Mysql一些面试题

1、Redis数据结构的底层实现
https://www.cnblogs.com/ysocean/p/9080942.html
2、Mysql对字段的一部分添加索引(例如一个公司的邮箱@后面都是一样的,如何只对@之前添加索引)
https://blog.csdn.net/u011383596/article/details/80359740
3、Mysql事物的隔离性有几级,分别说一下
https://www.cnblogs.com/fjdingsd/p/5273008.html
MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
4、Mysql 中EXPLAIN有何用,每个字段都啥意思
https://blog.csdn.net/weixin_39561473/article/details/88914954#EXPLAIN__SELECT__58
5、where id-1>1000会发生什么,为什么?
不会使用索引。
发生这种事情的深层原因在于:
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。 但是当使用表达式的时候,就会不使用缓存,因为这些函数的返回是会不定的易变的。
6、如何设置索引,索引是如何生效的,画图实现,索引使用了哪种结构
https://blog.csdn.net/weixin_39561473/article/details/88914954#_7
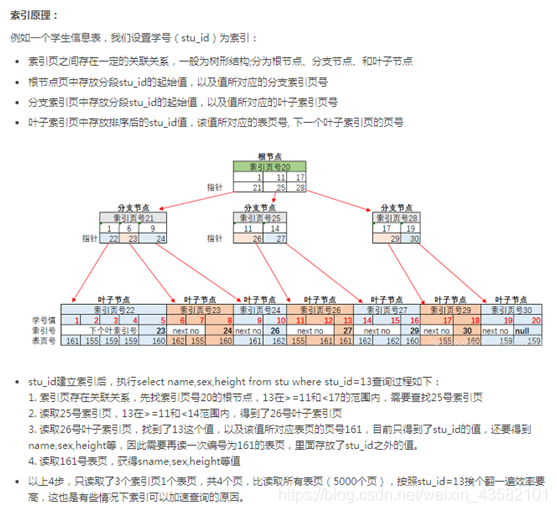
使用了b+tree结构。
7、Linux 如何使用grep筛选多个条件
grep 同时满足多个关键字和满足任意关键字
① grep -E “word1|word2|word3” file.txt
满足任意条件(word1、word2和word3之一)将匹配。
② grep word1 file.txt | grep word2 |grep word3
必须同时满足三个条件(word1、word2和word3)才匹配。
Python读取文件的时候会不会发生内存变化,例如5g文件,会不会打开的时候占用5g内存空间。
不会,因为readline是按行读取,而不是一口气全部读出来。
如果现在一台生产的数据库挂了怎么处理?
首先这题没有 get 的面试官想问的点是什么,所以就根据自己项目本身的情况做答了。我们项目生产上的数据库是有主备的,在主数据库挂掉的情况下是会切换到备数据库,先保证业务的稳定性,然后在对崩溃现场进行保留,方便后续分析问题,找到原因。这里面试官追问了一下,我们主备的切换是自动的还是手动的,这个由于是公司运维团队负责的,自己本身不是特别清楚,但是根据对公司运维团队的了解,应该是自动的。所以就这样如实的回答了。
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/89365522

- 点赞
- 收藏
- 关注作者
评论(0)