Hadoop之MapReduce03【wc案例流程分析】

【摘要】
上篇文件介绍了自定义wordcount案例的实现,本文来介绍下具体的执行流程
流程图
流程说明
1.当客户端提交submit的时候客户端程序会根据我们输入的/wordcount/input地...
上篇文件介绍了自定义wordcount案例的实现,本文来介绍下具体的执行流程
流程图
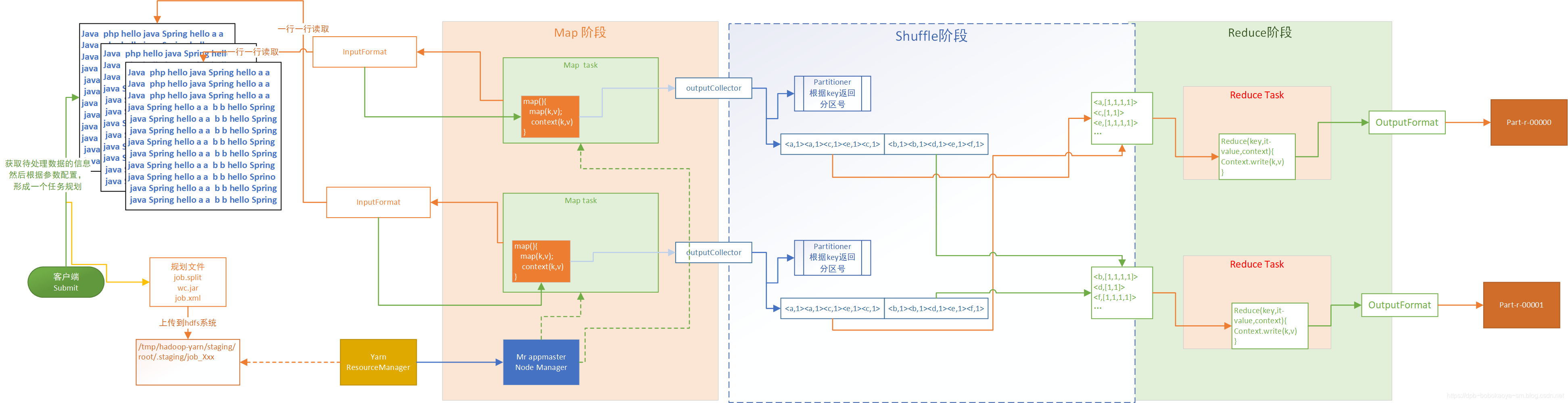
流程说明
1.当客户端提交submit的时候客户端程序会根据我们输入的/wordcount/input地址找到需要统计的数据,根据我们的配置信息得到任务规划文件
2.将任务规划文件上传到hdfs指定的位置。
hadoop fs -ls /tmp/hadoop-yarn/staging/root/.staging/job_1554281786018_0002
- 1

3.客户端将任务提交到yarn中,ResourceManager根据规划文件中指定的切片规则通过mr appmaster在nodeManager上启动对应的MapperTask。
4.每个MapperTask根据指定的切片任务去加载数据,通过InputFormat的实现一行一行的读取数据,每读取一行会调用我们自定义的map方法处理这行的信息
5.map阶段输出的数据会被outputCollector采集。
6.outputCollector中的数据通过partitionner对数据做分区操作。将不同的数据分配到不同的分区中。
7.Reduce阶段根据配置会创建对应的ReduceTask来汇总数据(分组排序)。
8.将key相同的数据加载到自定义的reduce方法中,通过OutputFormat输出汇总结果。
本文仅仅对流程做大概分析,并为涉及到yarn工作调度的细节。后面会详细介绍~
文章来源: dpb-bobokaoya-sm.blog.csdn.net,作者:波波烤鸭,版权归原作者所有,如需转载,请联系作者。
原文链接:dpb-bobokaoya-sm.blog.csdn.net/article/details/89003569

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)