007:Scrapy核心架构和高级运用

本篇内容:
Scrapy核心架构和其组件的功能
Scrapy的工作流
Scrapy的中文输出储存
介绍CrawSpider
编写了一个爬虫实战来进行我们的mysql数据库操作
Scrapy的核心架构
如下图所示:
主要组件包括了Scrapy引擎,调度器,管道,下载中间件,下载器,spider蜘蛛,爬虫中间件,实体管道(Item Pipeline)等。
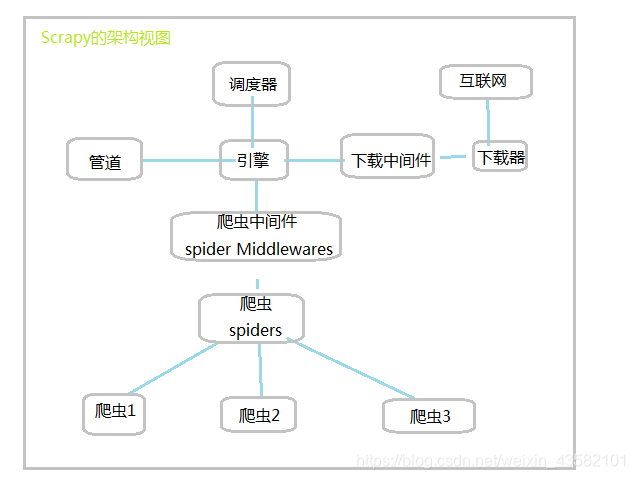
1、Scrapy引擎:
scrapy引擎是整个scrapy架构的核心,负责控制整个数据处理流程,以及一些事物吃力。scrapy引擎与调度器、实体管道、中间件、下载器等组件都有关系,其出入整个框架的中心位置,对各项组件进行控制及协调。
2、调度器:
调度器主要实现储存待爬取的网址,并确定这些网址的优先级,决定下一次爬取哪个网址等。调度器会从引擎中接收request请求并存入优先队列中。
3、下载器:
下载器主要实现对网络上要爬取的网页资源进行高速下载,由于该组件需要通过网络进行大量数据的传输,所以该组件的压力负担也会比其他的多。下载器下载了对应的网页资源后,也会将这些数据传递给Scrapy引擎,再由Scrapy引擎传递给对应的爬虫进行处理。
4、下载中间件:
下载中间件是处于下载器和引擎之间的一个特定的组件。是用于全局修改Scrapy request和response的一个轻量、底层的系统。
5、蜘蛛spider:
spider是定义如何抓取某个网站(或一组网站)的类,包括如何执行抓取(即关注链接)以及如何从其网页中提取结构化数据(即抓取项目)。换句话说,Spider是您定义用于为特定网站(或在某些情况下,一组网站)抓取和解析网页的自定义行为的位置。
6、爬虫中间件:
爬虫中间件是处于Scrapy引擎与爬虫组件之间的一个特定的组件,主要用于对爬虫组件和Scrapy引擎之间的通信进行处理。同时,在爬虫中间件中可以加入一些自定义代码,很轻松的实现Scrapy功能的扩展。
7、实体管道:
实体管道主要用于接收从蜘蛛组件中提取出来的项目。接收后,会对这些item进行对应的处理。常见的处理主要由:清洗、验证、储存到数据库中。
Scrapy工作流
我们已经知道了Scrapy框架中主要由哪些组件,以及各项组件的具体作用有什么呢,各项数据在组件中又是怎么进行的呢。
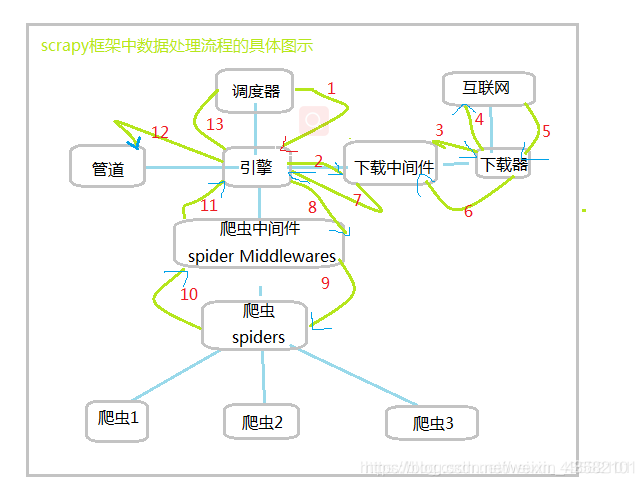
1、将网址传递给scrapy引擎。
2、scrapy引擎将网址传给下载中间件
3、下载中间键将网址给下载器
4、下载器像网址发送request请求进行下载
5、网址接收请求,将响应返回给下载器
6、下载器将收到的响应返回给下载中间件
7、下载中间件与scrapy引擎通信
8、scrapy将response响应信息传递给爬虫中间件
9、爬虫中间件将响应传递给对应的爬虫进行处理
10、爬虫处理之后,会提取出来的数据和新的请求信息,将处理的信息传递给爬虫中间件
11、爬虫中间件将处理后的信息传递给Scrapy引擎
12、scrapy接收到信息之后,会将项目实体传递给实体管道进行进一步处理,同时将新的信息传递给调度器。
13、随后再重复执行1-12步,一直到调度器中没有网址或异常退出为止。
以上就是Scrapy框架中各项组件的工作流程。此时相信我们队Scrapu框架数据处理的过程就又了比较详细的了解。
Scrapy中文输出与中文存储
使用Scrapy抓取中文时,输出一般是unicode,要输出中文也只需要稍作改动。
单纯交互输出
如代码:
title = sel.xpath('a/text()').extract()
print title
- 1
- 2
此时输出的是title对应中文的unicode格式,只需要指定“utf-8”编码即可输出中文,如下:
title = sel.xpath('a/text()').extract()
for t in title:
print t.encode('utf-8')
- 1
- 2
- 3
这里需要注意的是“encode()”函数是字符串专有的,而title是一个列表,因此需要对title中的每一个执行该操作。
存储
存储中文数据可以利用pipeline实现
1.定义pipeline
#coding: utf-8
import codecs
import json
class TutorialPipeline(object):
def __init__(self):
self.file = codecs.open('data_cn.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上述方法将得到的item解码,以便正常显示中文,并保存到定义的json文件中。
2.注册自定义的pipeline
为了启动pipeline,必须将其加入到“ITEM_PIPLINES”的配置中,在settings.py中加入下面一句:
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline':300
}
- 1
- 2
- 3
其中根目录是tutorial,pipelines是我的pipeline文件名,TutorialPipeline是类名
CrawlSpider详解:
在Scrapy基础——Spider中,我简要地说了一下Spider类。Spider基本上能做很多事情了,但是如果你想爬取知乎或者是简书全站的话,你可能需要一个更强大的武器。
CrawlSpider基于Spider,但是可以说是为全站爬取而生。
简要说明:
-
CrawlSpider是爬取那些具有一定规则网站的常用的爬虫,它基于Spider并有一些独特属性rules:
是Rule对象的集合,用于匹配目标网站并排除干扰 -
parse_start_url: 用于爬取起始响应,必须要返回Item,Request中的一个。
-
因为rules是Rule对象的集合,所以这里也要介绍一下Rule。它有几个参数:link_extractor、callback=None、cb_kwargs=None、follow=None、process_links=None、process_request=None
-
其中的link_extractor既可以自己定义,也可以使用已有LinkExtractor类,主要参数为:
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
allow_domains:会被提取的链接的domains。
deny_domains:一定不会被提取链接的domains。
restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。还有一个类似的restrict_css
问题:CrawlSpider如何工作的?
因为CrawlSpider继承了Spider,所以具有Spider的所有函数。
首先由start_requests对start_urls中的每一个url发起请求,这个请求会被parse接收。
在Spider里面的parse需要我们定义,但CrawlSpider定义parse去解析响应。
根据有无callback,follow和self.follow_links执行不同的操作
def _parse_response(self, response, callback, cb_kwargs, follow=True): ##如果传入了callback,使用这个callback解析页面并获取解析得到的reques或item
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res) for requests_or_item in iterate_spider_output(cb_res): yield requests_or_item ## 其次判断有无follow,用_requests_to_follow解析响应是否有符合要求的link。
if follow and self._follow_links:
for request_or_item in self._requests_to_follow(response): yield request_or_item
- 1
- 2
- 3
- 4
- 5
- 6
爬取豆瓣电影前250信息:
为了讲解后面的操作数据到数据库,这里插入scrapy框架爬取豆瓣网站信息。
首先创建项目,cmd输入命令
scrapy startproject doubanmovie
- 1
在spiders文件夹下创建文件MySpider.py。
在MySpider.py中创建类DoubanMovie继承自scrapy.Spider,同时定义以下属性和方法
name : 爬虫的唯一标识符
start_urls : 初始爬取的url列表
parse() : 每个初始url访问后生成的Response对象作为唯一参数传给该方法,该方法解析返回的Response,提取数据,生成item,同时生成进一步要处理的url的request对象
在settings文件中添加下面一行:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
- 1
在doubanmovie文件夹下创建文件MovieItems.py,在该文件下编写存放爬取到的数据的容器
创建类MovieItem继承自scrapy.Item,定义各种属性,语句类似以下
name = scrapy.Field()
- 1
整个parse()方法代码如下
def parse(self, response):
selector = scrapy.Selector(response)
# 解析出各个电影
movies = selector.xpath('//div[@class="item"]')
# 存放电影信息
item = MovieItem()
for movie in movies:
# 电影各种语言名字的列表
titles = movie.xpath('.//span[@class="title"]/text()').extract()
# 将中文名与英文名合成一个字符串
name = ''
for title in titles:
name += title.strip()
item['name'] = name
# 电影信息列表
infos = movie.xpath('.//div[@class="bd"]/p/text()').extract()
# 电影信息合成一个字符串
fullInfo = ''
for info in infos:
fullInfo += info.strip()
item['info'] = fullInfo
# 提取评分信息
item['rating'] = movie.xpath('.//span[@class="rating_num"]/text()').extract()[0].strip()
# 提取评价人数
item['num'] = movie.xpath('.//div[@class="star"]/span[last()]/text()').extract()[0].strip()[:-3]
# 提取经典语句,quote可能为空
quote = movie.xpath('.//span[@class="inq"]/text()').extract()
if quote:
quote = quote[0].strip()
item['quote'] = quote
# 提取电影图片
item['img_url'] = movie.xpath('.//img/@src').extract()[0]
yield item
next_page = selector.xpath('//span[@class="next"]/a/@href').extract()[0]
url = 'https://movie.douban.com/top250' + next_page
if next_page:
yield scrapy.Request(url, callback=self.parse)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
数据存储:
目前选择将数据存放在json文件中,对数据库的处理在下面会讲解
在doubanmovie文件夹下创建文件MoviePipelines.py,编写类MoviePipeline,重写方法process_item(self, item, spider)用于处理数据。
import scrapy
from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
image_url = [x['path'] for ok, x in results if ok]
if not image_url:
raise DropItem("Item contains no images")
item['image_url'] = image_url
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
同时在settings文件中注册并设置下载目录:
ITEM_PIPELINES = {
'doubanmovie.MoviePipelines.MoviePipeline': 1,
'doubanmovie.ImgPipelines.ImgPipeline': 100,
}
- 1
- 2
- 3
- 4
在settings文件中将ROBOTSTXT_OBEY改为False,让scrapy不遵守robot协议,即可正常下载图片
IMAGES_STORE = 'E:\\img\\'
- 1
scrapy数据存入mysql数据库:
将爬取的各种信息通过json存在文件中,不过对数据的进一步使用显然放在数据库中更加方便,这里将数据存入mysql数据库以便以后利用。
首先在项目settings文件中添加与数据库连接相关的变量
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'zzz'
MYSQL_USER = 'root'
MYSQL_PASSWD = '111'
- 1
- 2
- 3
- 4
创建数据库和表
class MovieItem(scrapy.Item):
# 电影名字
name = scrapy.Field()
# 电影信息
info = scrapy.Field()
# 评分
rating = scrapy.Field()
# 评论人数
num = scrapy.Field()
# 经典语句
quote = scrapy.Field()
# 电影图片
img_url = scrapy.Field()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
据此创建数据库表,创建数据库的时候加上DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci,以防出现乱码
create database douban DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
use douban;
CREATE TABLE doubanmovie (
name VARCHAR(100) NOT NULL, # 电影名字
info VARCHAR(150), # 电影信息
rating VARCHAR(10), # 评分
num VARCHAR(10), # 评论人数
quote VARCHAR(100), # 经典语句
img_url VARCHAR(100), # 电影图片
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在MoviePipelines.py文件中创建类DBPipeline,在其中进行对数据库的操作。
首先连接数据库,获取cursor以便之后对数据就行增删查改
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意这里charset属性为 ‘utf8’,中间没有-,在调试过程中因为这个-搞了半天
之后重载方法process_item(self, item, spider),在其中执行数据的增删查改,通过cursor编写sql语句,然后使用self.connect.commit()提交sql语句
def process_item(self, item, spider):
try:
# 插入数据
self.cursor.execute(
"""insert into doubanmovie(name, info, rating, num ,quote, img_url)
value (%s, %s, %s, %s, %s, %s)""",
(item['name'],
item['info'],
item['rating'],
item['num'],
item['quote'],
item['img_url']))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
log(error)
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
最后在settings文件中注册DBPipeline
ITEM_PIPELINES = {
'doubanmovie.MoviePipelines.MoviePipeline': 1,
'doubanmovie.ImgPipelines.ImgPipeline': 100,
'doubanmovie.MoviePipelines.DBPipeline': 10,
}
- 1
- 2
- 3
- 4
- 5
可以尝试运行了。
然而爬取的数据是250条,在数据库存储中只有239条
查看MySpider.py文件
quote = movie.xpath('.//span[@class="inq"]/text()').extract()
if quote:
quote = quote[0].strip()
item['quote'] = quote
- 1
- 2
- 3
- 4
如果网页中quote属性不存在,那么将item插入数据库时就会出错,增加一条else语句
if quote:
quote = quote[0].strip()
else:
quote = ' '
item['quote'] = quote
- 1
- 2
- 3
- 4
- 5
本篇到此为止了。本篇内容讲解了Scrapy核心架构和其组件的功能,Scrapy的工作量。以及Scrapy的中文输出储存,介绍了CrawSpider。并编写了一个爬虫实战来进行我们的mysql数据库操作。
理论上差不多可以了,后面的内容将会讲解各种实战项目,希望大家多多关注。
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/86634542

- 点赞
- 收藏
- 关注作者
评论(0)