【MySQL】优化器执行流程

【摘要】
1.首先就是用户发送一条SQL通过客户端接收之后,交由解析器解析SQL创建对应的解析树之后 2.然后优化获取对应的数据表的信息-结构 3.获取表中对应的数据表,首先就会去缓存中读取索引的如果没有就会通...
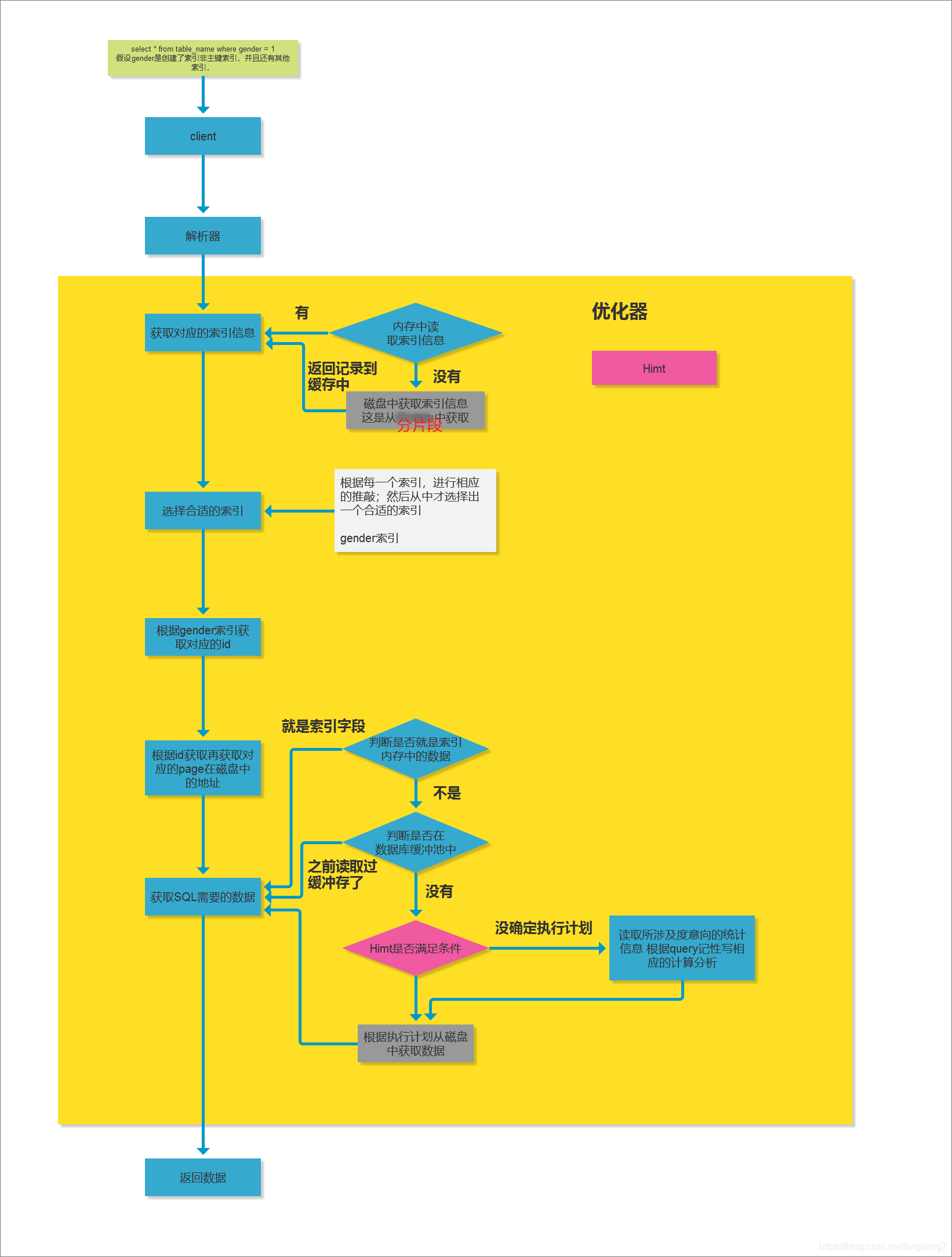
1.首先就是用户发送一条SQL通过客户端接收之后,交由解析器解析SQL创建对应的解析树之后
2.然后优化获取对应的数据表的信息-结构
3.获取表中对应的数据表,首先就会去缓存中读取索引的如果没有就会通过IO读取在磁盘中记录索引的信息并返回
4.选择合适的索引:因为一个表会有很多的索引,MySQL会对于每一个索引进行相应的算法推敲然后再做相应的删选留下最为合适的索引,所以如果说索引的数量多的话会给查询优化器带来一定的负担。
5.因为在当前的索引为二级索引所以这个时候就会根据二级索引的btree获取到对应的id
6.读取到所对应的id之后再通过回表查询
7.根据主键索引获取到对应的数据的页在磁盘中的位置
8.在获取数据之前会判断索引缓存的数据是否满足查询,然后再判断数据库缓冲池以及读缓冲区中是否有缓冲,如果有就返回。没有就会去执行对应的执行计划,从磁盘中获取数据信息
文章来源: blog.csdn.net,作者:咔咔-,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/fangkang7/article/details/99443549

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)