别再用offset和limit分页了

终于要对MySQL优化下手了,本文将对分页进行优化说明,希望可以得到一个合适你的方案
前言
分页这个话题已经是老生常谈了,但是有多少小伙伴一边是既希望优化的自己的系统,另一边在项目上还是保持自己独有的个性。

优化这件事是需要自己主动行动起来的,自己搞测试数据,只有在测试的路上才会发现更多你未知的事情。
本文咔咔也会针对分页优化这个话题进行解读。
一、表结构
这个数据库结构就是咔咔目前线上项目的表,只不过咔咔将字段名改了而已,还有将时间字段取消了。
数据库结构如下
CREATE TABLE `tp_statistics` (
`ss_id` int(11) NOT NULL AUTO_INCREMENT,
`ss_field1` decimal(11,2) NOT NULL DEFAULT '0.00',
`ss_field2` decimal(11,2) NOT NULL DEFAULT '0.00',
`ss_field3` decimal(11,2) NOT NULL DEFAULT '0.00',
PRIMARY KEY (`ss_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3499994 DEFAULT CHARSET=utf8 COLLATE=utf8mb4_general_ci ROW_FORMAT=COMPACT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
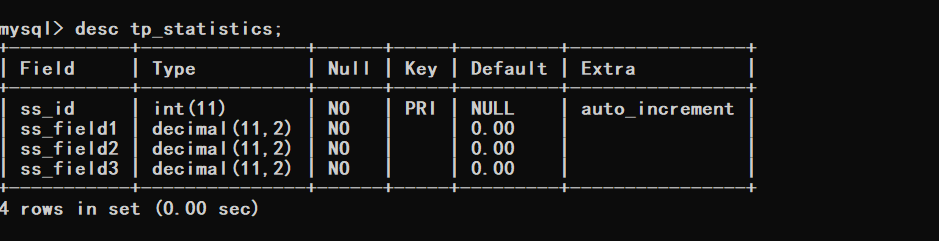
根据以上信息可以看到目前表里边的数据有350万记录,接下来就针对这350W条记录进行查询优化。
二、初探查询效率
先来写一个查询的SQL语句,先看一下查询耗费的时间。
根据下图可以看到查询时间基本忽略不计,但是要注意的是limit的偏移量值。
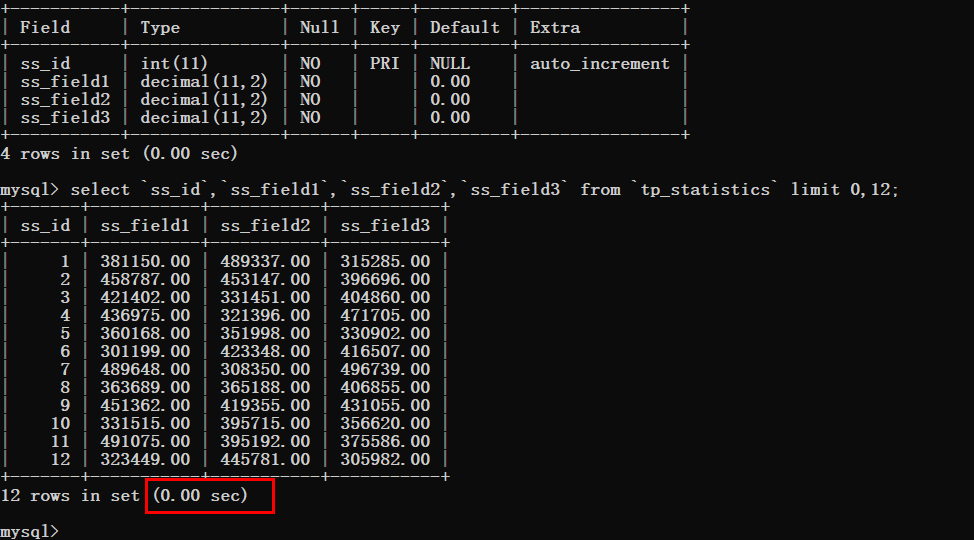
于是我们要一步一步的加大这个偏移量然后进行测试,先将偏移量改为10000
可以看到查询时间还是非常理想的。
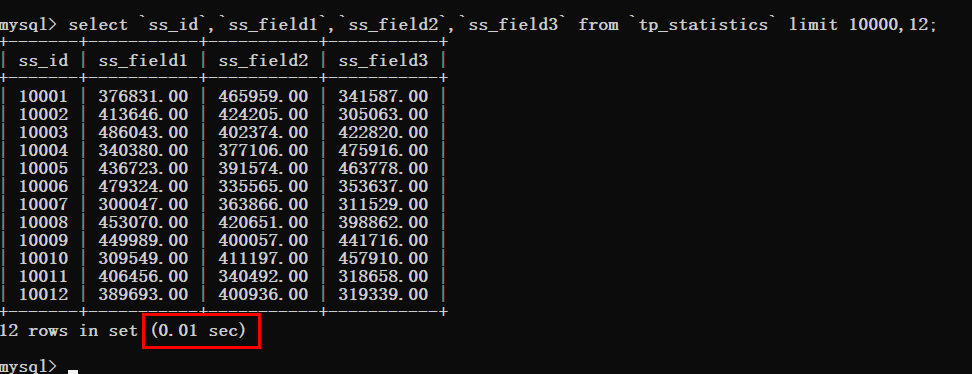
为了节省时间咔咔将这个偏移量的值直接调整到340W。
这个时候就可以看到非常明显的变化了,查询时间猛增到了0.79s。
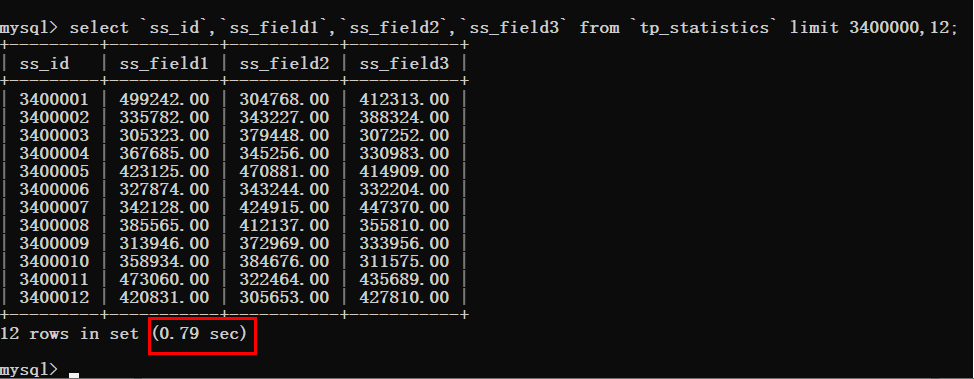
出现了这样的情况,那肯定就需要进行优化了,拿起键盘就是干。
三、分析查询耗时的原因
提到分析SQL语句,必备的知识点就是explain,如果对这个工具不会使用的可以去看看MySQL的基础部分。
根据下图可以看到三条查询语句都进行了表扫描。
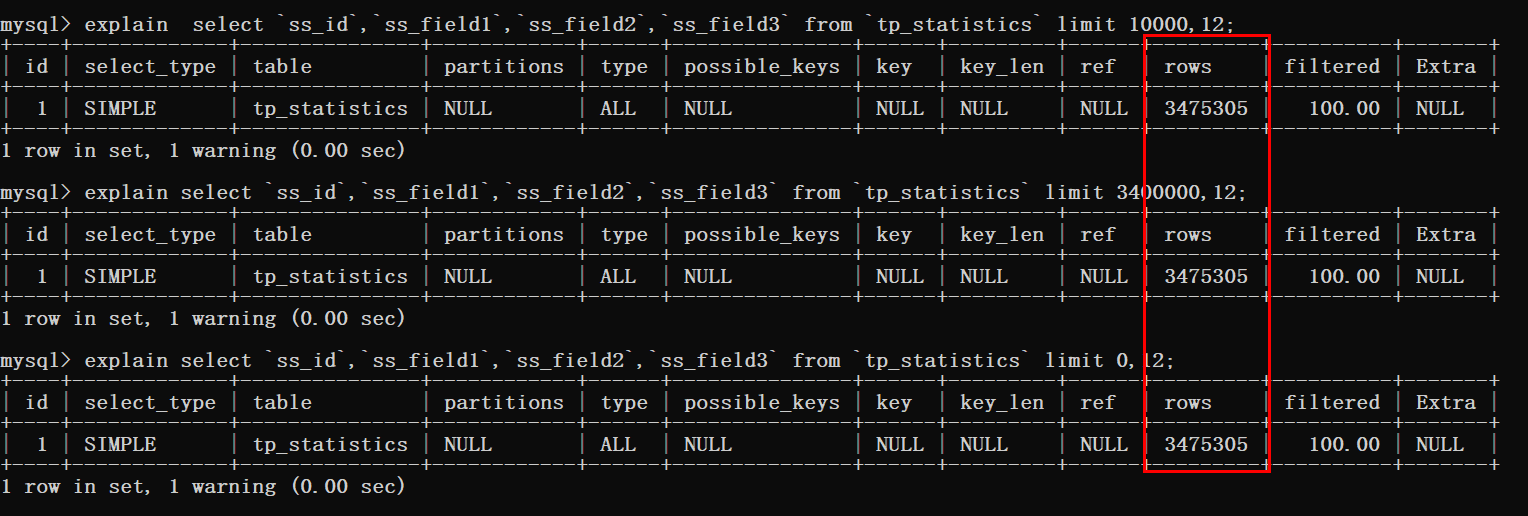
都知道只要有关于分页就必存在排序,那么加一个排序再来看一下查询效率。
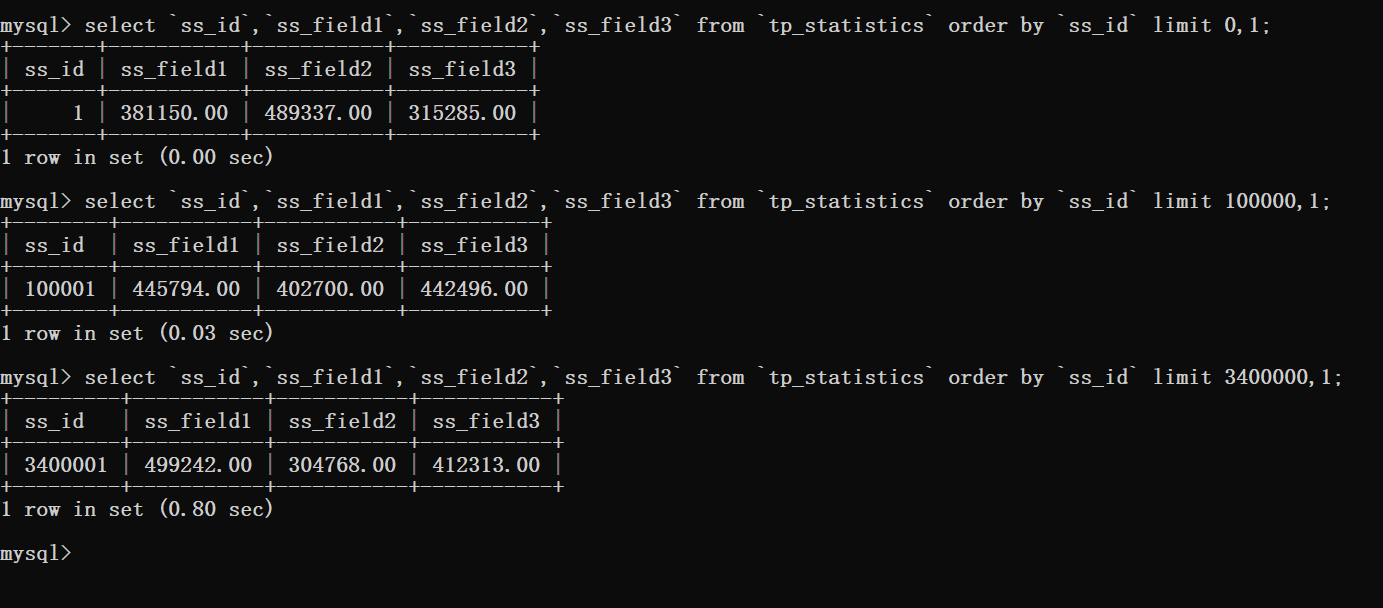
然后在进行对排序的语句进行分析查看。
通过这里看到当使用了排序时数据库扫描的行数就是偏移量加上需要查询的数量。
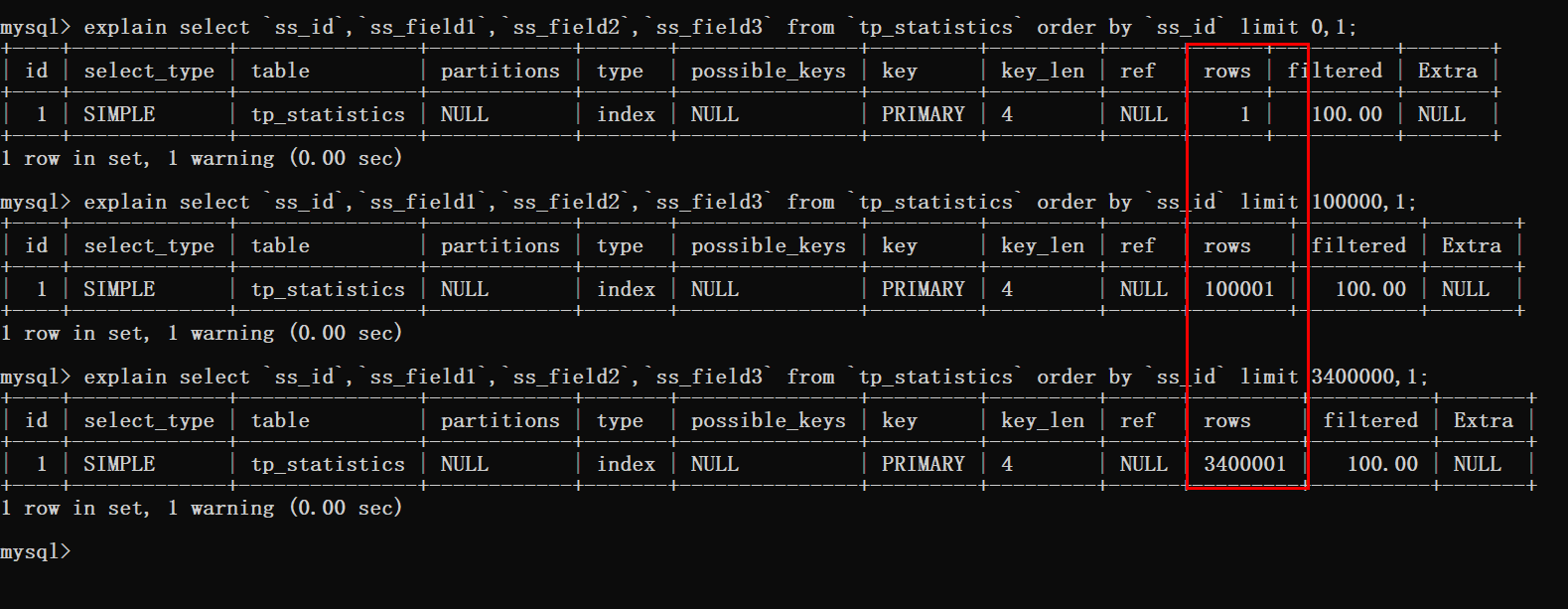
此时就可以知道的是,在偏移量非常大的时候,就像上图案例中的limit 3400000,12这样的查询。
此时MySQL就需要查询3400012行数据,然后在返回最后12条数据。
前边查询的340W数据都将被抛弃,这样的执行结果可不是我们想要的。
咔咔之前看到相关文章说是解决这个问题的方案,要么直接限制分页的数量,要么就优化当偏移量非常大的时候的性能。
如果你都把本文看到了这里,那怎么会让你失望,肯定是优化大偏移量的性能问题。
四、优化
既然提到了优化,无非就那么俩点,加索引,使用其它的方案来代替这个方案。
咔咔提供的这条数据表结构信息,完全可以理解为就是图书馆的借阅记录,字段的什么都不要去关心就可以了。
对于排序来说,在这种场景下是不会给时间加排序的,而是给主键加排序,并且由于添加测试数据的原因将时间字段给取消了。
接下来使用覆盖索引加inner join的方式来进行优化。
select ss_id,ss_field1,ss_field2,ss_field3 from tp_statistics inner join ( select ss_id from tp_statistics order by ss_id limit 3000000,10) b using (ss_id);
- 1
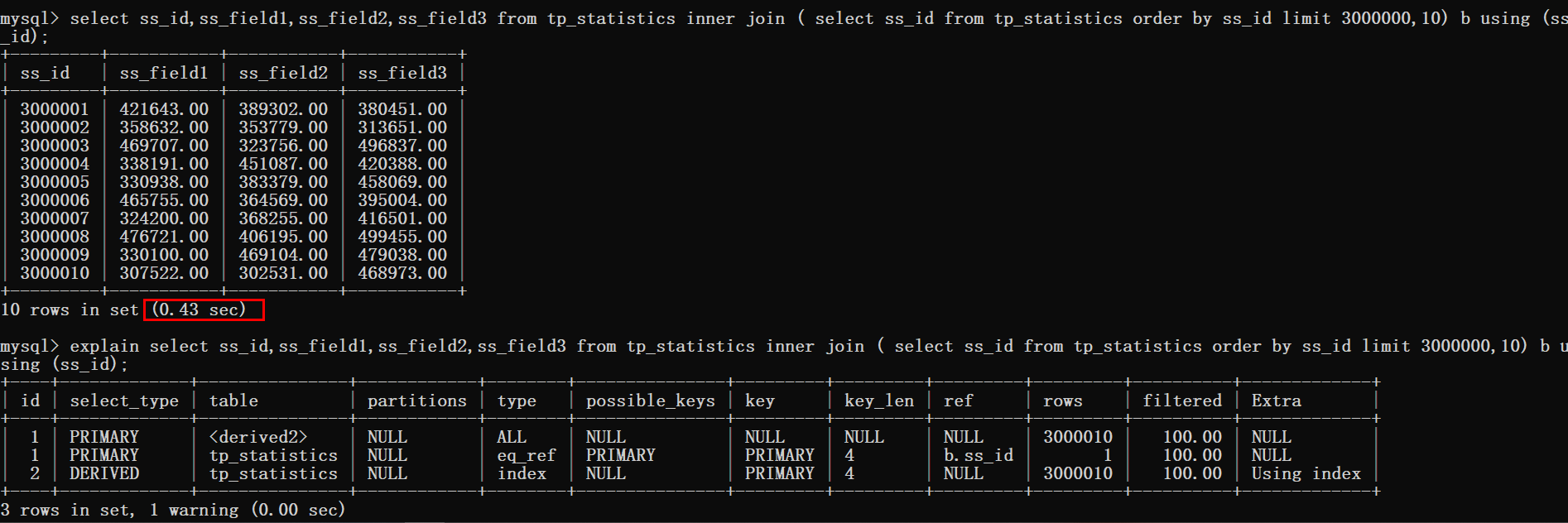
从上图可以看到查询时间从0.8s优化到了0.4s,但是这样的效果还是不尽人意。
于是只能更换一下思路再进行优化。

既然优化最大偏移量这条路有点坎坷,能不能从其它方面进行入手。
估计有很多同学已经知道咔咔将要抛出什么话题了。
没错,就是使用where > id 然后使用limit。
先来测试一波结果,在写具体实现方案。
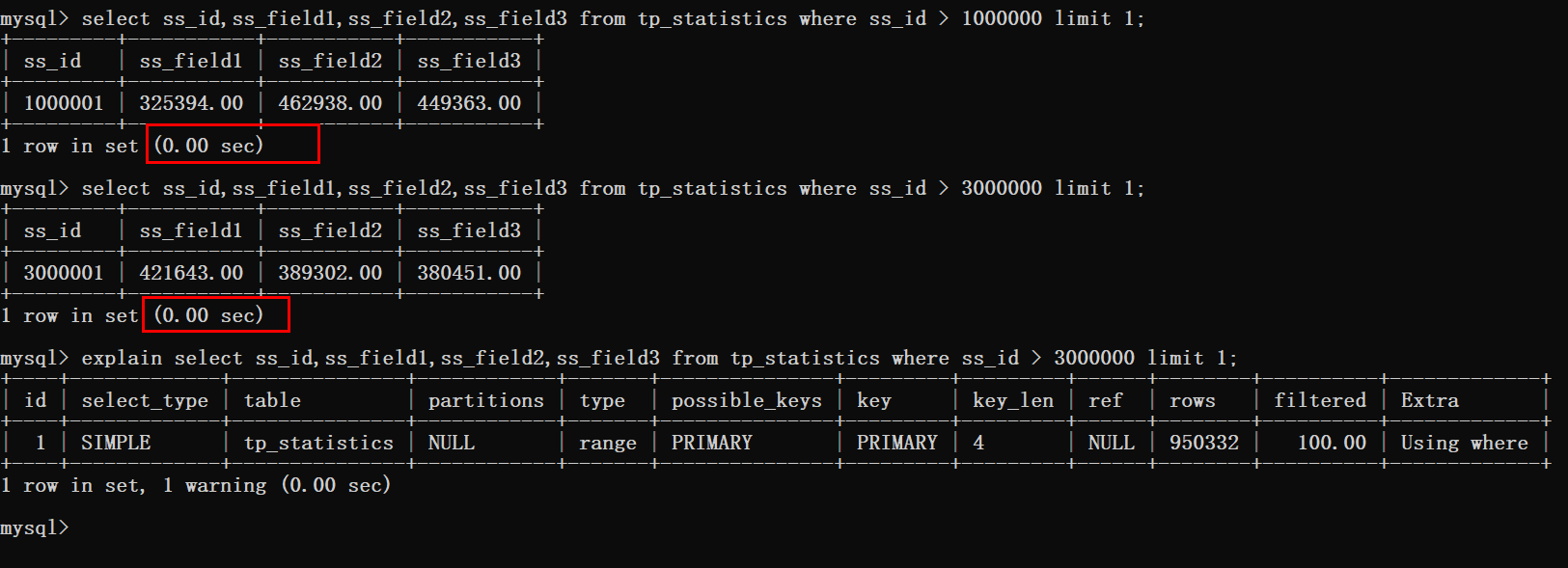
根据上图可以看到这种方式是十分可行的,分页在300W条数据以后的查询时间也基本忽略不计。
那么这种方案要怎么实现呢!
五、方案落地
其实这个方案真的很简单,只需要简单的转换一下思路即可。

当客户端第一次获取数据的时候就正常传递offset、limit俩个参数。
首次返回的数据就使用客户端传递过来的offset、limit进行获取。
当第一次的数据返回成功后。
客户端第二次拉取数据时这个时候参数就发生改变了,就不能再是offset、limit了。
此时应该传递的参数就是第一次获取的数据最后一条数据的id。
此时的参数就为last_id、limit。
后台获取到last_id后就可以在sql语句中使用where条件 < last_id
咔咔这里给的情况是数据在倒叙的情况下,如果正序就是大于last_id即可。
接下来咔咔使用一个案例给大家直接明了的说明。
实战案例
如下就是将要实战演示的案例,例如首次使用page、limit获取到了数据。
返回结果的最后一条数据的id就是3499984
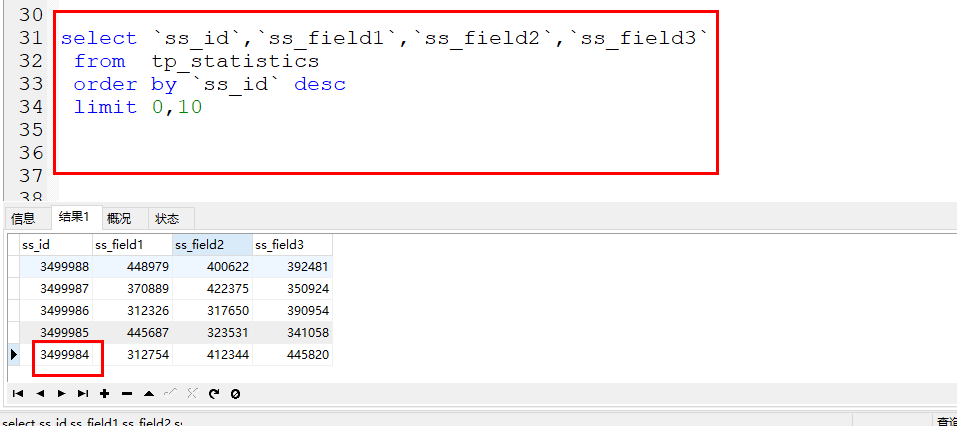
此时如果在获取第二条记录就不是使用offset、limit了,就是传递last_id和limit了。
如下图
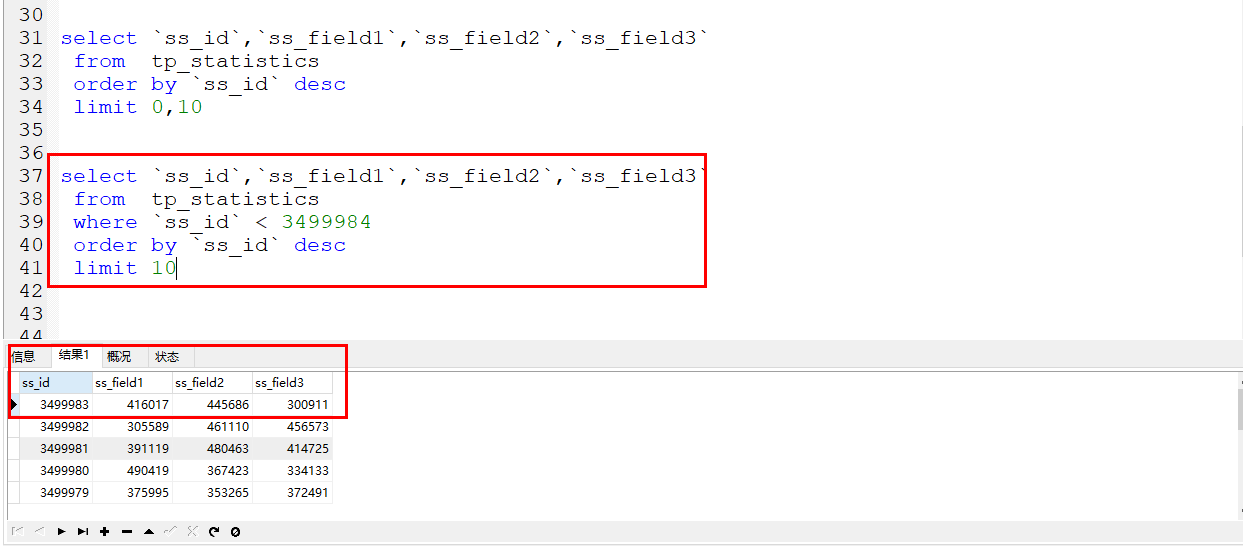
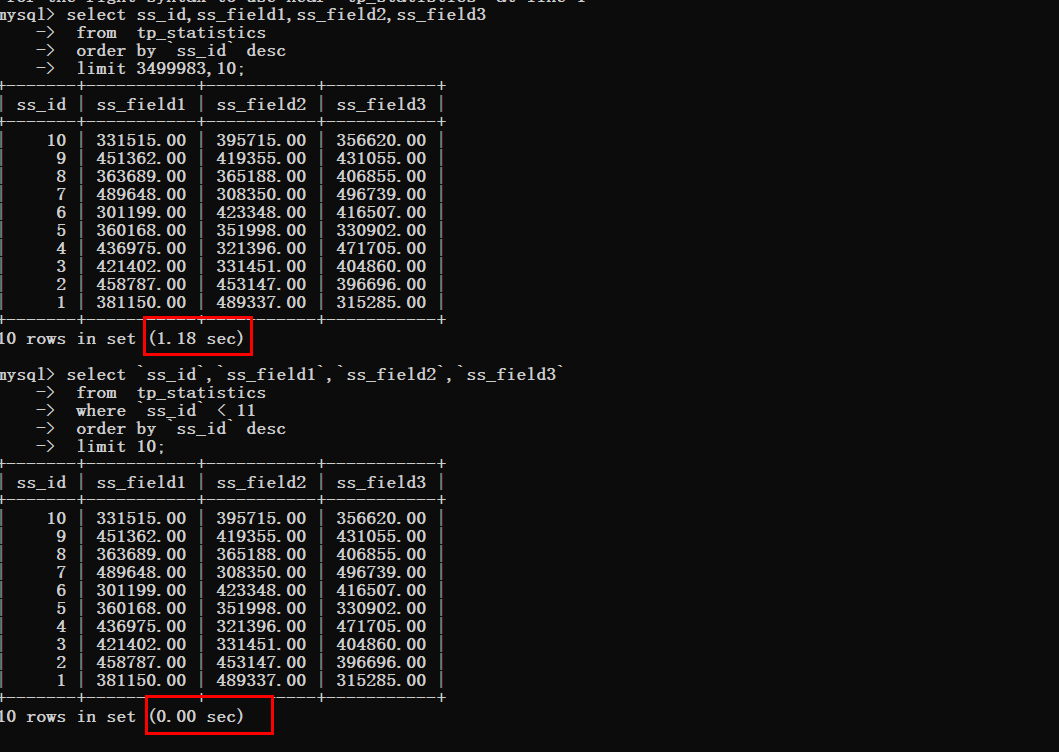
此时就是使用的where条件来进行直接过滤数据,条件就是id小于上次数据的最后一条id即可。
时间对比
假设现在要获取最后一条数据
没有优化之前
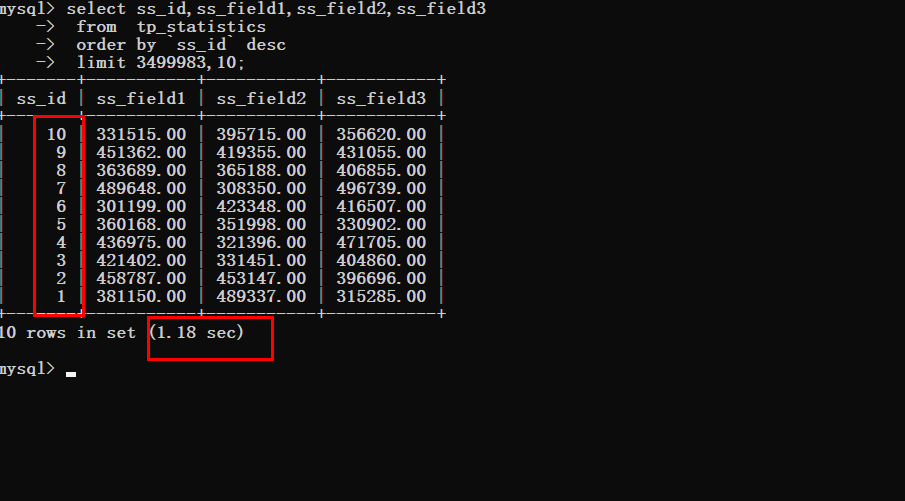
优化之后可以明显的看到查询时间的变化
六、总结
关于limit优化简单几句话概述一下。
- 数据量大的时候不能使用offset、limit来进行分页,因为offset越大,查询时间越久。
- 当然不能说所有的分页都不可以,如果你的数据就那么几千、几万条,那就很无所谓,随便使用。
- 落地方案就是咔咔上边的方案,首次使用offset、limit获取数据,第二次获取数据使用where条件到第一次数据最后一条id即可。
坚持学习、坚持写博、坚持分享是咔咔从业以来一直所秉持的信念。希望在偌大互联网中咔咔的文章能带给你一丝丝帮助。我是咔咔,下期见。
文章来源: blog.csdn.net,作者:咔咔-,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/fangkang7/article/details/112549163

- 点赞
- 收藏
- 关注作者
评论(0)