MYSQL数据库中表的进阶玩法——表分区

【摘要】 MYSQL数据库中表的进阶玩法——表分区
🔎这里是MYSQL加油站
👍如果对你有帮助,给博主一个免费的点赞以示鼓励
欢迎各位🔎点赞👍评论收藏⭐️
什么是表分区?
- mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
- 表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
表分区与分表的区别?
- 分表:指的是通过一定规则,将一张表分解成多张不同的表。比如将用户订单记录根据时间成多个表。
- 分表与分区的区别在于:分区从逻辑上来讲只有一张表,而分表则是将一张表分解成多张表
表分区有什么好处
- 与单个磁盘或文件系统分区相比,可以存储更多的数据。
- 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
- 一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
- 涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这种查询的一个简单例子如 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BYsalesperson_id;”。通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
- 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
表分区的限制因素
- 一个表最多只能有1024个分区。
- MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中提供了非整数表达式分区的支持。
- 如果分区字段中有主键或者唯一索引的列,那么多有主键列和唯一索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
- 分区表中无法使用外键约束。
- MySQL的分区适用于一个表的所有数据和索引,不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表分区,也不能只对表的一部分数据分区。
MYSQL支持的分区类型有哪些?
- RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
- LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
- HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
- KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
- [ ] 说明:在MySQL5.1版本中,RANGE,LIST,HASH分区要求分区键必须是INT类型,或者通过表达式返回INT类型。但KEY分区的时候,可以使用其他类型的列(BLOB,TEXT类型除外)作为分区键。
RANGE创建分区表实例
上面讲了那么多概念,应该都似懂非懂。接下来用实例来彻底搞懂。
1、先建立分区表,代码里有详细注释,正文就不多解释。
-- 建表t1,字段 id name store_id
CREATE TABLE t1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(30),
store_id int NOT NULL DEFAULT 0
)-- 设置引擎,字符集
ENGINE=INNODB DEFAULT CHARSET=utf8
-- 设置分区:这里以store_id字段的值范围设置了四个分区,分别是p0,p1,p2,p3,p4 分区的范围是0-6,6-11,11-16,16-21
PARTITION by RANGE(store_id)(
PARTITION p0 VALUES less than (6),
PARTITION p1 VALUES less than (11),
PARTITION p2 VALUES less than (16),
PARTITION p3 VALUES less than (21)
);
接下来向表中插入数据:
INSERT INTO t1 VALUES(1,'王',3);
INSERT INTO t1 VALUES(2,'王',7);
INSERT INTO t1 VALUES(3,'王',13);
INSERT INTO t1 VALUES(4,'王',20);
INSERT INTO t1 VALUES(5,'王',1);
INSERT INTO t1 VALUES(6,'王',11);
INSERT INTO t1 VALUES(7,'王',18);
再来看一下结果
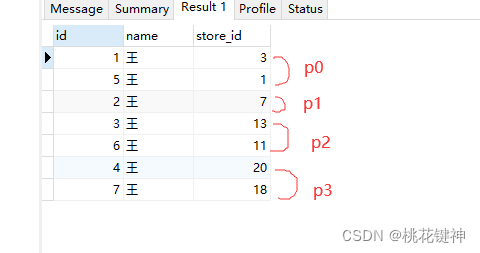
如果不分区,那么插入后的结果应该是按照id排序存放。
现在分区后,数据存放先根据分区存放,在按照id的顺序。
这里只举例了RANGE分区的创建方法,还有三种分区方式后续会继续详细介绍。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)