8种人工智能算法求解八皇后问题+原理分析


1 问题描述
八皇后问题——在8×8格的国际象棋盘上摆放8个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上。
在八皇后问题中,不关心求解的路径,而只关注是否达到目标状态——即重要的是最终皇后在棋盘上的布局,而不是皇后加入的先后次序。由于棋盘中棋子状态数呈指数增长,因此八皇后问题的状态空间庞大且未知,利用普通搜索技术——如BFS、DFS、UCS等无法完成既定目标,因为这些算法需要系统地遍历状态空间。
因此选择局部搜索算法,其只探索当前状态的邻域,在邻域中选择若干个状态继续探索它们的邻域,直到找到目标。
2 AI算法
2.1 局部贪婪搜索
经典的爬山算法也称为局部贪婪搜索(Greedy Local Search),其在算法层的原理为:
- 随机生成初始状态;
- 探索初始状态的邻域 ,在 中选择代价最小(或价值最高)的状态;
- 若此状态代价小于当前,则选择此状态为下一个状态;否则算法停止;
- 重复(ii)(iii)直至最优或算法停止。
此算法的实现过程简单,本质上是一种梯度下降算法,因此容易陷入局部最优状态。为了解决爬山法受限于局部最优状态的问题,提出了其几个变种。
2.2 随机行走爬山法
随机行走爬山法(Random Hill Climbing),其在算法层的原理为:
- 随机生成初始状态;
- 探索初始状态的邻域 ,在 中随机选择状态;
- 以一定的概率接受此状态,此概率可以关联“陡峭”程度;
- 不断重复(ii)(iii)直至最优。
随机行走爬山法的优点在于,对所有邻域状态都有概率接受,只不过离最优值近的被选中的概率大,这样可以避免在局部最优点停滞不前。随机行走爬山法的收敛速度通常慢于局部贪婪搜索,但在某些状态空间地形图上可以找到更优解。
2.3 首选爬山法
首选爬山法,是随机行走爬山法和经典爬山法的折中,其在算法层的原理为:
- 随机生成初始状态;
- 探索初始状态的邻域 ,在 中随机选择状态;
- 若该状态优于当前,则接受;否则重新选择;
- 不断重复(ii)(iii)直至最优。
首选爬山法既避免了随机行走爬山法的“漫无目的”,也防止快速陷入局部最优,其在邻域状态很庞大的情况下效率比随机行走更高,但是其依然存在陷入局部最优的可能性。
2.4 随机重启爬山法
随机重启爬山法(Random Restart Hill Climbing),其在算法层的原理为:
- 随机生成初始状态;
- 探索初始状态的邻域 ,在 中选择代价最小(或价值最高)的状态;
- 若此状态优于当前,则选择此状态为下一个状态;否则随机生成下一个状态;
- 重复(ii)(iii)直至最优。
随机重启爬山法是对经典爬山算法受限于局部最优状态的本质改良,但可能因为不断重启影响效率。
2.5 模拟退火算法
模拟退火算法(Simulated Annealing,SA)类似于随机行走爬山法,只不过SA随机因素的引入并非关联“陡峭”程度,而是模拟了退火这一物理过程。
首先解释热力学上的退火过程。如图所示,首先物体处于非晶体的稳定状态。现将其加温至充分高,此时分子热运动加剧,物体的状态充满随机性——几乎可以向任何方向运动;再让其徐徐冷却——即退火,粒子趋近于能量最小,也就可能达到处于晶体的稳态。

基于具体退火的物理过程,引入了退火概率转移函数:
在SA的初期,认为是高温 ,使得SA趋于完全的随机行走——因为其对于劣于当前状态的接受率也趋于1;随着搜索次数的迭代,温度不断降低,此时SA倾向于接收离最优值更近的状态。其中 的降温过程可以用最简单的指数降温: ,或者采用其他的下降方式,如 。
综上所述,SA在算法层的原理为:
- 随机生成初始状态;
- 探索初始状态的邻域 ,在 中随机选择状态;
- 若此状态优于当前,则选择此状态为下一个状态;否则以概率转移函数为基础接受或拒绝此状态;
- 重复(ii)(iii)直至最优。
值得注意的是,SA算法依然可能陷入局部最优,但大多数情况下具有良好的表现。
2.6 局部束搜索
到目前为止的局部搜索算法都是单线的,即每次只探索一个状态。束搜索的思想是:内存虽然有限,但每次只保留一个状态信息又过于极端。因此束搜索算法下,每次搜索都将在内存中保留 个状态, 称为集束宽度
局部束搜索(Local Beam Search)在算法层的原理为:
- 随机生成 个初始状态;
- 分别探索 个初始状态的邻域 ,在所有邻域的并集中选择 个最优的状态;
- 重复(ii)直至最优。
在局部束搜索中,有用的信息在并行的搜索线程间传递,算法将很快放弃没有成果的搜索而把资源都用在取得最大进展的路径上。但如果是最简单形式的局部束搜索,那么由于这 个状态缺乏多样性,它们很快会聚集到状态空间中的一小块区域内,甚至使得搜索代价比高昂的爬山法版本还要多。
2.7 随机束搜索
如随机行走爬山法向爬山法中添加随机因子,解决受限于局部最优的问题一样,随机束搜索(Stochastic Beam Search)向局部束搜索中添加随机因子,防止搜索空间的状态聚合,以保持多样性。其在算法层的原理为:
- 随机生成 个初始状态;
- 分别探索 个初始状态的邻域 ,在所有邻域的并集中随机选择 个状态,随机选择概率可以关联于“陡峭”程度或其他因素;
- 重复(ii)直至最优。
2.8 遗传算法
遗传算法(Genetic Algorithm, GA)类似束搜索,不同在于其选择 个状态的原则,既不是局部束搜索的“贪婪式选择”,也不是随机束搜索简单的概率选择,而是模拟了自然进化演变过程。其在算法层的原理是:
- 随机生成 个初始状态形成初始种群;
- 采用适应度函数对种群进行自然选择,增加种群中距离最优值近的个体的比例;
- 对自然选择后的种群进行杂交,生成子代种群;
- 对子代随机进行变异,以增加种群多样性,防止状态聚合;
- 重复(ii)~(iv)直至最优。
注意:上面原理可以配合源码学习,加深理解
3 结果展示

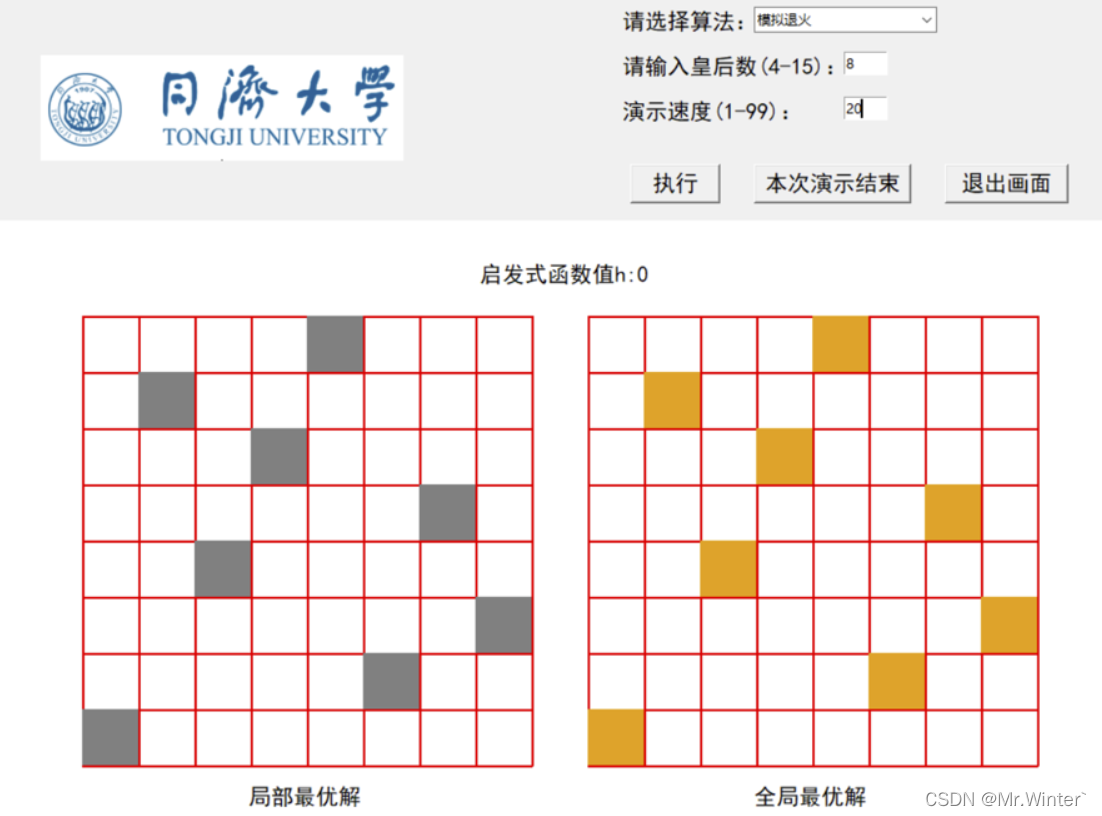
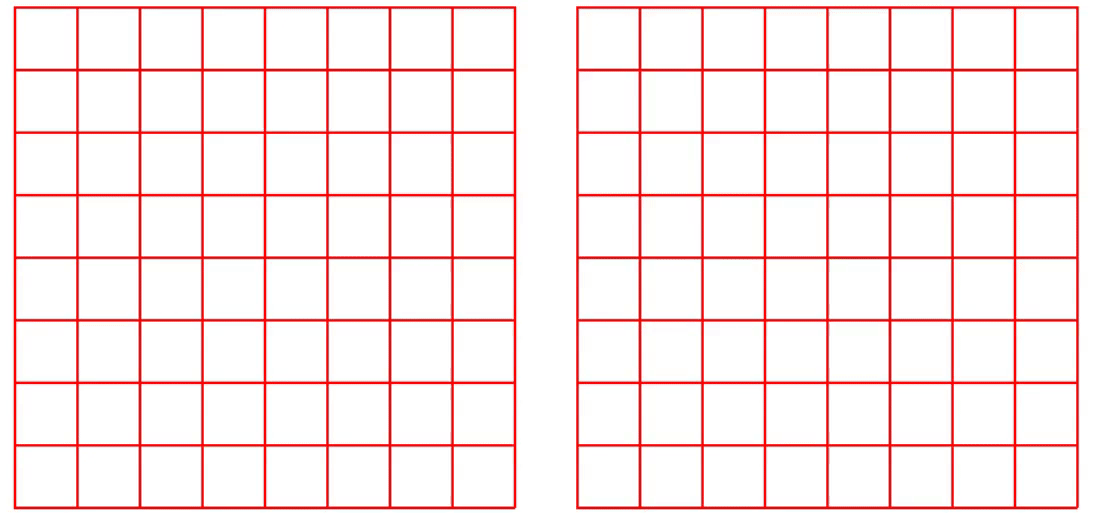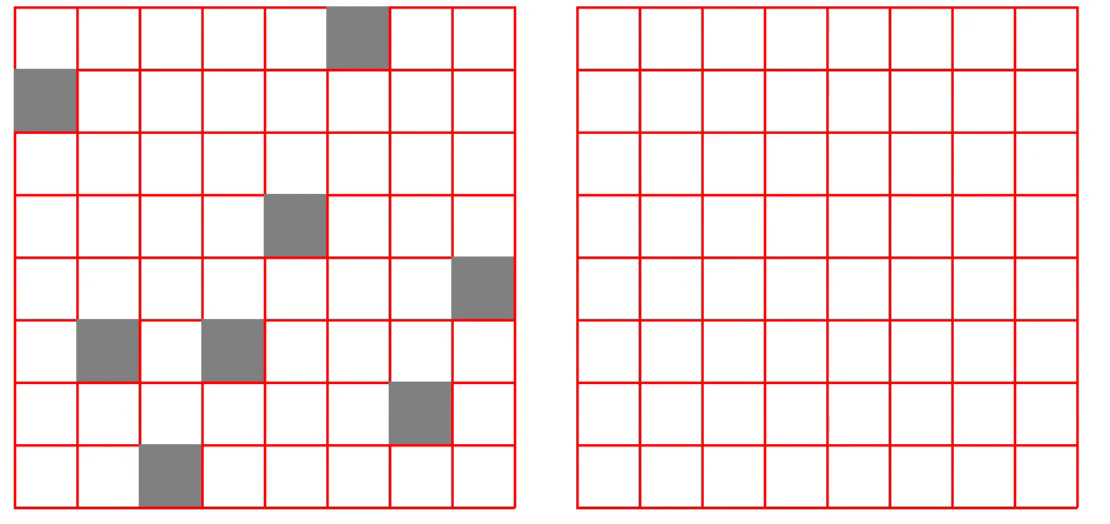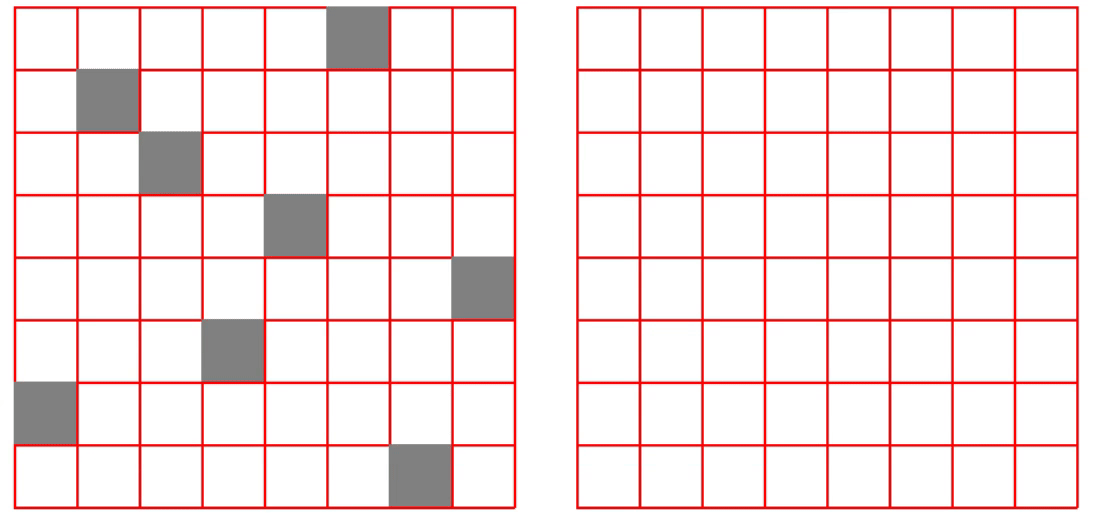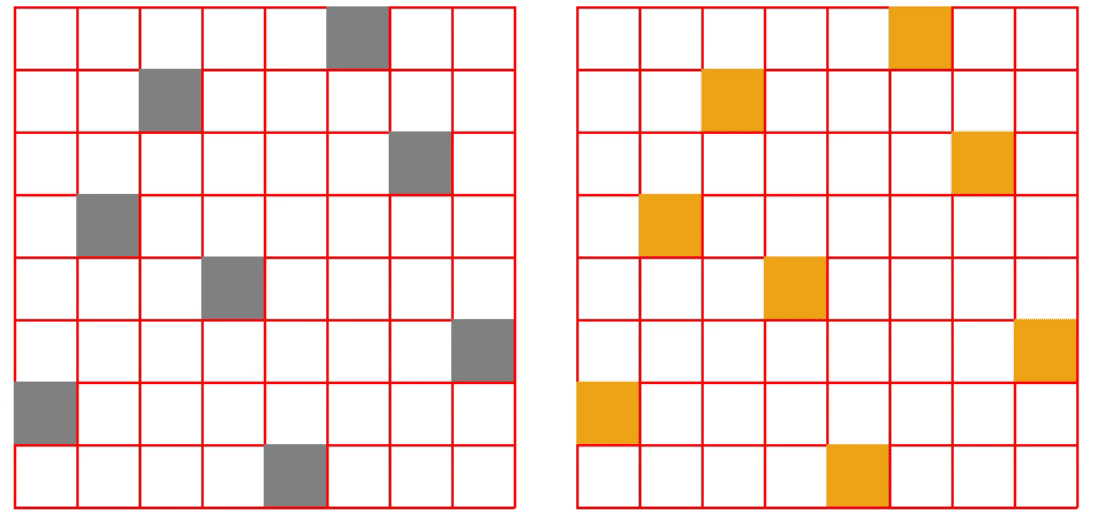
完整代码关注下方公众号回复ML001获取
🔥 更多精彩专栏:
🏠 欢迎加入社区和更多志同道合的朋友交流:AI 技术社


- 点赞
- 收藏
- 关注作者
评论(0)