Hadoop之HDFS03【NameNode工作原理】

NameNode的职责
| 序号 | 职责 |
|---|---|
| 1 | 负责客户端请求的响应 |
| 2 | 元数据的管理(查询,修改) |
数据存储的形式
NameNode中的元数据信息以三种形式存储,如下
| 序号 | 方式 | 说明 |
|---|---|---|
| 1 | 内存元数据(NameSystem) | 读写效率高 |
| 2 | 磁盘元数据镜像文件 | 持久化 |
| 3 | 数据操作日志文件(可通过日志运算出元数据) | 内存和磁盘数据同步的桥梁 |
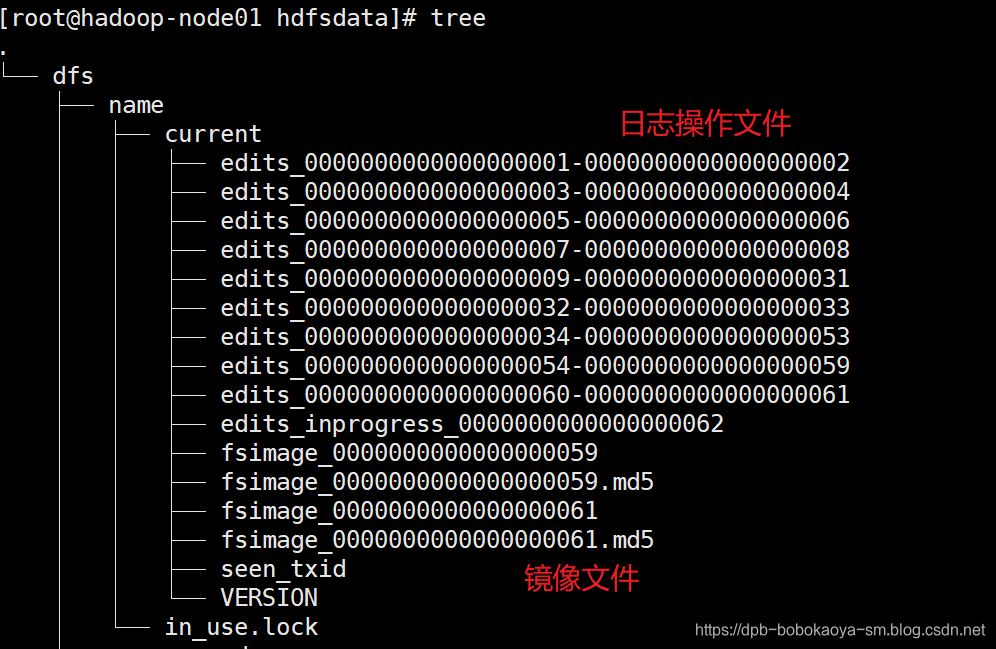
数据存储的机制
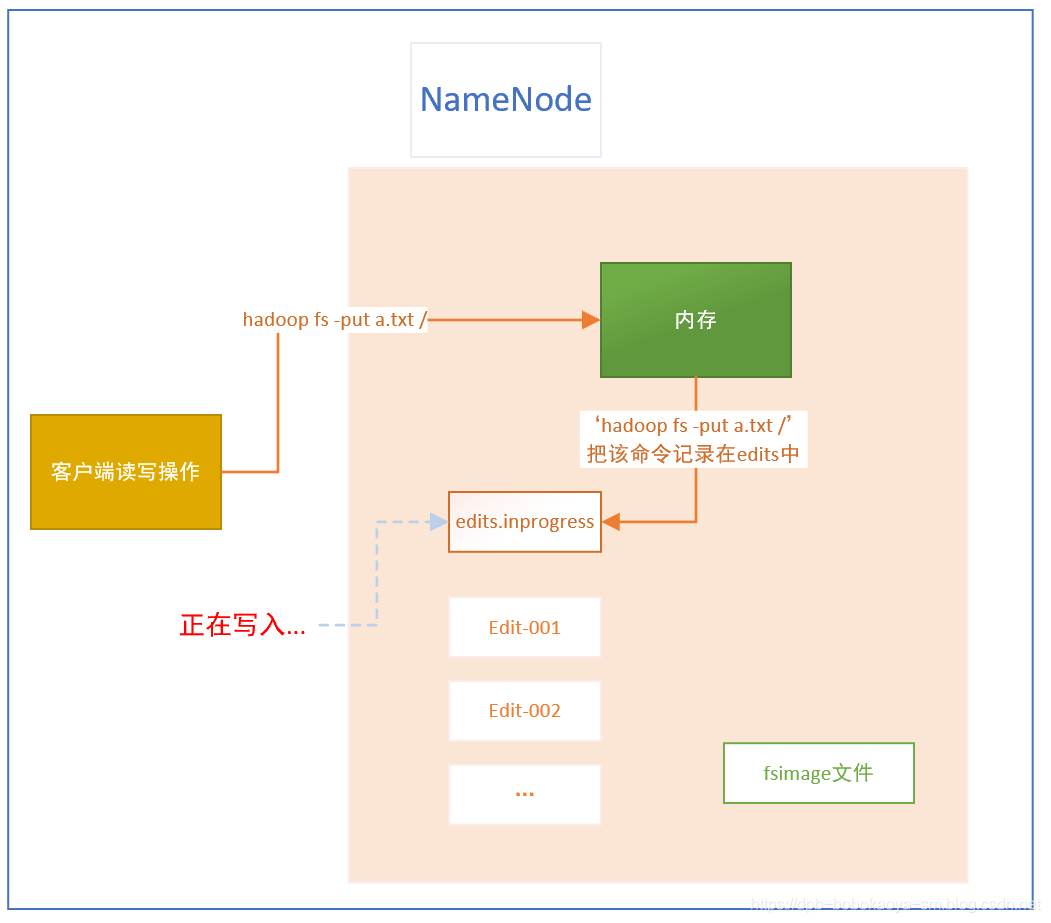
-
内存中有一份完整的元数据(内存meta data)
-
磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)

-
用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
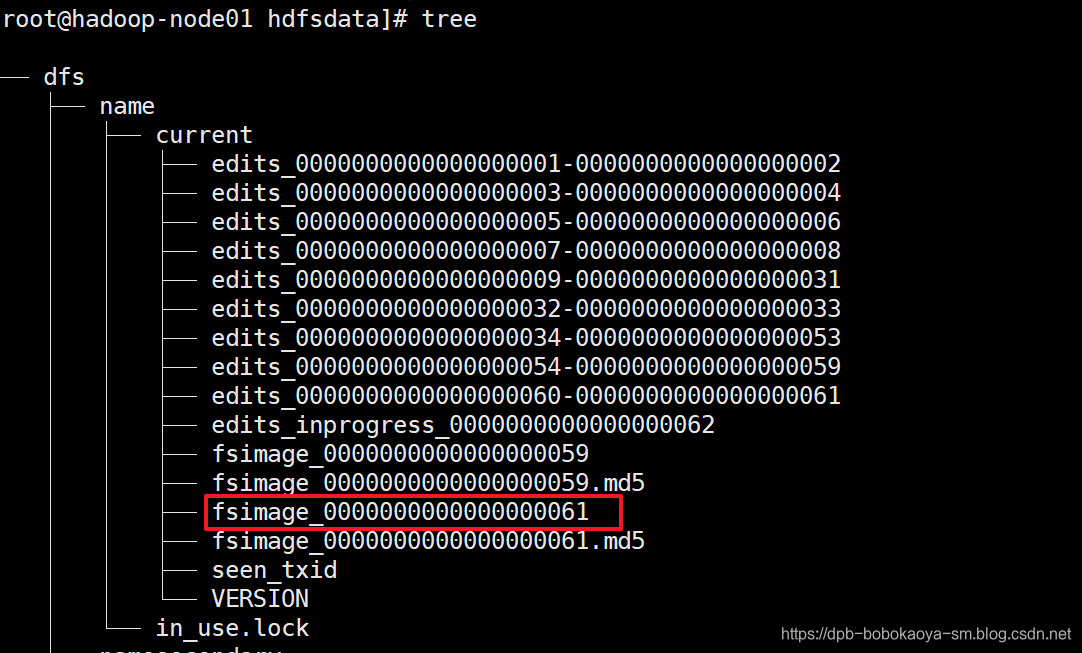
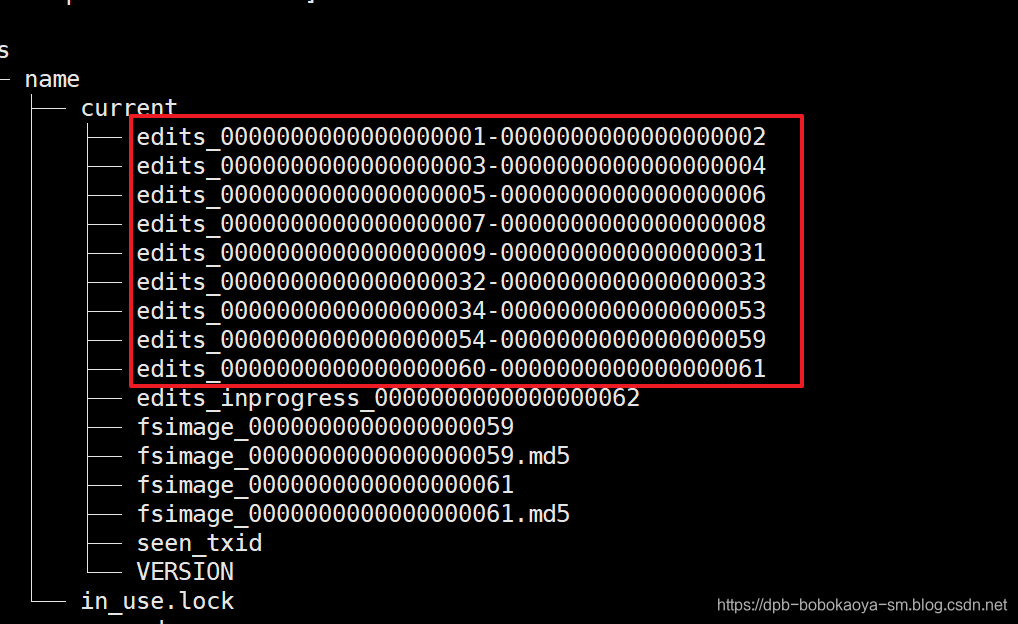
checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
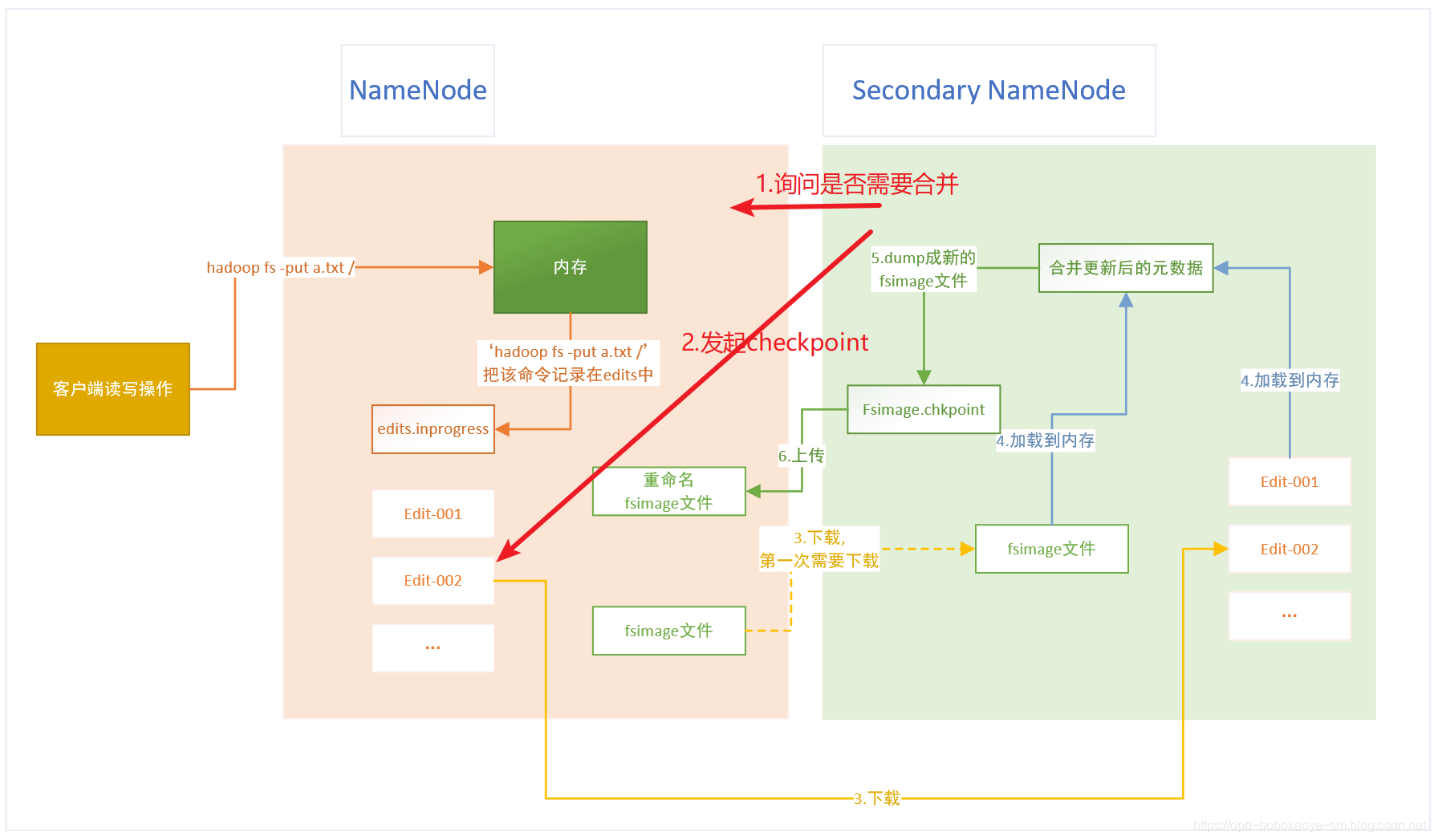
edits_inprogress_xxx:表示正在写入操作日志的文件,当发起checkpoint的时候会把该文件更新为edits-000xxxx表示停止写入,并生成一个新的edits_inprogress_xxx文件来记录在checkpoint中同步产生的操作日志数据。
注意:
日志文件是滚动的,一个正在写,几个已写好的,checkpoint的时候,把正在写的滚动一下,然后把fsimage文件和日志文件下载到secondaryNameNode机器上,完成同步,只有第一次才会下载fsimage文件,这时不会很大,下一次的时候secondaryNameNode上就有fsimage文件了就只需要下载日志文件即可,单个日志文件不会很大。
思考问题
- namenode如果宕机,hdfs服务是否能够正常提供
- 如果namenode的硬盘损坏,元数据是否还能恢复?如果能恢复如何恢复?
- 通过以上问题,我们在配置namenode的工作目录参数的时候有什么要注意的?
VERSION
#Tue Apr 02 10:39:49 CST 2019
namespaceID=310844358
clusterID=CID-5d42338e-6111-4be0-b425-3d6c80a3acd8
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1966867742-192.168.88.61-1554172789025
layoutVersion=-60
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成;
- storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
- cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
- layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
- clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;
seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits

思考问题答案:
1.不能,secondaryNameNode 虽然有元数据信息,但不能更新元数据,不能充当namenode使用
2.可以恢复绝大部分数据,没有合并的数据还是会丢失
3.namenode的工作目录应该配置在多块磁盘上,同时往2块磁盘写日志。
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/name1,/home/hadoop/name2</value>
</property>
- 1
- 2
- 3
- 4
文章来源: dpb-bobokaoya-sm.blog.csdn.net,作者:波波烤鸭,版权归原作者所有,如需转载,请联系作者。
原文链接:dpb-bobokaoya-sm.blog.csdn.net/article/details/88980083

- 点赞
- 收藏
- 关注作者
评论(0)