NLP自然语言处理002:NLTK中的语料和词汇资源

在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库。
NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speechtag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。
我们使用NLTK来获取文本语料库
古腾堡语料库
import nltk
直接获取语料库的所有文本:nltk.corpus.gutenberg.fileids()
doc = nltk.corpus.gutenberg.fileids()
for i in doc:
print(i)
- 1
- 2
- 3

查找某个文本
我们来查看下第一个文本 austen-emma.txt 中有多少单词。
from nltk.corpus import gutenberg
emma = gutenberg.words('austen-emma.txt')
print(len(emma))
- 1
- 2
- 3
输出结果:192427
查找文件标识符
for fileid in gutenberg.fileids():
num_char = len(gutenberg.raw(fileid)) # 原始文本的长度,包括空格、符号等
num_words = len(gutenberg.words(fileid)) #词的数量
num_sents = len(gutenberg.sents(fileid)) #句子的数量
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)])) #文本的尺寸
print(int(num_char/num_words),int(num_words/num_sents),int(num_words/num_vocab),fileid)
# 打印出平均词长(包括一个空白符号,如下词长是3)、平均句子长度、和文本中每个词出现的平均次数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果:
4 24 26 austen-emma.txt
4 26 16 austen-persuasion.txt
4 28 22 austen-sense.txt
4 33 79 bible-kjv.txt
4 19 5 blake-poems.txt
…省略不计
网络和聊天文本
获取网络聊天文本
from nltk.corpus import webtext
for fileid in webtext.fileids():
print(fileid,webtext.raw(fileid))
- 1
- 2
- 3

查看网络聊天文本信息
for fileid in webtext.fileids():
print(fileid, len(webtext.words(fileid)), len(webtext.raw(fileid)), len(webtext.sents(fileid)),
webtext.encoding(fileid))
- 1
- 2
- 3
输出结果:
firefox.txt 102457 564601 1142 ISO-8859-2
grail.txt 16967 65003 1881 ISO-8859-2
overheard.txt 218413 830118 17936 ISO-8859-2
pirates.txt 22679 95368 1469 ISO-8859-2
singles.txt 4867 21302 316 ISO-8859-2
wine.txt 31350 149772 2984 ISO-8859-2
即时消息聊天会话语料库:
from nltk.corpus import nps_chat
chatroom = nps_chat.posts('10-19-20s_706posts.xml')
chatroom[123]
- 1
- 2
- 3
输出结果:[‘i’, ‘do’, “n’t”, ‘want’, ‘hot’, ‘pics’, ‘of’, ‘a’, ‘female’, ‘,’, ‘I’, ‘can’, ‘look’, ‘in’, ‘a’, ‘mirror’, ‘.’]
布朗语料库
查看语料信息:
from nltk.corpus import brown
brown.categories()
- 1
- 2
输出结果:[‘adventure’, ‘belles_lettres’, ‘editorial’, ‘fiction’, ‘government’, ‘hobbies’, ‘humor’, ‘learned’, ‘lore’, ‘mystery’, ‘news’, ‘religion’, ‘reviews’, ‘romance’, ‘science_fiction’]
比较文体中情态动词的用法:
import nltk
from nltk.corpus import brown
new_texts=brown.words(categories='news')
fdist=nltk.FreqDist([w.lower() for w in new_texts])
modals=['can','could','may','might','must','will']
for m in modals:
print(m + ':',fdist[m])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果:

NLTK条件概率分布函数:
from nltk.corpus import brown
cfd=nltk.ConditionalFreqDist((genre,word) for genre in brown.categories() for word in brown.words(categories=genre))
genres=['news','religion','hobbies','science_fiction','romance','humor']
modals=['can','could','may','might','must','will']
print(cfd.tabulate(condition=genres, samples=modals))
- 1
- 2
- 3
- 4
- 5
输出结果:
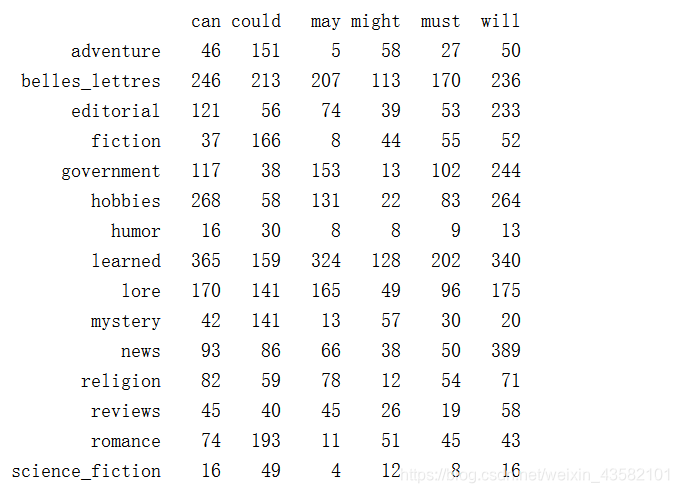
路透社语料库
包括10788个新闻文档,共计130万字,这些文档分90个主题,安装训练集和测试分组,编号‘test/14826’文档属于测试
from nltk.corpus import reuters
print(reuters.fileids()[:500])
- 1
- 2
输出结果
[‘test/14826’, ‘test/14828’, ‘test/14829’, ‘test/14832’, ‘test/14833’, ‘test/14839’, ‘test/14840’, ‘test/14841’, ‘test/14842’, ‘test/14843’, ‘test/14844’, ‘test/14849’, … ‘test/15736’]
查看语料包括的前100个类别:
print(reuters.categories()[:100])
- 1
输出结果:[‘acq’, ‘alum’, ‘barley’, ‘bop’, ‘carcass’, ‘castor-oil’, ‘cocoa’,… ‘zinc’]
查看语料尺寸:
len(reuters.fileids())
- 1
输出:10788
查看语料类别尺寸:
len(reuters.categories())
- 1
查看某个编号的语料下类别尺寸:
reuters.categories('training/9865')
- 1
输出:[‘barley’, ‘corn’, ‘grain’, ‘wheat’]
查看某几个联合编号下语料的类别尺寸:
reuters.categories(['training/9865','training/9880'])
- 1
输出:[‘barley’, ‘corn’, ‘grain’, ‘money-fx’, ‘wheat’]
查看哪些编号的文件属于指定的类别:
reuters.fileids('barley')
- 1
输出:[‘test/15618’, ‘test/15649’, ‘test/15676’, ‘test/15728’, ‘test/15871’, …‘training/9958’]
就职演说语料库
查看语料信息:
from nltk.corpus import inaugural
print(len(inaugural.fileids()))
- 1
- 2
输出:56
print(inaugural.fileids())
- 1
输出: [‘1789-Washington.txt’, ‘1793-Washington.txt’, ‘1797-Adams.txt’,… ‘2009-Obama.txt’]
查看演说语料的年份:
print([fileid[:4] for fileid in inaugural.fileids()])
- 1
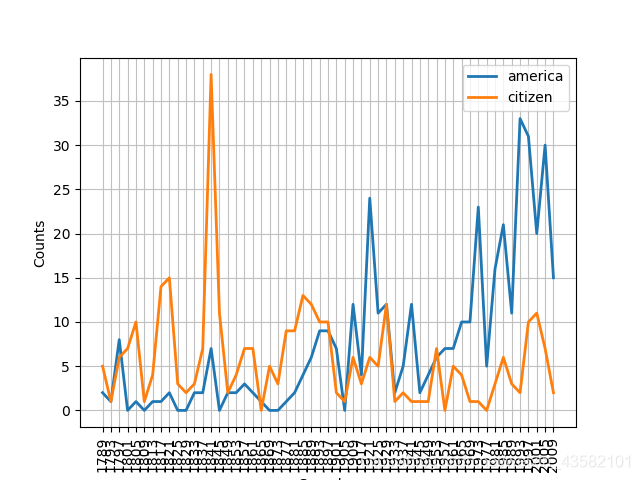
条件概率分布
import nltk
cfd=nltk.ConditionalFreqDist((target,fileid[:4]) for fileid in inaugural.fileids() for w in inaugural.words(fileid) for target in ['america','citizen'] if w.lower().startswith(target))
cfd.plot()
- 1
- 2
- 3
文本语料库常见的几种结构:
孤立的没有结构的文本集;
按文体分类成结构(布朗语料库)
分类会重叠的(路透社语料库)
语料库可以随时间变化的(就职演说语料库)
查找NLTK语料库函数help(nltk.corpus.reader)
`
载入自己的语料库
构建自己语料库
from nltk.corpus import PlaintextCorpusReader
corpus_root=r'D:\lx_dict'
wordlists=PlaintextCorpusReader(corpus_root,'.*')
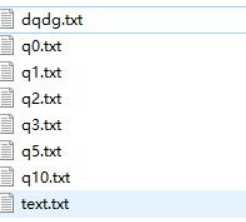
print(wordlists.fileids())
- 1
- 2
- 3
- 4
输出结果:[‘dqdg.txt’, ‘q0.txt’, ‘q1.txt’, ‘q10.txt’, ‘q2.txt’, ‘q3.txt’, ‘q5.txt’, ‘text.txt’]
构建完成自己语料库之后,利用python NLTK内置函数都可以完成对应操作,
但是部分方法NLTK是针对英文语料的,中文语料不通用(典型的就是分词)
文章来源: blog.csdn.net,作者:考古学家lx,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_43582101/article/details/90273388

- 点赞
- 收藏
- 关注作者
评论(0)