php面试知识点总结

1.PHP 优先级
-
$a = 0;
-
$a = (2 > 2) ? 2 : 3 ? $a++ : --$a;
-
//解析:( false ? 2 : 3) ? $a++ : --$a
-
// 3 ? $a++ : --$a
-
var_dump($a);//0
-
echo "<br>";
-
-
$a = (2 > 2) ? 2 : 3 ? ++$a : --$a;
-
var_dump($a);//1
-
-
echo "<br>";
-
$a = true ? 0 : true ? 1 : 2;// (true ? 0 : true) ? 1 : 2 = 2 左结合
-
var_dump($a);//0
-
-
-
$a = 1;
-
$b = 2;
-
$a = $b += 3; // $a = ($b += 3) -> $a = 5, $b = 5 右结合
-
-
$a = 1;
-
echo $a + $a++; //3
优先级详情:https://www.php.net/manual/zh/language.operators.precedence.php
2.从mysql 数据库中随机取出一条记录
方法1:
select * from 表名 order by rand( ) limit 1; //此处的1就是取出数据的条数
但这样取数据网上有人说效率非常差的,那么要如何改进呢
搜索Google,网上基本上都是查询max(id) * rand()来随机获取数据。
方法2:
-
SELECT *
-
FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * (SELECT MAX(id) FROM `table`)) AS id) AS t2
-
WHERE t1.id >= t2.id
-
ORDER BY t1.id ASC LIMIT 5;
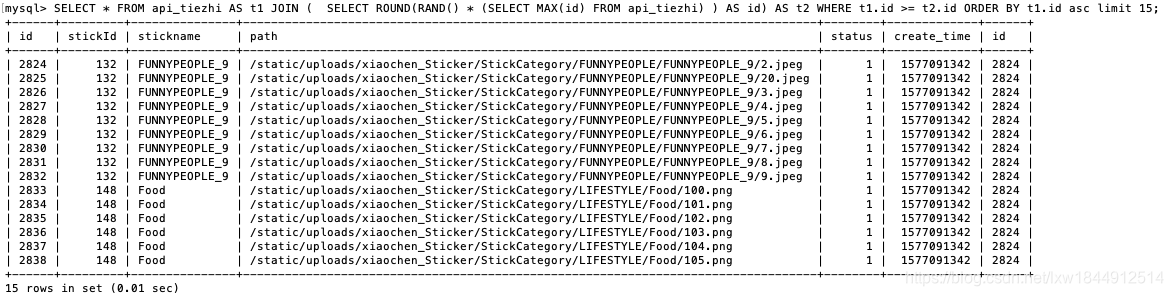
但是这样获得的是5条连续的记录。解决办法只能是每次查询一条,查询5次,但这个又不能满足我的要求了,我要一次找几条
方法3: 高效写法
SELECT * FROM user WHERE userId >= ((SELECT MAX(userId) FROM user )-(SELECT MIN(userId) FROM user )) * RAND() + (SELECT MIN(userId) FROM user ) LIMIT 5
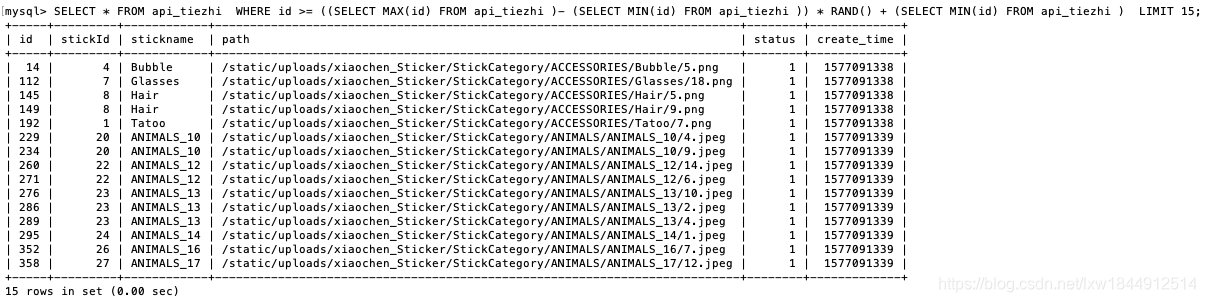
个人感觉:方法3和方法2区别不大.
3.用php写一段代码,实现不适用第3个变量,变换$a,$b的值,$a,$b初始值自己定
方法1:简洁易懂 ,没得说,顶上
-
-
list($a, $b) = array($b, $a);
方法二:两个变量必须是数字
-
$a=5; $b=7;
-
$a = $a + $b;
-
$b = $a - $b;
-
$a = $a - $b;
-
-
echo $a,$b;//7 5
方法3:(这个就比较有限制,必须用一个两个字符串都都不能出现的字符做为分隔符)
-
$a = $b.','.$a ;
-
$a = explode(',', $a);
-
$b = $a[1];
-
$a = $a[0];
方法4:可能存在编码问题
-
$a = $a . $b;
-
$b = strlen( $b );
-
$b = substr( $a, 0, (strlen($a) - $b ) );
-
$a = substr( $a, strlen($b) );
方法5:两个变量的长度必须一样
-
$a = $a^$b;
-
$b = $b^$a;
-
$a = $a^$b;
4.char/varchar 区别,谁的存储速度快,为何?
一.数据存储开销
1.char(n) 是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会再后面补空值。当你输入的字符大于指定的数时,它会截取超出的字符。
在程序中,会返回给你8位,后面的用空格补上;
在数据库中,char(8),占用16个字节(1个字符=2个字节);
2.varchar(n) 是长度为 n 个字节的可变长度且非 Unicode 的字符数据。n必须是一个介于1和 8000之间的数值。存储大小为输入数据的字节的实际长度,而不是 n 个字节。所输入的数据字符长度可以为零。
二.插入数据
1.char列的NULL值占用存储空间。
varchar列的NULL值不占用存储空间。
插入同样数量的NULL值,varchar列的插入效率明显高出char列。
插入不为null的数据时,无论插入数据涉及的列是否建立索引,varchar列的插入效率也是明显高出char列。
三.更新数据
如果更新的列上未建立索引,则char的效率低于varchar,但效率差异不大。
如果更新的列上建立索引,则char的效率低于varchar,并且效率差异很大。
四.修改结构
无论增加或删除的列的类型是char还是varchar,操作都能较快的完成,而且效率上没有什么差异。
对于增加列的宽度而言,char与varchar有非常明显的效率差异,varchar列基本上不花费时间,而修改char列需要花费很长的时间。
五.数据检索
无论是否通过索引,varchar类型的数据检索略优于char的扫描。
那实际开发中,我们使用哪种呢?
当确定字符串为定长、数据变更频繁、数据检索需求少时,使用char;
当不确定字符串长度、对数据的变更少、查询频繁时,使用varchar。
5.解释什么是队列(queue),栈(stack),有何区别,php哪些数组结合可以实现队列和栈?
栈(Stack)和队列(Queue)是两种操作受限的线性表。
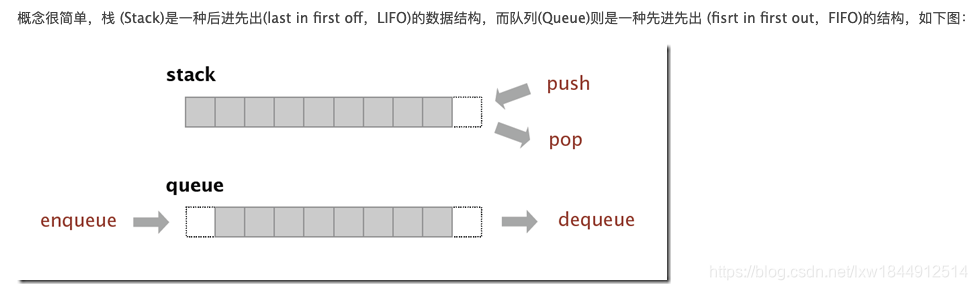
栈与队列的相同点:
1.都是线性结构。
2.插入操作都是限定在表尾进行。
3.都可以通过顺序结构和链式结构实现。、
4.插入与删除的时间复杂度都是O(1),在空间复杂度上两者也一样。
5.多链栈和多链队列的管理模式可以相同。
栈与队列的不同点:
1.删除数据元素的位置不同,栈的删除操作在表尾进行,队列的删除操作在表头进行。
2.应用场景不同;常见栈的应用场景包括括号问题的求解,表达式的转换和求值,函数调用和递归实现,深度优先搜索遍历等;常见的队列的应用场景包括计算机系统中各种资源的管理,消息缓冲器的管理和广度优先搜索遍历等。
3.顺序栈能够实现多栈空间共享,而顺序队列不能。
PHP实现栈和队列:
array_shift : 删除数组中首个元素,并返回被删除元素的值。
array_unshift : 在数组开头插入一个或多个元素。
array_pop:删除数组的最后一个元素(出栈)。
array_push:将一个或多个元素插入数组的末尾(入栈)。
6.php 开发sdk注意什么?
7.linux 查看进程的命令?
ps -A 或者 ps -e
8.PHP多线程开发
9.每天凌晨2:00 的定时任务
-
# 每天早上6点
-
0 6 * * * echo "Good morning." >> /tmp/test.txt //注意单纯echo,从屏幕上看不到任何输出,因为cron把任何输出都email到root的信箱了。
-
-
# 每两个小时
-
0 */2 * * * echo "Have a break now." >> /tmp/test.txt
-
-
# 晚上11点到早上8点之间每两个小时和早上八点
-
0 23-7/2,8 * * * echo "Have a good dream" >> /tmp/test.txt
-
-
# 每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
-
0 11 4 * 1-3 command line
-
-
# 1月1日早上4点
-
0 4 1 1 * command line SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root //如果出现错误,或者有数据输出,数据作为邮件发给这个帐号 HOME=/
-
-
# 每小时(第一分钟)执行/etc/cron.hourly内的脚本
-
01 * * * * root run-parts /etc/cron.hourly
-
-
# 每天(凌晨4:02)执行/etc/cron.daily内的脚本
-
02 4 * * * root run-parts /etc/cron.daily
-
-
# 每星期(周日凌晨4:22)执行/etc/cron.weekly内的脚本
-
22 4 * * 0 root run-parts /etc/cron.weekly
-
-
# 每月(1号凌晨4:42)去执行/etc/cron.monthly内的脚本
-
42 4 1 * * root run-parts /etc/cron.monthly
-
-
# 注意: "run-parts"这个参数了,如果去掉这个参数的话,后面就可以写要运行的某个脚本名,而不是文件夹名。
-
-
# 每天的下午4点、5点、6点的5 min、15 min、25 min、35 min、45 min、55 min时执行命令。
-
5,15,25,35,45,55 16,17,18 * * * command
-
-
# 每周一,三,五的下午3:00系统进入维护状态,重新启动系统。
-
00 15 * *1,3,5 shutdown -r +5
-
-
# 每小时的10分,40分执行用户目录下的innd/bbslin这个指令:
-
10,40 * * * * innd/bbslink
-
-
# 每小时的1分执行用户目录下的bin/account这个指令:
-
1 * * * * bin/account
-
-
# 每天早晨三点二十分执行用户目录下如下所示的两个指令(每个指令以;分隔):
-
203 * * * (/bin/rm -f expire.ls logins.bad;bin/expire$#@62;expire.1st)
10.统计文件的行数
-
wc 命令的作用:统计指定文件中的字节数、字数、行数,并将结果显示输出。
-
-
命令语法:wc [选项] 文件
-
-
该命令选项参数如下:
-
-
-c 统计字节数
-
-
-l 统计行数
-
-
-w 统计字数
-
-
-m 统计字符数
-
-
以上选项可以单独使用也可以组合使用。注意组合使用时输出结果的列的顺序和数目不受选项的顺序和数目的影响。输出结果总是按下述顺序进行显示的。
-
-
行数 字数 字节数 文件名
-
-
例如:
-
-
wc -lcw file1 file2
-
-
则输出结果为:
-
-
9 36 file1
-
-
8 62 file2
-
-
8 24 96 total
-
-
省略任选项-lcw,wc命令的执行结果与上面是一样的。
-
-
以上选项也可以单独使用,例如:
-
-
wc -l filename 输出 filename 的行数
-
-
wc -c filename 输出 filename 的字节数
-
-
wc -m filename 输出 filename 的字符数
-
-
wc -w filename 输出 filename 的单词数
-
-
wc -L filename 输出 filename 文件里最长的那一行是多少个字符数
示例
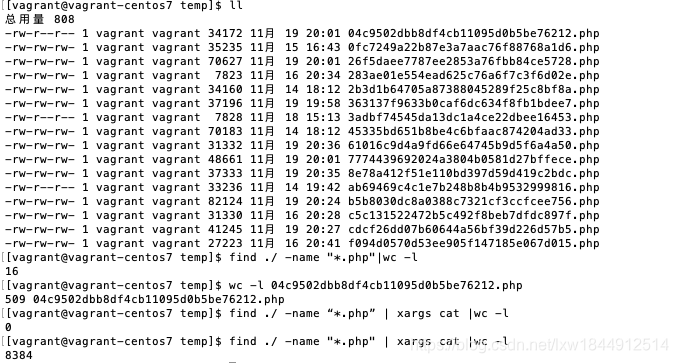
统计当前文件夹下的php文件数目
find . -name “*.php” |wc -l
统计当前目录下所有py文件代码行数:
find ./ -name “*.php” | xargs cat |wc -l
文章来源: blog.csdn.net,作者:lxw1844912514,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/lxw1844912514/article/details/103671878

- 点赞
- 收藏
- 关注作者
评论(0)