
转载:https://www.cnblogs.com/krainbow/p/4261906.html
昨日,公司php调用redis报错:read error on connection 2015-01-29 23:59:050.13330000,redis存放的是用户session。
在网上查询,大家说法都比较一致,说是php.ini文件中的一个配置项导致:
default_socket_timeout = 60
由于redis扩展也是基于php 的socket方式实现,因此该参数值同样会起作用。
解决方法是:
1、直接修改php.ini,将其设置为我们想要的值(这个不推荐)
2、在我们的脚本中通过以下方式设置,这样就比较灵活,不对其他脚本产生影响
ini_set('default_socket_timeout', -1); //不超时
但是,一看,修改的两个参数,一个是php的全局参数,一个是redis的超时操作,都应该按照实际情况来修改,而且,设置超长超时时间或者不超时都是不合理的;
继续检查redis发现,/usr/local/redis_16379/src/redis-cli -p 16379 info(服务器配置的redis端口为16379,分配内存为8000M)
used_memory_human:7.49G,占用内存已经7.49G
db10:keys=53090286,键值5000多万
竟然是键值占满了内存,检查php的调用代码,发现php竟然没有设置redis的键值过期时间,修改php代码,对键值设置过期时间
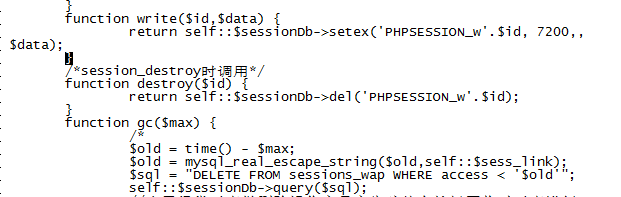
设置完之后,发现之前的键值因为没有设置过期时间,程序不会自动删除,于是用脚本删除主redis上对应的session,
/usr/local/redis_16379/src/redis-cli -p 16379 -n 10 keys "PHPSESSION_wc*" | xargs /usr/local/redis_16379/src/redis-cli -p 16379 -n 10 del
将大部分过期数据删除掉,删除一定数量的数据之后,报错消失,redis连接正常。
但是,发现redis主从,在这样删除之后,从数据竟然没有同步,主的数据和从数据差距有400多万不一致,也没有再发现bgsave操作,查看从日志Trying a partial resynchronization,发现因为过滤keys占用太多资源,造成服务器负载飙升,slave断开与主机的连接,需要从积压空间中找回断开期间的数据更新记录。但是因为删除数据太多,断开的时间足够长,master 拒绝 slave 的部分同步请求,从而 slave 只能进行全同步。
至此,在slave上对数据进行全量同步,数据恢复正常,业务正常。
需要注意几点:
1.redis数据,正常情况下,设置过期时间,否则可能出现,存储键值过多,占用完了预设内存,导致新的键值无法存储,调用redis失败的;
2.超时时间必须根据实际业务来设置;
3.如果slave一直连接不上master,可能需要进行全量同步。

评论(0)