Java线程池原理讲解


本文给大家详细的来介绍下线程池的底层原理,希望对大家有所帮助。
一、线程池原理
1. 线程池优点
线程池应该是Web容器中必不可少的组件了,因为每一个请求我们都需要通过对应的线程来处理,所以线程资源是非常重要的,如果管理不好系统的性能会急剧下降。所以重要性不言而喻。来看看它的有点吧。
-
线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用。
-
可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃。
2.线程池的创建
然后我们来看看线程池的创建方式,我们当然可以通过Executors提供的方法来创建,但是这种方式不推荐,实际开发中我们都会结合我们的业务需求来定制化对应的参数。
定制化参数,就是要看看ThreadPoolExecutor的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
- 1
- 2
- 3
- 4
- 5
- 6
参数含义:
- corePoolSize:线程池核心线程数量
- maximumPoolSize:线程池最大线程数量
- keepAliverTime:当活跃线程数大于核心线程数时,空闲的多余线程最大存活时间
- unit:存活时间的单位
- workQueue:存放任务的队列
- handler:超出线程范围和队列容量的任务的处理程序
3.线程池的实现原理
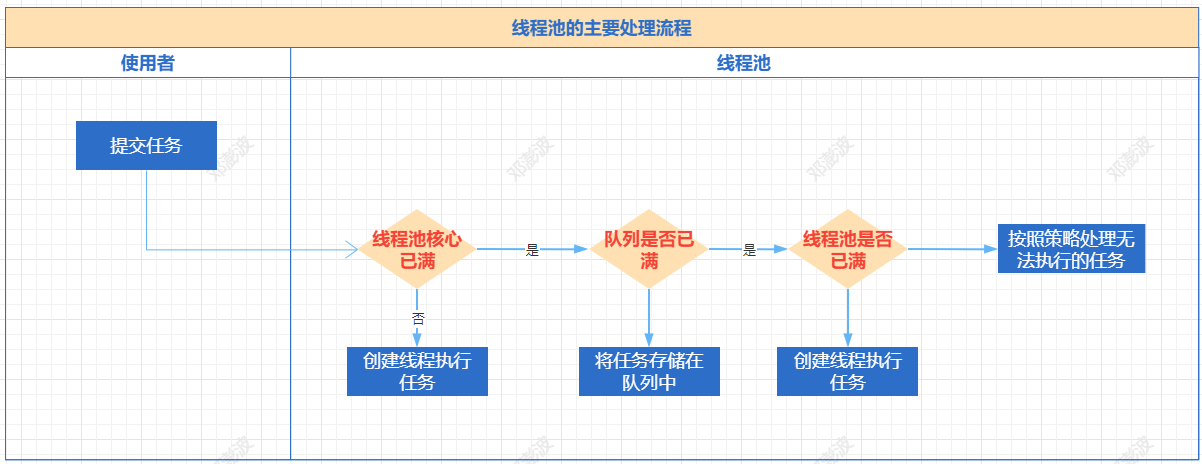
提交一个任务到线程池中,线程池的处理流程如下:
-
判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
-
线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
-
判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
二、线程池源码
然后我们来分析下线程池中的核心方法的源码。通过源码来加深对原理的理解。
1.execute方法
先来看ThreadPoolExecutor的execute()方法。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//由它可以获取到当前有效的线程数和线程池的状态
int c = ctl.get();
// 1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中
if (workerCountOf(c) < corePoolSize) { // 标识行 <------
if (addWorker(command, true)) //在addWorker中创建工作线程执行任务
return;
c = ctl.get();
}
// 2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中
if (isRunning(c) && workQueue.offer(command)) {
//线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
//线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
// 3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常
reject(command);//抛出RejectedExceptionException异常
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上面的标识行即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
2.addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
这里将线程封装成工作线程worker,并放入工作线程组里,worker类的方法run方法:
3.Worker
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1);
//设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
//通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
worker在执行完任务后,还会通过getTask方法循环获取工作队里里的任务来执行。
三、线程池案例
&esmp;我们通过一个具体的例子来加深下理解。
1.创建线程
public class ThreadPoolExample implements Runnable{
@Override
public void run() {
try {
Thread.sleep(200);
}catch (Exception e){
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2. 创建线程池
在主方法中我们来完成测试。
public static void main(String[] args) {
LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(5);
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
5
,10
,60
, TimeUnit.SECONDS
,queue);
for (int i = 0; i < 16; i++) {
threadPool.execute(new Thread(new ThreadPoolExample(),"Thread".concat(i + "")));
System.out.println("线程中活跃的线程数:" + threadPool.getPoolSize());
if(queue.size() > 0){
System.out.println("---->队列中阻塞的线程数:" + queue.size());
}
}
threadPool.shutdown();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.执行结果
执行后的效果如下,抛出了对应的异常信息。
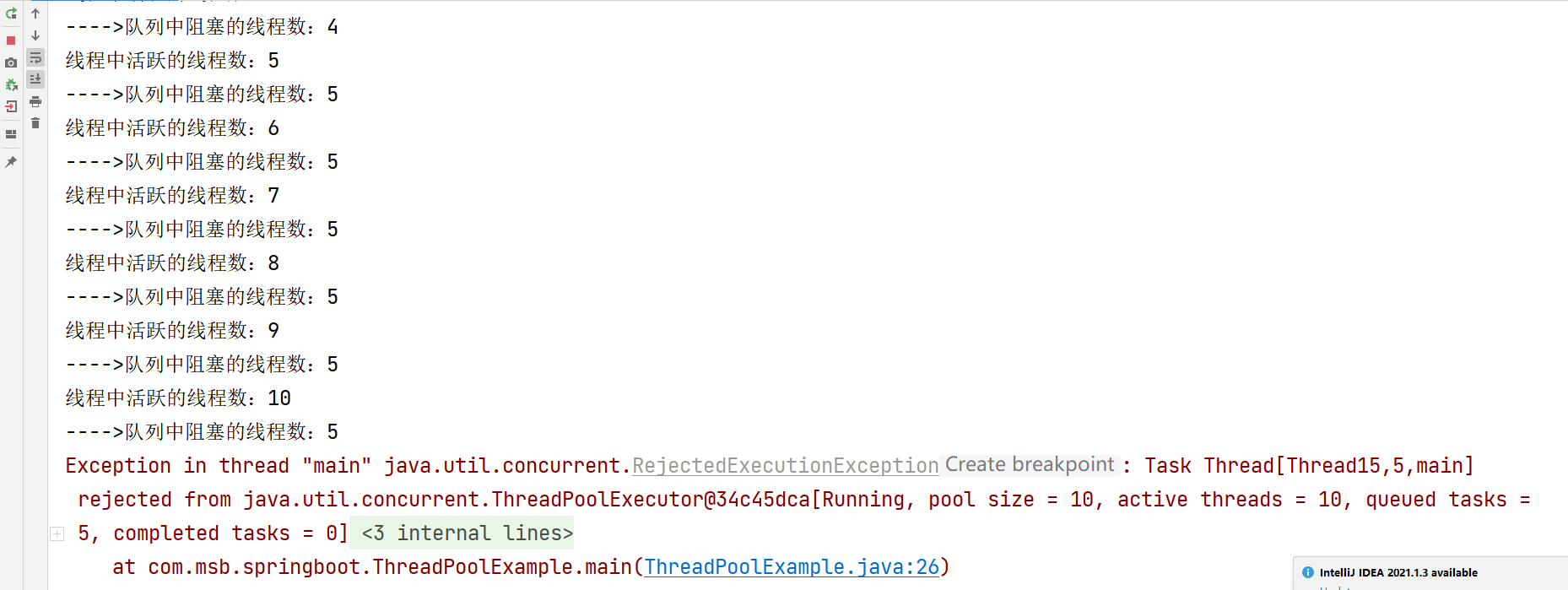
从结果可以观察出:
- 创建的线程池具体配置为:核心线程数量为5个;全部线程数量为10个;工作队列的长度为5。
- 我们通过queue.size()的方法来获取工作队列中的任务数。
- 运行原理:
刚开始都是在创建新的线程,达到核心线程数量5个后,新的任务进来后不再创建新的线程,而是将任务加入工作队列,任务队列到达上线5个后,新的任务又会创建新的普通线程,直到达到线程池最大的线程数量10个,后面的任务则根据配置的饱和策略来处理。我们这里没有具体配置,使用的是默认的配置AbortPolicy:直接抛出异常。
当然,为了达到我需要的效果,上述线程处理的任务都是利用休眠导致线程没有释放!!!
4.饱和策略
当队列和线程池都满了,说明线程池处于饱和状态,那么必须对新提交的任务采用一种特殊的策略来进行处理。这个策略默认配置是AbortPolicy,表示无法处理新的任务而抛出异常。JAVA提供了4中策略:
- AbortPolicy:直接抛出异常
- CallerRunsPolicy:只用调用所在的线程运行任务
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理,丢弃掉。
我们现在用第四种策略来处理上面的程序:
public static void main(String[] args) {
// 阻塞队列
LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(5);
// 饱和策略
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
5
,10
,60
, TimeUnit.SECONDS
,queue
,handler
);
for (int i = 0; i < 1000; i++) {
threadPool.execute(new Thread(new ThreadPoolExample(),"Thread".concat(i + "")));
System.out.println("线程中活跃的线程数:" + threadPool.getPoolSize());
if(queue.size() > 0){
System.out.println("---->队列中阻塞的线程数:" + queue.size());
}
}
threadPool.shutdown();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

这里采用了丢弃策略后,就没有再抛出异常,而是直接丢弃。在某些重要的场景下,可以采用记录日志或者存储到数据库中,而不应该直接丢弃。
// 设置方式一
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue,handler);
// // 设置方式二
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue);
threadPool.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
- 1
- 2
- 3
- 4
- 5
- 6
四、Callable、Future、FutureTash
Callable与Future是在JAVA的后续版本中引入进来的,Callable类似于Runnable接口,实现Callable接口的类与实现Runnable的类都是可以被线程执行的任务。
1.三者之间的关系
- Callable是Runnable封装的异步运算任务。
- Future用来保存Callable异步运算的结果
- FutureTask封装Future的实体类
Callable与Runnbale的区别:
a. Callable定义的方法是call,而Runnable定义的方法是run。
b. call方法有返回值,而run方法是没有返回值的。
c. call方法可以抛出异常,而run方法不能抛出异常。
2.Future
Future表示异步计算的结果,提供了以下方法,主要是判断任务是否完成、中断任务、获取任务执行结果.
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.FutureTask
可取消的异步计算,此类提供了对Future的基本实现,仅在计算完成时才能获取结果,如果计算尚未完成,则阻塞get方法。
public class FutureTask<V> implements RunnableFuture<V>
public interface RunnableFuture<V> extends Runnable, Future<V>
- 1
- 2
FutureTask不仅实现了Future接口,还实现了Runnable接口,所以不仅可以将FutureTask当成一个任务交给Executor来执行,还可以通过Thread来创建一个线程。
4.Callable与FutureTask案例
创建一个Callable接口
public class MyCallableTask implements Callable<Integer>
{
@Override
public Integer call()
throws Exception
{
System.out.println("callable do somothing");
Thread.sleep(5000);
return new Random().nextInt(100);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
创建main方法
public static void main(String[] args) throws Exception
{
Callable<Integer> callable = new MyCallableTask();
FutureTask<Integer> future = new FutureTask<Integer>(callable);
Thread thread = new Thread(future);
thread.start();
Thread.sleep(100);
//尝试取消对此任务的执行
future.cancel(true);
//判断是否在任务正常完成前取消
System.out.println("future is cancel:" + future.isCancelled());
if(!future.isCancelled())
{
System.out.println("future is cancelled");
}
//判断任务是否已完成
System.out.println("future is done:" + future.isDone());
if(!future.isDone())
{
System.out.println("future get=" + future.get());
}
else
{
//任务已完成
System.out.println("task is done");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行结果
callable do somothing
future is cancel:true
future is done:true
task is done
- 1
- 2
- 3
- 4
5.Callable与Future
public class CallableThread implements Callable<String>
{
@Override
public String call()
throws Exception
{
System.out.println("进入Call方法,开始休眠,休眠时间为:" + System.currentTimeMillis());
Thread.sleep(10000);
return "今天停电";
}
public static void main(String[] args) throws Exception
{
ExecutorService es = Executors.newSingleThreadExecutor();
Callable<String> call = new CallableThread();
Future<String> fu = es.submit(call);
es.shutdown();
Thread.sleep(5000);
System.out.println("主线程休眠5秒,当前时间" + System.currentTimeMillis());
String str = fu.get();
System.out.println("Future已拿到数据,str=" + str + ";当前时间为:" + System.currentTimeMillis());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
执行结果
进入Call方法,开始休眠,休眠时间为:1478606602676
主线程休眠5秒,当前时间1478606608676
Future已拿到数据,str=今天停电;当前时间为:1478606612677
- 1
- 2
- 3
这里的future是直接扔到线程池里面去执行的。由于要打印任务的执行结果,所以从执行结果来看,主线程虽然休眠了5s,但是从Call方法执行到拿到任务的结果,这中间的时间差正好是10s,说明get方法会阻塞当前线程直到任务完成。
通过FutureTask也可以达到同样的效果.
public static void main(String[] args) throws Exception
{
ExecutorService es = Executors.newSingleThreadExecutor();
Callable<String> call = new CallableThread();
FutureTask<String> task = new FutureTask<String>(call);
es.submit(task);
es.shutdown();
Thread.sleep(5000);
System.out.println("主线程等待5秒,当前时间为:" + System.currentTimeMillis());
String str = task.get();
System.out.println("Future已拿到数据,str=" + str + ";当前时间为:" + System.currentTimeMillis());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以上的组合可以给我们带来这样的一些变化:
如有一种场景中,方法A返回一个数据需要10s,A方法后面的代码运行需要20s,但是这20s的执行过程中,只有后面10s依赖于方法A执行的结果。如果与以往一样采用同步的方式,势必会有10s的时间被浪费,如果采用前面两种组合,则效率会提高:
-
先把A方法的内容放到Callable实现类的call()方法中
-
在主线程中通过线程池执行A任务
-
执行后面方法中10秒不依赖方法A运行结果的代码
-
获取方法A的运行结果,执行后面方法中10秒依赖方法A运行结果的代码
这样代码执行效率一下子就提高了,程序不必卡在A方法处。
好了线程池的内容就给大家讲解到这里了。
文章来源: dpb-bobokaoya-sm.blog.csdn.net,作者:波波烤鸭,版权归原作者所有,如需转载,请联系作者。
原文链接:dpb-bobokaoya-sm.blog.csdn.net/article/details/122621840

- 点赞
- 收藏
- 关注作者
评论(0)