详细讲解mysql 主从复制原理

简介: 什么是主从复制,如何实现读写分离,看这篇你就懂了!
思维导图

前言
在很多项目,特别是互联网项目,在使用MySQL时都会采用主从复制、读写分离的架构。
为什么要采用主从复制读写分离的架构?如何实现?有什么缺点?让我们带着这些问题开始这段学习之旅吧!
为什么使用主从复制、读写分离
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
主从复制的原理
①当Master节点进行insert、update、delete操作时,会按顺序写入到binlog中。
②salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。
③当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。
④I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log。
⑤SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。

如何实现主从复制
我这里用三台虚拟机(Linux)演示,IP分别是104(Master),106(Slave),107(Slave)。
预期的效果是一主二从,如下图所示:

Master配置
使用命令行进入mysql:
mysql -u root -p
接着输入root用户的密码(密码忘记的话就网上查一下重置密码吧~),然后创建用户:
-
//192.168.0.106是slave从机的IP
-
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.0.106' identified by 'Java@1234';
-
//192.168.0.107是slave从机的IP
-
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.0.107' identified by 'Java@1234';
-
//刷新系统权限表的配置
-
FLUSH PRIVILEGES;
创建的这两个用户在配置slave从机时要用到。
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置:
-
# 开启binlog
-
log-bin=mysql-bin
-
server-id=104
-
# 需要同步的数据库,如果不配置则同步全部数据库
-
binlog-do-db=test_db
-
# binlog日志保留的天数,清除超过10天的日志
-
# 防止日志文件过大,导致磁盘空间不足
-
expire-logs-days=10
配置完成后,重启mysql:
service mysql restart
可以通过命令行show master status\G;查看当前binlog日志的信息(后面有用):
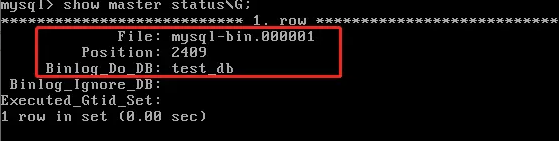
Slave配置
Slave配置相对简单一点。从机肯定也是一台MySQL服务器,所以和Master一样,找到/etc/my.cnf配置文件,增加以下配置:
-
# 不要和其他mysql服务id重复即可
-
server-id=106
接着使用命令行登录到mysql服务器:
mysql -u root -p
然后输入密码登录进去。
进入到mysql后,再输入以下命令:
-
CHANGE MASTER TO
-
MASTER_HOST='192.168.0.104',//主机IP
-
MASTER_USER='root',//之前创建的用户账号
-
MASTER_PASSWORD='Java@1234',//之前创建的用户密码
-
MASTER_LOG_FILE='mysql-bin.000001',//master主机的binlog日志名称
-
MASTER_LOG_POS=862,//binlog日志偏移量
-
master_port=3306;//端口
还没完,设置完之后需要启动:
-
# 启动slave服务
-
start slave;
启动完之后怎么校验是否启动成功呢?使用以下命令:
show slave status\G;
可以看到如下信息(摘取部分关键信息):
-
*************************** 1. row ***************************
-
Slave_IO_State: Waiting for master to send event
-
Master_Host: 192.168.0.104
-
Master_User: root
-
Master_Port: 3306
-
Connect_Retry: 60
-
Master_Log_File: mysql-bin.000001
-
Read_Master_Log_Pos: 619
-
Relay_Log_File: mysqld-relay-bin.000001
-
Relay_Log_Pos: 782
-
Relay_Master_Log_File: mysql-bin.000001 //binlog日志文件名称
-
Slave_IO_Running: Yes //Slave_IO线程、SQL线程都在运行
-
Slave_SQL_Running: Yes
-
Master_Server_Id: 104 //master主机的服务id
-
Master_UUID: 0ab6b3a6-e21d-11ea-aaa3-080027f8d623
-
Master_Info_File: /var/lib/mysql/master.info
-
SQL_Delay: 0
-
SQL_Remaining_Delay: NULL
-
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
-
Master_Retry_Count: 86400
-
Auto_Position: 0
另一台slave从机配置一样,不再赘述。
测试主从复制
在master主机执行sql:
-
CREATE TABLE `tb_commodity_info` (
-
`id` varchar(32) NOT NULL,
-
`commodity_name` varchar(512) DEFAULT NULL COMMENT '商品名称',
-
`commodity_price` varchar(36) DEFAULT '0' COMMENT '商品价格',
-
`number` int(10) DEFAULT '0' COMMENT '商品数量',
-
`description` varchar(2048) DEFAULT '' COMMENT '商品描述',
-
PRIMARY KEY (`id`)
-
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
接着我们可以看到两台slave从机同步也创建了商品信息表:
主从复制就完成了!
读写分离
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
实现的方式有很多,以前我公司是采用AOP的方式,通过方法名判断,方法名中有get、select、query开头的则连接slave,其他的则连接master数据库。
但是通过AOP的方式实现起来代码有点繁琐,有没有什么现成的框架呢,答案是有的。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy两部分组成。
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
读写分离就可以使用ShardingSphere-JDBC实现。

下面演示一下SpringBoot+Mybatis+Mybatis-plus+druid+ShardingSphere-JDBC代码实现。
项目配置
版本说明:
-
SpringBoot:2.0.1.RELEASE
-
druid:1.1.22
-
mybatis-spring-boot-starter:1.3.2
-
mybatis-plus-boot-starter:3.0.7
-
sharding-jdbc-spring-boot-starter:4.1.1
添加sharding-jdbc的maven配置:
-
<dependency>
-
<groupId>org.apache.shardingsphere</groupId>
-
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
-
<version>4.1.1</version>
-
</dependency>
然后在application.yml添加配置:
-
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
-
spring:
-
shardingsphere:
-
datasource:
-
names: master,slave0,slave1
-
master:
-
type: com.alibaba.druid.pool.DruidDataSource
-
driver-class-name: com.mysql.jdbc.Driver
-
url: jdbc:mysql://192.168.0.108:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
-
username: yehongzhi
-
password: YHZ@1234
-
slave0:
-
type: com.alibaba.druid.pool.DruidDataSource
-
driver-class-name: com.mysql.jdbc.Driver
-
url: jdbc:mysql://192.168.0.109:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
-
username: yehongzhi
-
password: YHZ@1234
-
slave1:
-
type: com.alibaba.druid.pool.DruidDataSource
-
driver-class-name: com.mysql.jdbc.Driver
-
url: jdbc:mysql://192.168.0.110:3306/test_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
-
username: yehongzhi
-
password: YHZ@1234
-
props:
-
sql.show: true
-
masterslave:
-
load-balance-algorithm-type: round_robin
-
sharding:
-
master-slave-rules:
-
master:
-
master-data-source-name: master
-
slave-data-source-names: slave0,slave1
sharding.master-slave-rules是标明主库和从库,一定不要写错,否则写入数据到从库,就会导致无法同步。
load-balance-algorithm-type是路由策略,round_robin表示轮询策略。
启动项目,可以看到以下信息,代表配置成功:

编写Controller接口:
-
/**
-
* 添加商品
-
*
-
* @param commodityName 商品名称
-
* @param commodityPrice 商品价格
-
* @param description 商品价格
-
* @param number 商品数量
-
* @return boolean 是否添加成功
-
* @author java技术爱好者
-
*/
-
@PostMapping("/insert")
-
public boolean insertCommodityInfo(@RequestParam(name = "commodityName") String commodityName,
-
@RequestParam(name = "commodityPrice") String commodityPrice,
-
@RequestParam(name = "description") String description,
-
@RequestParam(name = "number") Integer number) throws Exception {
-
return commodityInfoService.insertCommodityInfo(commodityName, commodityPrice, description, number);
-
}
准备就绪,开始测试!
测试
打开POSTMAN,添加商品:

控制台可以看到如下信息:

查询数据的话则通过slave进行:


就是这么简单!
缺点
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- 从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
可能有人会问,有没有事务问题呢?
实际上这个框架已经想到了,我们看回之前的那个截图,有一句话是这样的:

三,常见问题
(1)相同的mysql server uuid, 导致slave_io_running:no
Slave两个关键进程:
mysql replication 中slave机器上有两个关键的进程,死一个都不行,
一个是slave_sql_running,负责自己的slave mysql进程。
一个是Slave_IO_Running,负责与主机的io通信.
故障案例:主从同步报错Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDS

场景一:因为数据量非常,大概有1.4T,需要在原先master1-slave1的情况下再创建一个库slave2,并且挂在slave1下,即master1-slave1-slave2的结构。为了方便,当时停掉从库salve1,show master status记录状态,开启log_slave_updates,并且关闭salve1,然后将这个从库的data文件夹直接copy到新的从库,结果在创建slave2和slave1的主从关系时报错
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
原因分析:mysql 5.6的复制引入了uuid的概念,各个复制结构中的server_uuid得保证不一样,但是查看到直接copy data文件夹后server_uuid是相同的,
show variables like '%server_uuid%';


果然,主从库使用了相同的server_uuid;
解决方法:
找到data文件夹下的auto.cnf文件,修改里面的uuid值,保证各个db的uuid不一样,重启db即可

结果:
1.主库端查看从库的uuid
show slave hosts;

2.从库端查看server_uuid

在这里主要是看:
Slave_IO_Running=Yes
Slave_SQL_Running=Yes
如果都是Yes,则说明配置成功.
场景二:创建主从关系时copy了同样的my.cnf文件,报错
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids;
原因分析:
和server_uuid类似,servier_id也得保证不一样
解决方法:
找到my.cnf配置文件中的server_id,修改从库的server_id保证和复制结构中的其他db不一样,重启db即可
场景三:
mysql 5.6下因操作两次drop table导致主从断开 1051 error
解决方法及其步骤
1.在slave端stop slave
2.修改参数,让其跳过报错event,
set global sql_slave_skip_counter = 1 ;
3.start slave
4.show slave status \G;来查看是否正常,通过观察Seconds_Behind_Master的日志落后是否慢慢缩小,判断master-slave是否正常
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Seconds_Behind_Master: 0
参数说明:
而set global sql_slave_skip_counter=N的意思,即为在start slave时,从当前位置起,跳过N个event。每跳过一个event.但是注意1个event可能会包含多个执行语句,要看数据库的负载及其性能情况而定,一般操作前,可能会去binlog或者
relaylog去查看跳过点的语句具体是什么,从而来决定是否进行操作操作来保证master-slave正常进行复制
场景四:mysql同步故障
Last_Error: Error 'Unknown table 'test'' on query. Default database: 'test'. Query: 'drop table test'
原因:
1.可能在slave上进行了写操作 (导致slave跟master数据不一致)
2.也可能是slave机器重起后,事务回滚造成的.
3.数据同步初始化时,未成功,就是说主库上的某些表没有初始化,删除的时候,导致slave出现'Unknown table 'test'' on query. Default database: 'test'. Query: 'drop table test'报错
解决办法1:(手动同步数据)
1.首先停掉Slave服务
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
2.到主服务器上查看主机状态:
记录File和Position对应的值。
mysql> show master status;
3.初始化同步数据 (可以尝试直接跳过该步骤,执行下面的步骤,如果可以成功,则不需要执行这步。这步属于重新开始做一次slave的数据初始化了)
master:
[root@mysqltest1 mysql]# mysqldump -uroot -p123456 test > /tmp/test.sql
4.到slave服务器上执行手动同步:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.9.145', MASTER_PORT=3306, MASTER_USER='replication', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000009', MASTER_LOG_POS=106;
5.再次查看slave状态发现:
mysql> show slave status \G;
解决办法2:
(确保master与slave的数据时一致的,不然会出现数据不同步的情况)
mysql> slave stop;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> slave start;
四.MySQL 内部Logrotate的机制
Binary Log rotate机制:
Rotate:每一条binary log写入完成后,都会判断当前文件是否超过 max_binlog_size,如果超过则自动生成一个binlog file
Delete:expire-logs-days 只在 实例启动时 和 flush logs 时判断,如果文件访问时间早于设定值,则purge file
Relay Log rotate 机制:
Rotate:每从Master fetch一个events后,判断当前文件是否超过 max_relay_log_size 如果超过则自动生成一个新的relay-log-file
Delete:purge-relay-log 在SQL Thread每执行完一个events时判断,如果该relay-log 已经不再需要则自动删除
因此建议当slave不再使用时,一定要通过reset slave来取消relaylog,不然即使重启mysql,问题还是一样存在。
五.常用命令操作
查看日志一些命令
1, show master status\G;
在这里主要是看log-bin的文件是否相同。
show slave status\G;
在这里主要是看:
Slave_IO_Running=Yes
Slave_SQL_Running=Yes
如果都是Yes,则说明配置成功.
2,在master上输入show processlist\G;
mysql> SHOW PROCESSLIST;
出现Command: Binlog Dump,则说明配置成功.
3.维护管理命令:
stop slave #停止同步
start slave #开始同步,从日志终止的位置开始更新。
SET SQL_LOG_BIN=0|1 #主机端运行,需要super权限,用来开停日志,随意开停,会造成主机从机数据不一致,造成错误
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=n # 客户端运行,用来跳过几个事件,只有当同步进程出现错误而停止的时候才可以执行。
4.重启
RESET MASTER #主机端运行,清除所有的日志,这条命令就是原来的FLUSH MASTER
RESET SLAVE #从机运行,清除日志同步位置标志,并重新生成master.info
#虽然重新生成了master.info,但是并不起用,最好,将从机的mysql进程重启一下
5.
SHOW MASTER STATUS #主机运行,看日志导出信息
SHOW SLAVE HOSTS #主机运行,看连入的从机的情况。
SHOW SLAVE STATUS (slave)
SHOW MASTER LOGS (master)
参考:https://blog.csdn.net/cug_jiang126com/article/details/46846031
MySQL数据同步,出现Slave_SQL_Running:no和slave_io_running:no问题的解决方法
文章来源: blog.csdn.net,作者:lxw1844912514,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/lxw1844912514/article/details/116119330

- 点赞
- 收藏
- 关注作者
评论(0)