python爬虫:爬取网站视频

【摘要】
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
1
2
3
4
5...
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib,re,requests
import sys
reload (sys)
sys.setdefaultencoding( 'utf-8' )
url_name = [] #url name
def get():
#获取源码
hd = { "User-Agent" : "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" }
url = 'http://www.budejie.com/video/'
html = requests.get(url,headers = hd).text
url_content = re. compile (r '(<div class="j-r-list-c">.*?</div>.*?</div>)' ,re.S) #编译
url_contents = re.findall(url_content,html) #匹配
for i in url_contents:
#匹配视频
url_reg = r 'data-mp4="(.*?)"' #视频地址
url_items = re.findall(url_reg,i)
#print url_items
if url_items: #判断视频是否存在
name_reg = re. compile (r '<a href="/detail-.{8}?.html">(.*?)</a>' ,re.S)
name_items = re.findall(name_reg,i)
#print name_items[0]
for i,k in zip (name_items,url_items):
url_name.append([i,k])
print i,k
for i in url_name: #i[1]=url i[0]=name
urllib.urlretrieve(i[ 1 ], 'video\\%s.mp4' % (i[ 0 ].decode( 'utf-8' )))
if __name__ = = "__main__" :
get()
|
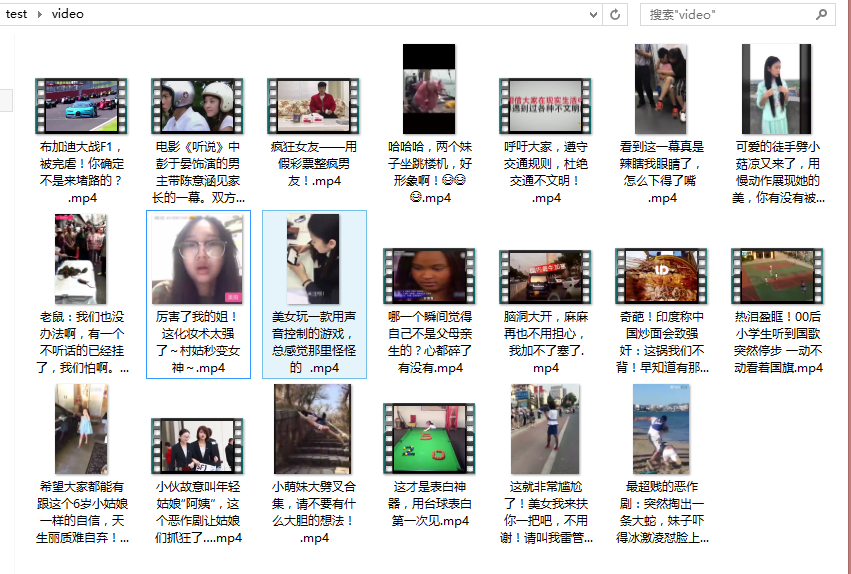
在 py 文件下新建一个 video 文件夹,执行后结果如下:
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
文章来源: blog.csdn.net,作者:lxw1844912514,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/lxw1844912514/article/details/100028957

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)