不信你看看,MySQL分库分表没有那么难

数据库分库分表估计很多伙伴都没有实践过,就是因为自己公司的业务不是很多,没有那么多数据。假如有一天项目的人数上来了,你写的系统支撑不住了,希望这篇文章带给你一丝丝的思路。
前言
在面试过程中你是不是会经常遇到对于数据库分库分表你有什么方案啊!
在平时看博客时你是不是也经常刷到MySQL如何分库分表。
然而你是不是点进去看了不到10秒就直接退出窗口。
那是因为写的文章不是什么水平切分,就是垂直切割,在一个自身所在的公司根本使用不到。
如果你只知道分库分表但是不知道怎么弄的话,花个五分钟看完你会收获到不一样的思路。
一、初始架构
公司的规模小,项目针对的用户群体属于小众。日活就几千、几万的用户这样的数据每天的数据库单表增加一般不会超过10万。并发更不沾边了。
这种项目规模,我们就是认真、快速开发业务逻辑,提升用户体验,从而提升项目的用户粘度并达到收纳更多用户的准备。
这个时候我们项目一台16核32G的服务器就完全可以了,可以将数据库单独放一个服务器,也可以都放在一个服务器。
这个时候项目架构图是这个样子的。
二、用户开始激增解决方案
在经历了第一阶段后,由于项目的用户体验度极高,项目又吸引了大量的用户。
这时我们项目日活达到了百万级别,注册用户也超过了千万。这个数据是咔咔根据之前公司项目数据推算的。
这时每天单表数据新增达到了100万,并发请求每秒也达到了上万。这时单系统就扛不住了。
假设每天就固定新增100万,每月就是3000万 ,一年就是接近5亿数据。
数据库以这种速度运行下去,数据到2000W到3000W还能勉强撑住,但是你会发现数据库日志会出现越来越多的慢查询。
虽说并发1W,但是我们可以部署个10台机器或者20台机器,平均每台机器承担500到1000的请求,还是绰绰有余的。
但是数据库方面还是用一台服务器支撑着每秒上万的请求,那么你将会遇到以下问题。
- 数据库所在的服务器磁盘IO、网络带宽、CPU负载、内存消耗都会非常高
- 单表数据已经很大,SQL性能已经已经出现下坡阶段,加上数据库服务器负载太高导致性能下降,会直接导致SQL性能更差
- 这个时候最明显的感觉,就是用户获取一个数据可能需要10s以上的时间才会返回。
- 如果前期服务器配置不是很高的话,你就会面临数据库宕机的情况
那么这个时候我们要怎么对项目进行架构的优化呢!
根据大佬们的经验是数据库的连接数每秒控制在2000即可、那么我们1W并发的情况下部署5台机器,每台机器都部署一个同样结构的数据库。
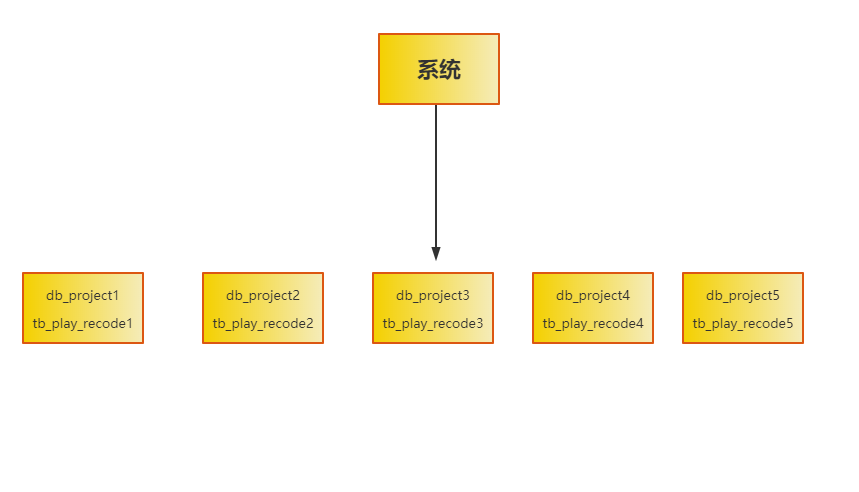
此时在5台数据库拥有同样的数据库。表名规则可以这样设置。
这时每个project库都有一个相同的表,比如db_project1有tb_play_recode1、db_project2有tb_play_recode2…
这样就实现了一个基本的分库分表的思路,从原来一台数据库服务器变成了5台数据库服务器,从原来一个库变成了5个库,原来的一张表变成了5张表。
这时我们就需要借助数据库中间件来完成写数据,例如mycat。
这个时候就需要使用播放记录表的自增ID进行取模5,比如每天播放记录新增100W数据。此时20W数据会落到db_project1的db_play_recode1,其它的四个库分别也会落入20W数据。
查询数据时就根据播放记录的自增ID进行取模5,就可以去对应的数据库,从对应的表里查询数据即可。
实现了这个架构后,我们在来分析一下。
原来播放记录就一张表,现在变成了5张表,那么每个表就变成了1/5
按照原项目的推算,一年如有1亿数据,每张表就只有2000w数据。
按照每天新增50W数据,每张表每天新增10W数据,这样是不是就初步缓解了单表数据量过大影响系统性能问题了。
另外每秒1W的请求,这时每台服务器平均就2000,瞬间就把并发请求降低到了安全范围了。
三、保证查询性能
在上边的数据库架构会遇到一个问题,就是单表数据量还是很大,按照每年1亿的数据,单表就会有2000W数据,还是太大了。
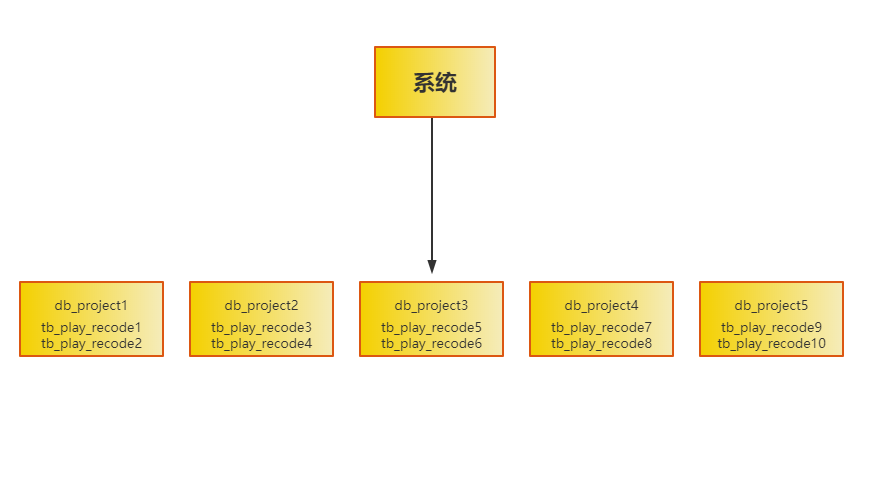
比如可以将播放记录表拆分为100张表,然后分散到5台数据库服务器,这时单表的数据就只有100W,那查询起来还不是洒洒水的啦!
在写数据时就需要经过俩次路由,先对播放记录ID取模数据库数量,这时可以路由到一台数据库上,然后再对那台数据库上的表数量进行取模,最终就会路由到数据上的一个表里了。
通过这个步骤就可以让每个表的数据都非常少,按照100张表,1亿数据,落到每个表的数据就只有100W。
这时的系统架构是这个样子的。
四、配置读写分离来按需扩容
以上的架构整体效果已经很不错了,假设上边分了100张表还是不满足需求,可以通过用户增量计算来配置合理的表。同时还可以保证单表内的SQL执行效率。
这时还会遇到一个问题,假如每台服务器承载每秒2000的请求,其中就400是写入,1600是查询。
也就是说,增删改查中增删改的SQL才占到了20%的比例,80%的请求都是查询。
安装之前的推理,现在所有数据进行翻倍计算,每台服务器并发达到了4000请求了。
那么其中800请求是写入,3200请求是查询,如果说安装目前的情况来扩容,就只需要增加一台数据库服务器即可。但是就会涉及到表的迁移,因为需要迁移一部分表到新的数据库上,那是很麻烦的事情了。
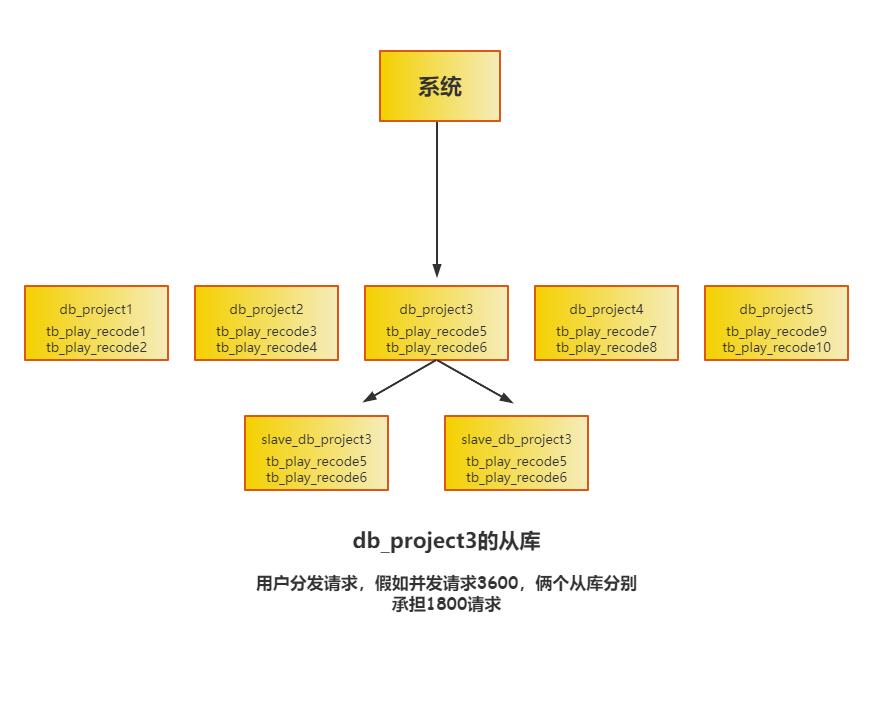
其实没有这个必要的,可以使用读写分离来解决这个问题,也就是主从复制。
写的时候走主库,读数据时走从库,这样就可以让一个表的读写请求分开落到不同的数据库上去执行。
这样的设计后,我们在推算一下,假如写入主库的请求是400/s ,查询从库的请求是就是1800/s,只需要在主库下配置俩台从库即可。
这时的架构是如下的。
实际的生产环境,读请求的增长速度远远高于写的请求,所以读写分离之后,大部分就是扩容从库支撑更高的读请求就可以了。
而且另外一个点,对同一个表,如果既写数据,还读数据,可能会牵扯到锁冲突问题,无论读还是写性能都会有影响。
所以一旦读写分离之后,对主库的表就仅仅是写入,没任何查询会影响主库。对从库就仅仅是查询了。
五、并发数据库结构总结
关于并发场景下,数据库层面的架构是需要进行精心的设计的。
并且在配置主复制时,也会有很多的问题来等着去解决。
本文就是从一个大的角度来梳理一个思路给大家,可以根据自己公司的业务和项目来考虑自己的系统如何分库分表。
分库分表的落地需要借助mycat或者其他数据库中间件来实现。
这几天就会再出一篇文章对于本文的一个实现,并且还有很多问题等着去解决。
例如:自增ID问题,主从复制数据不一致问题,在主从复制这块很多问题,作为程序员的我们就是需要不停的打boos获得最终的胜利。
坚持学习、坚持写博、坚持分享是咔咔从业以来一直所秉持的信念。希望在诺大互联网中咔咔的文章能带给你一丝丝帮助。
文章来源: blog.csdn.net,作者:咔咔-,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/fangkang7/article/details/107554662

- 点赞
- 收藏
- 关注作者
评论(0)