CPU1中都用到了数据X,现在不考虑数据Y。

如果不考虑缓存一致性,会出现如下问题:
在多线程情况下,此时由两个cpu同时开始读取了long X =0,然后同时执行如下语句,会出现如下情况:
int X = 0;
X++;
- 1
- 2
刚开始,X初始化为0,假设有两个线程A,B,
- A线程在CPU0上进行执行,从主存加载X变量的数值到缓存,然后从缓存中加载到寄存器中,在寄存器中执行X+1操作,得到X的值为1,此时得到X等于1的值还存放在CPU0的缓存中;
- 由于线程A计算X等于1的值还存放在缓存中,还没有刷新会内存,此时线程B执行在CPU1上,从内存中加载i的值,此时X的值还是0,然后进行X+1操作,得到X的值为1,存到CPU1的缓存中,
- A,B线程得到的值都是1,在一定的时间周期之后刷新回内存
- 写回内存后,两次X++操作之后,其值还是1;
可以看到虽然我们做了两次++X操作,但是只进行了一次加1操作,这就是缓存不一致带来的后果。
如何解决该问题:
- 具体的我们可以通过MESI协议(详情见笔者该篇博文:https://blog.csdn.net/MrYushiwen/article/details/123049838)来保证缓存的一致性,如上图最中间的红字所示,在不同寄存器的缓存中,需要考虑数据的一致性问题,这个需要花费一定的时间来同步数据,从而达到缓存一致性的作用。
3.2伪共享(不同CPU的寄存器中用到了不同的变量,一个用到的是X,一个用到的是Y,并且XY在同一个缓存行中)
- 缓存一致性是根据缓存行(Cache line)为单元来进行同步的,即缓存中的传输单元为缓存行,一个缓存行大小通常为64Byte;
- 缓存行的内容一发生变化,就需要进行缓存同步;
- 在3.1中,我们在寄存器用到的数据是同一个X,他们肯定是在同一个缓存行中的,这个是真实的共享数据的,共享的数据为X。
- 而在3.2中,不同CPU的寄存器中用到了不同的变量,一个用到的是X,一个用到的是Y,但是变量X、Y在同一个缓存行中(一次读取64Byte,见3.1中的图),缓存一致性是根据缓存行为单元来进行同步的,所以虽然用到的不是同一个数据,但是他们(数据X和数据Y)在同一个缓存行中,他们的缓存同步也需要时间。


4.伪共享解决办法(缓存行填充或者使用@Contended注解)
4.1.缓存行填充
如章节一所示,我们可以在x变量前后进行缓存行的填充,:
public volatile long A,B,C,D,E,F,G;
public volatile long x = 1L;
public volatile long a,b,c,d,e,f,g;
- 1
- 2
- 3
添加后,3.2章节中的截图将会变成如下样子:

不论如何进行缓存行的划分,包括x在内的连续64Byte,也就是一个缓存行不可能存在变量Y,同样变量Y所在的缓存行不可能存在x,这样就不存在伪共享的情况,他们之间就不需要考虑缓存一致性问题了,也就节省了这一部分时间。
4.2.Contended注解
在Java 8中,提供了@sun.misc.Contended注解来避免伪共享,原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。我们目前的缓存行大小一般为64Byte,这里Contended注解为我们前后加上了128字节绰绰有余。
注意:如果想要@Contended注解起作用,需要在启动时添加JVM参数-XX:-RestrictContended 参数后 @sun.misc.Contended 注解才有。
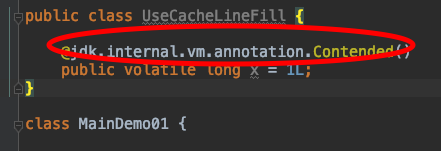
然而在java11中@Contended注解被归类到模块java.base中的包jdk.internal.vm.annotation中,其中定义了Contended注解类型。笔者用的是java12,其注解如下:

加上该注解,如下,也能达到缓存行填充的效果
5.完整代码(利用缓存行填充和没用缓存行填充)
大家自己也可以跑一下如下代码,看利用缓存行填充后的神奇效果。
5.1没用缓存行填充代码如下:
package mesi;
import java.util.concurrent.CountDownLatch;
/**
* @Author: YuShiwen
* @Date: 2022/2/27 2:52 PM
* @Version: 1.0
*/
public class NoCacheLineFill {
public volatile long x = 1L;
}
class MainDemo {
public static void main(String[] args) throws InterruptedException {
// CountDownLatch是在java1.5被引入的,它是通过一个计数器来实现的,计数器的初始值为线程的数量。
// 每当一个线程完成了自己的任务后,调用countDown方法,计数器的值就会减1。
// 当计数器值到达0时,它表示所有的线程已经完成了任务,然后调用await的线程就可以恢复执行任务了。
CountDownLatch countDownLatch = new CountDownLatch(2);
NoCacheLineFill[] arr = new NoCacheLineFill[2];
arr[0] = new NoCacheLineFill();
arr[1] = new NoCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 100_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
//等待线程A、B执行完毕
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
5.2利用缓存行填充代码如下:
package mesi;
import java.util.concurrent.CountDownLatch;
/**
* @Author: YuShiwen
* @Date: 2022/2/27 3:45 PM
* @Version: 1.0
*/
public class UseCacheLineFill {
public volatile long A, B, C, D, E, F, G;
public volatile long x = 1L;
public volatile long a, b, c, d, e, f, g;
}
class MainDemo01 {
public static void main(String[] args) throws InterruptedException {
// CountDownLatch是在java1.5被引入的,它是通过一个计数器来实现的,计数器的初始值为线程的数量。
// 每当一个线程完成了自己的任务后,调用countDown方法,计数器的值就会减1。
// 当计数器值到达0时,它表示所有的线程已经完成了任务,然后调用await的线程就可以恢复执行任务了。
CountDownLatch countDownLatch = new CountDownLatch(2);
UseCacheLineFill[] arr = new UseCacheLineFill[2];
arr[0] = new UseCacheLineFill();
arr[1] = new UseCacheLineFill();
Thread threadA = new Thread(() -> {
for (long i = 0; i < 1_000_000_000L; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
}, "ThreadA");
Thread threadB = new Thread(() -> {
for (long i = 0; i < 1_000_000_000L; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
}, "ThreadB");
final long start = System.nanoTime();
threadA.start();
threadB.start();
//等待线程A、B执行完毕
countDownLatch.await();
final long end = System.nanoTime();
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
我是喜欢分享知识、喜欢写博客的YuShiwen,与大家一起学习,共同成长!咋们下篇博文见。
已完结
于CSDN
2022.3.1
author:YuShiwen
文章来源: blog.csdn.net,作者:Mr.Yushiwen,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/MrYushiwen/article/details/123171635

- 点赞
- 收藏
- 关注作者
评论(0)