浅谈缓存与分布式锁

对于一个大型网站而言,每天的访问量是巨大的,尤其遇到某些特定的时间点,比如电商平台的购物节、教育平台开学季。当在某个时间点遇到过量的并发时,往往会压垮服务器导致网站崩溃,因此,网站对于高并发的处理是至关重要的,其中缓存起着举足轻重的作用。对于一些不经常变化,或者热度很高的数据,可以将其存入缓存,此时当用户访问时将直接读取缓存而不查询数据库,从而大大提高了网站的吞吐量。
缓存的使用
首先来搭建一个简单的测试环境,创建一个SpringBoot应用,并编写一个控制器:
@RestController
public class TestController {
@Autowired
private UserService userService;
@GetMapping("/test")
public List<User> test(){
return userService.getUsers();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
访问 http://localhost:8080/test 可以得到所有的用户信息:
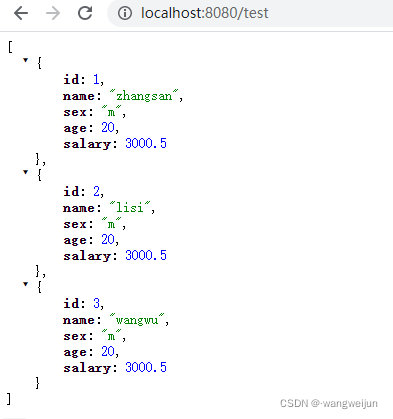
我们使用 jmeter 对该应用进行压力测试,来到官网:http://jmeter.apache.org/download_jmeter.cgi

将zip压缩包下载到本地,然后解压缩,双击执行bin目录下的 jmeter.bat 即可启动jmeter:

这里模拟了1秒内2000次请求的并发,看看应用的吞吐量有多少:

发现吞吐量为421,可以想象当数据表中的数据量非常庞大时,若是所有的请求都需要查询一次数据库,那么效率就会大打折扣,所以,我们可以加入缓存来进行优化:
@RestController
public class TestController {
// 缓存
Map<String, Object> cache = new HashMap<>();
@Autowired
private UserService userService;
@GetMapping("/test")
public List<User> test() {
// 从缓存中获取数据
List<User> users = (List<User>) cache.get("users");
if (StringUtils.isEmpty(users)) {
// 未命名缓存,查询数据库
users = userService.getUsers();
// 将查询得到的数据存入缓存
cache.put("users",users);
}
// 命名缓存,直接返回
return users;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这里使用HashMap简答地模拟了一个缓存,那么接下来这个接口的执行过程如下所示:
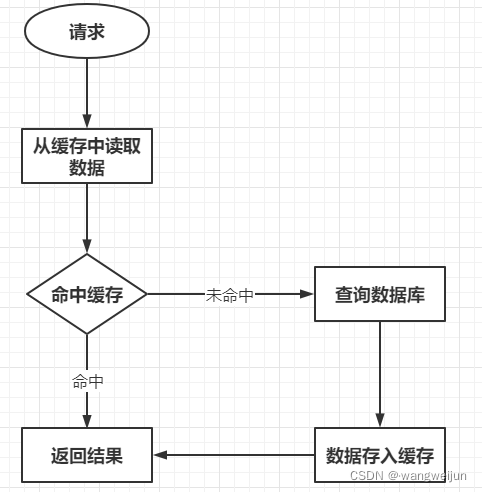
当请求到来时,首先要从缓存中读取数据,若是读取到了数据,则直接返回;若是没有读取到,则查询数据库,并将得到的数据存入缓存,这样下次请求就可以读取到缓存中的数据了。
现在测试一下该应用的吞吐量:

不难发现,吞吐量得到了显著的提升。
本地缓存与分布式缓存
刚才我们使用缓存提升了应用的整体性能,但缓存是被定义在应用内部的,这种缓存称之为 本地缓存。本地缓存对于单机应用确实可以解决问题,但在分布式应用中,一个应用往往会被部署多份以实现高可用:
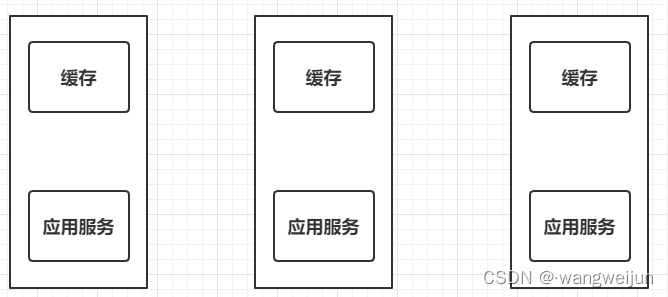
此时每份应用中都会保存一份自己的缓存,当修改数据时,相应地需要修改缓存中的数据,然而因为缓存有多份,这样会导致其它的缓存没有被修改,进而导致数据发生错乱。
由此,我们需要将缓存抽取出去,形成一个独立于所有应用,但又与所有应用有联系的缓存中间件:
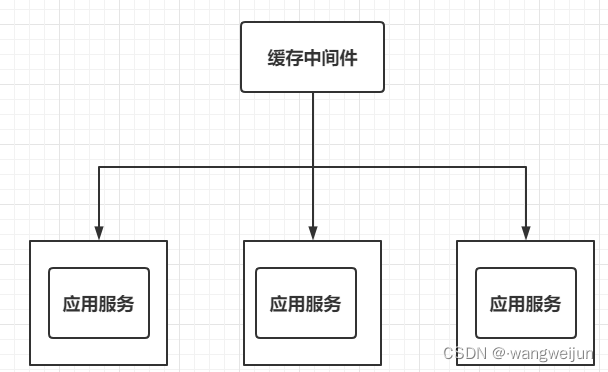
当前较为流行的缓存中间件就是 Redis 了。
SpringBoot整合Redis
接下来改造一下刚才的应用,让其使用Redis缓存,首先下载redis的镜像:
docker pull redis
- 1
创建目录结构:
mkdir -p /mydata/redis/conf
touch /mydata/redis/conf/redis.conf
- 1
- 2
来到/mydata/redis/conf目录下,修改redis.conf文件:
appendonly yes # 持久化配置
- 1
创建redis的实例并启动:
docker run -p 6379:6379 --name redis\
-v /mydata/redis/data:/data\
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf\
-d redis redis-server /etc/redis/redis.conf
- 1
- 2
- 3
- 4
配置一下使redis随着Docker的启动而启动:
docker update redis --restart=always
- 1
到这里Redis就准备好了,然后在项目中引入redis的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 1
- 2
- 3
- 4
在application.yml中配置Redis:
spring:
redis:
host: 192.168.66.10
- 1
- 2
- 3
修改控制器代码:
@RestController
public class TestController {
@Autowired
private UserService userService;
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/test")
public String test() {
// 从Redis中获取数据
String usersJson = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(usersJson)) {
// 未命中缓存,查询数据库
List<User> users = userService.getUsers();
// 将查询结果转成json字符串
usersJson = JSON.toJSONString(users);
// 放入缓存
redisTemplate.opsForValue().set("users",usersJson);
}
// 返回结果
return usersJson;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
缓存中存在的一些问题
使用了Redis缓存并不是说就高枕无忧了,它仍然有很多的问题需要解决,以下是缓存中间件经常面临的三个问题:
- 缓存穿透
- 缓存雪崩
- 缓存击穿
缓存穿透
缓存穿透指的是查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
因为缓存是帮助数据库分担压力的,但若是让某些人知道了系统中哪些数据是一定不存在的,那么它就可以利用这个数据不停地发送大量请求,从而击垮我们的系统。
解决方案是不管这个数据是否存在,都对其进行存储,比如某个请求需要的数据是不存在的,那么仍然将这个数据的key进行存储,这样下次请求时就可以从缓存中获取,但若是每次请求数据的key均不同,那么Redis中就会存储大量无用的key,所以应该为这些key设置一个指定的过期时间,到期自动删除即可。
缓存雪崩
缓存雪崩是指缓存中数据大批量地同时过期,而查询数据量巨大,引起数据库压力过大甚至宕机。
解决的办法是在数据原有的过期时间上增加一个随机值,这样可以使数据之间的过期时间不一致,也就不会出现数据大批量同时过期的情况。
缓存击穿
缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
解决的办法是加锁,当某个热点key过期时,大量的请求会进行资源竞争,当某个请求成功执行时,其它请求就需要等待,此时该请求执行完成后就会将数据放入缓存,这样别的请求就可以直接从缓存中获取数据了。
解决缓存击穿问题
对于缓存穿透和缓存雪崩,我们都能够非常轻松地解决,然而缓存击穿问题需要加锁来解决,我们就来探究一下如何加锁解决缓存击穿问题。
@GetMapping("/test")
public String test() {
String usersJson = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(usersJson)) {
synchronized (this){
// 再次确认缓存中是否有数据
String json = redisTemplate.opsForValue().get("users");
if(StringUtils.isEmpty(json)){
List<User> users = userService.getUsers();
System.out.println("查询了数据库......");
usersJson = JSON.toJSONString(users);
}else{
usersJson = json;
}
redisTemplate.opsForValue().set("users",usersJson);
}
}
return usersJson;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
首先仍然需要从缓存中获取数据,若未命中缓存,则执行同步代码块,在同步代码块中又进行了缓存数据的确认。这是因为当大量的请求同时进入了最外层的if语句中,此时某个请求开始执行,并成功查询了数据库,但是在该请求将数据放入Redis之后,如果不再次进行判断,那么这些请求仍然还是会去查询数据库,其执行原理如下所示:
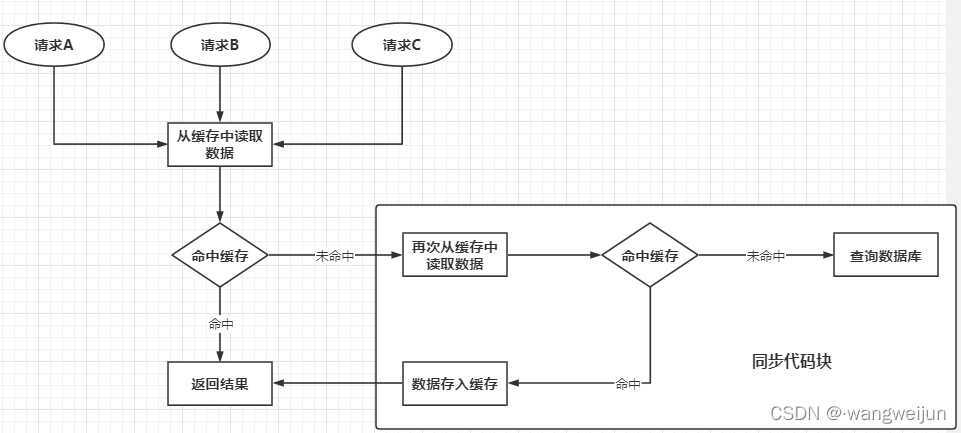
使用jmeter模拟1秒2000次的并发后,结果如下:
查询了数据库......
- 1
控制台只输出了一个 查询了数据库...... ,说明2000次的请求中确实只有一次查询了数据库,但随之而来的是性能的急剧下降:

这种情况对于单机的应用是没有问题的,因为SpringBoot中默认Bean是单例的,通过this锁住代码块没有任何问题,但在分布式应用中,一个应用往往被部署多份,this就无法锁住每个应用的请求了,此时就需要使用 分布式锁 。
分布式锁
和缓存中间件一样,我们可以将锁抽取到外面,独立于所有的服务,但又与每个服务联系起来,如下所示:
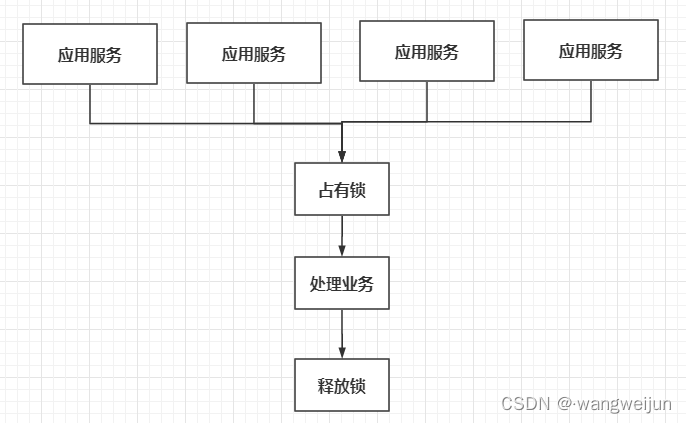
每个服务想要加锁,都需要去一个公共的地方进行占用,这样就保证了即使在分布式的环境下,每个服务的锁仍然是同一把,这个公共的地方可以有很多种选择,可以使用Redis实现分布式锁。
Redis中有一个指令非常适合实现分布式锁,它就是 setnx ,来看看官网是如何介绍它的:

只有当key不存在的时候,setnx才会将值设置进去,否则什么也不做,那么对于每个服务,我们都可以让其执行 setnx lock 1 ,因为这一操作是原子性的,即使有百万的并发,也只能有一个请求设置成功,其它请求都会因为key已经存在而设置失败。对于设置成功的,就表明占用锁成功了;而设置失败的,占用锁也就失败了。
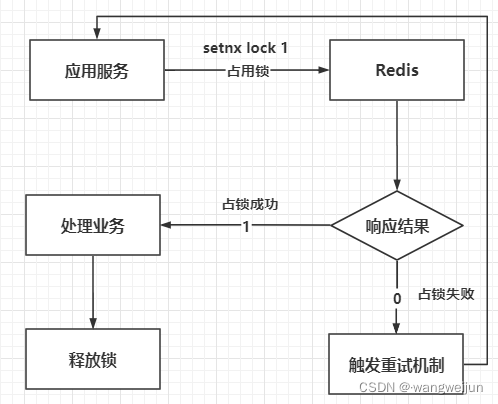
代码如下:
@RestController
public class TestController {
@Autowired
private UserService userService;
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/test")
public String test() throws InterruptedException {
String usersJson = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(usersJson)) {
usersJson = getUsersJson();
}
return usersJson;
}
public String getUsersJson() throws InterruptedException {
String usersJson = "";
// 抢占分布式锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1");
if (lock) {
// 占锁成功
// 再次确认缓存中是否有数据
String json = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(json)) {
List<User> users = userService.getUsers();
System.out.println("查询了数据库......");
usersJson = JSON.toJSONString(users);
} else {
usersJson = json;
}
redisTemplate.opsForValue().set("users", usersJson);
// 释放锁
redisTemplate.delete("lock");
} else {
// 占锁失败,触发重试机制
Thread.sleep(200);
// 重复调用自身
getUsersJson();
}
return usersJson;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
当然了,这里还是有很大问题的,如果在释放锁之前,程序就出现了异常,导致代码终止,锁没有被及时释放,就会出现死锁问题,解决方案是在占用锁的同时设置锁的过期时间,这样即使程序没有及时释放锁,Redis也会等锁过期后自动将其删除。
即使设置了锁的过期时间,仍然会有新的问题出现,当业务的执行时间大于了锁的过期时间时,业务此时并没有处理完成,但锁却被Redis删除了,这样别的请求就能够重新占用锁,并执行业务方法,解决方案是让每个请求占用的锁都是独有的,某个请求不能随意地去删除其它请求的锁,代码如下:
public String getUsersJson() throws InterruptedException {
String usersJson = "";
// 抢占分布式锁
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300, TimeUnit.SECONDS);
if (lock) {
// 占锁成功
// 再次确认缓存中是否有数据
String json = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(json)) {
List<User> users = userService.getUsers();
System.out.println("查询了数据库......");
usersJson = JSON.toJSONString(users);
} else {
usersJson = json;
}
redisTemplate.opsForValue().set("users", usersJson);
// 判断当前锁是否为自己的锁
String lockVal = redisTemplate.opsForValue().get("lock");
if (uuid.equals(lockVal)) {
// 如果是自己的锁,才能释放锁
redisTemplate.delete("lock");
}
} else {
// 占锁失败,触发重试机制
Thread.sleep(200);
getUsersJson();
}
return usersJson;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
仔细想想,这里仍然是有问题存在的,因为在释放锁时,Java程序会向Redis发送指令,Redis执行完成后并将结果返回给Java程序,在网络传输过程中都会消耗时间。假设此时Java程序向Redis获取lock的值,Redis成功将值返回,但在返回过程中锁过期了,此时别的请求将可以占有锁,这时候Java程序接收到了lock的值,比较发现是自己的锁,于是执行删除操作,但此时Redis中的锁已经是别的请求的锁了,这样还是出现了某个请求删除了其它请求的锁的问题。
为此,Redis官网也给出了解决方案:

通过执行这样的一个Lua脚本即可解决刚才的问题,代码如下:
public String getUsersJson() throws InterruptedException {
String usersJson = "";
// 抢占分布式锁
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300, TimeUnit.SECONDS);
if (lock) {
// 占锁成功
// 再次确认缓存中是否有数据
String json = redisTemplate.opsForValue().get("users");
if (StringUtils.isEmpty(json)) {
List<User> users = userService.getUsers();
System.out.println("查询了数据库......");
usersJson = JSON.toJSONString(users);
} else {
usersJson = json;
}
redisTemplate.opsForValue().set("users", usersJson);
String luaScript = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
// 执行脚本
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(luaScript, Long.class);
List<String> keyList = Arrays.asList("lock");
redisTemplate.execute(redisScript, keyList, uuid);
} else {
// 占锁失败,触发重试机制
Thread.sleep(200);
getUsersJson();
}
return usersJson;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格,我们可以使用它来轻松实现分布式锁。
首先引入Redisson的依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
编写配置类:
@Configuration
public class MyRedissonConfig {
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.66.10:6379");
return Redisson.create(config);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编写一个控制器来体验一下Redisson:
@RestController
public class TestController {
@Autowired
private RedissonClient redissonClient;
@GetMapping("/test")
public String test() {
// 占用锁
RLock lock = redissonClient.getLock("my_lock");
// 加锁
lock.lock();
try {
// 模拟业务处理
Thread.sleep(1000 * 10);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
}
return "test";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
就简简单单地声明一下加锁和释放锁操作即可,前面的所有问题都将迎刃而解,Redisson会自动为锁设置过期时间,并且提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭之前,不断地延长锁的过期时间,如果该锁的线程还没有处理完业务的话(默认情况下看门狗的续期时间为30秒)。
也可以指定锁的过期时间:
lock.lock(15, TimeUnit.SECONDS);
- 1
在加锁时设置好时间即可。
当设置了锁的过期时间为15秒,若是业务执行耗时不止15秒,还会出现Redis自动删除了锁,别的请求抢占锁的情况吗?其实这种情况还是会有的,所以我们应该避免设置过小的过期时间,一定要让锁的过期时间大于业务的执行时间。
使用Redisson也能轻松实现读写锁,比如:
@RestController
public class TestController {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
@GetMapping("/write")
public String write() {
RReadWriteLock wrLock = redissonClient.getReadWriteLock("wr_lock");
// 获取写锁
RLock wLock = wrLock.writeLock();
// 加锁
wLock.lock();
String uuid = "";
try {
uuid = UUID.randomUUID().toString();
Thread.sleep(20 * 1000);
// 存入redis
redisTemplate.opsForValue().set("uuid", uuid);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放锁
wLock.unlock();
}
return uuid;
}
@GetMapping("/read")
public String read() {
RReadWriteLock wrLock = redissonClient.getReadWriteLock("wr_lock");
// 获取读锁
RLock rLock = wrLock.readLock();
// 加锁
rLock.lock();
String uuid = "";
try {
// 读取uuid
uuid = redisTemplate.opsForValue().get("uuid");
} finally {
// 释放锁
rLock.unlock();
}
return uuid;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
只要读写锁使用的是同一把锁,那么在写操作时,读操作就必须等待,而且写锁是一个互斥锁,当某个线程正在进行写操作时,其它线程就必须排队等待;读写是一个共享锁,所有线程都可以直接进行读操作,这样便能够保证每次读取到的都是最新数据。
缓存一致性
使用缓存虽然提高了系统的吞吐量,但也随之带来了一个问题,当缓存中有了数据之后,都会从缓存中直接取出数据,但若是此时数据库中的数据被修改了,用户读取到的仍然还是缓存中的数据,这就出现了数据不一致的问题,对于这一情况,一般有两种解决方案:
- 双写模式:在修改数据库的同时也去修改一下缓存
- 失效模式:在修改数据库之后直接将缓存删除
双写模式会导致脏数据问题,如下所示:
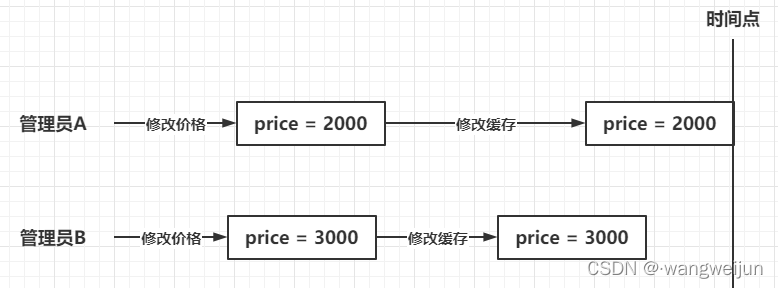
管理员A、B在修改一个商品的价格,管理员A先提交,管理员B后提交,按理应该是管理员B的写缓存操作生效,但由于网络波动等未知情况,导致管理员A的写缓存操作先生效后,而管理员B的写缓存操作后生效,最后缓存中的数据就变为了2000,这样就导致了脏数据的产生,但这种脏数据只是暂时的,因为数据库中的数据是正确的,所以等缓存过期后,重新查询数据库,缓存中的数据也就正常了。
问题转化为如何保证双写模式下的数据一致性,解决办法就是加锁,对修改数据库与修改缓存的操作加锁,使其成为一个原子操作。
失效模式也是会导致脏数据产生的,所以对于经常修改的数据,应该直接查询数据库,而不是走缓存。
综上所述,一般的解决方案为:对所有的缓存数据都需要设置过期时间,这样可以使缓存在过期时触发一次数据库查询从而更新缓存;读写数据的时候,使用Redisson添加读写锁,保证写操作的原子性。
文章来源: blizzawang.blog.csdn.net,作者:·wangweijun,版权归原作者所有,如需转载,请联系作者。
原文链接:blizzawang.blog.csdn.net/article/details/119600791

- 点赞
- 收藏
- 关注作者
评论(0)