《透视http协议》笔记

《透视http协议》笔记
1.辨析http的post和put
http里也有增删改查,但是post和put容易搞混
-
查
- GET:从服务器请求资源,可以理解为读取或者下载数据;
- HEAD:类似GET从服务器请求资源,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的“元信息”,因为它的响应头与GET完全相同,所以可以用在很多并不真正需要资源的场合,避免传输 body 数据的浪费;
-
增
- POST:向服务器资源提交数据,相当于写入或上传数据,含义是“新建”,类似于create,不具有幂等性,因为每次执行都会新建一个资源;
-
改
- PUT:也是向服务器资源提交数据,但与POST不同的是它的含义类似于“更新”,即update,具有幂等性;
-
删
- DELETE:删除资源;
2.http状态码
客户端向服务器发送请求,服务器会拼出一个响应报文发回客户端,而状态码就存在于这个响应报文里
-
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
-
2××:成功,报文已经收到并被正确处理;
- “200 OK”是最常见的成功状态码,表示一切正常
- “204 No Content”的含义与“200 OK”基本相同,但响应头后没有body数据
- “206 Partial Content”是HTTP分块下载或断点续传的基础,它与200一样,但body里的数据不是资源的全部,而是其中的一部分
-
3××:重定向,资源位置发生变动,需要客户端重新发送请求(重定向的两个弊端:①性能损耗:会多出一次跳转连接;②循环跳转:例如出现 A=>B=>C=>A 的情况);
- “301 Moved Permanently”俗称“永久重定向”,含义是此次请求的资源已经不存在了,需要改用新的URI再次访问
- “302 Moved Temporarily”,俗称“临时重定向”,意思是请求的资源还在,但需要暂时用另一个URI来访问
- “304 Not Modified” 用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。它不具有通常的跳转含义,但可以理解成“重定向已到缓存的文件”(即“缓存重定向”)。
-
4××:客户端错误,请求报文有误,服务器无法处理;
- “400 Bad Request”是一个通用的错误码,表示请求报文有错误,但具体是数据格式错误、缺少请求头还是 URI 超长它没有明确说,只是一个笼统的错误
- “403 Forbidden”实际上不是客户端的请求出错,而是表示服务器禁止访问资源。例如信息敏感、法律禁止等
- “404 Not Found”表示资源在本服务器上未找到,所以无法提供给客户端
-
5××:服务器错误,服务器在处理请求时内部发生了错误;
- “500 Internal Server Error”服务器通用错误码,不知道服务器究竟发生了什么
- “501 Not Implemented”表示客户端请求的功能还不支持
- “502 Bad Gateway”通常是服务器作为网关或者代理时返回的错误码,表示服务器自身工作正常,访问后端服务器时发生了错误
- “503 Service Unavailable”表示服务器当前很忙,暂时无法响应服务
3.读懂http的body
客户端用 Accept 头告诉服务器希望接收什么样的数据,而服务器用 Content 头告诉客户端实际发送了什么样的数据
在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的“q”参数表示权重来设定优先级,这里的“q”是“quality factor”的意思
权重的最大值是 1,最小值是 0.01,默认值是 1,如果值是0就表示拒绝具体的形式是在数据类型或语言代码后面加一个“;”,然后是“q=value”
例如下面的 Accept 字段:它表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是 0.8。服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
4.http传输大文件
数据压缩:
通常浏览器在发送请求时都会带着“Accept-Encoding”头字段,里面是浏览器支持的压缩格式列表,例如 gzip、deflate、br 等
gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的,再用 gzip 处理也不会变小(甚至还有可能会增大一点),所以就失效了
分块传输:
分块传输是把大文件拆分成多个小文件块,这样服务器和浏览器的内存都不需要保存文件的全部
在响应报文里用头字段“Transfer-Encoding: chunked”来表示,“Transfer-Encoding: chunked”和“Content-Length”这两个字段是互斥的,响应报文里这两个字段不能同时出现,一个响应报文的传输要么是长度已知,要么是长度未知(chunked)
范围请求
比如看视频的时候拖动进度条,其实是想获取一个大文件其中的片段数据,而分块传输并没有这个能力
所以一般采用范围请求的方式,而且服务器必须在响应头里使用字段“Accept-Ranges: bytes”明确告知客户端服务器可以支持范围请求
服务器还要添加一个响应头字段,告诉片段的实际偏移量和资源的总大小,格式是“Content-Range: bytes x-y/length”
5.长短连接
早期的 HTTP 协议使用短连接,收到响应后就立即关闭连接,由于底层是TCP/IP连接,每次建立或关闭连接都非常昂贵,所以效率很低
HTTP/1.1 默认启用长连接,在一个TCP/IP连接上收发多个http请求响应,提高了传输效率
服务器会发送“Connection: keep-alive”字段表示启用了长连接,报文头里如果有“Connection: close”就意味着长连接即将关闭
过多的长连接会占用服务器资源,所以服务器会用一些策略有选择地关闭长连接,比如使用“keepalive_timeout”指令,设置长连接的超时时间,使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数
“队头阻塞”问题会导致性能下降(因为HTTP 规定报文必须是“一发一收”),可以用“并发连接”(也就是同时对一个域名发起多个长连接, 用数量来解决质量的问题)和“域名分片”(多个不同域名都指向同一台服务器)技术缓解
6.http代理
所谓的“代理服务”就是指服务本身不生产内容,而是处于中间位置转发上下游的请求和响应,具有双重身份:面向下游的用户时,表现为服务器,代表源服务器响应客户端的请求;而面向上游的源服务器时,又表现为客户端,代表客户端发送请求
负载均衡:客户端看到的只是代理服务器,于是代理服务器就可以掌握请求分发的“大权”,决定由后面的哪台服务器来响应请求,负载均衡算法有随机、轮询、一致性哈希、最近最少使用等,把外部的流量合理地分散到多台源服务器,提高系统的整体资源利用率和性能
- 健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用
- 安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载
- 加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本
- 数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应
- 内容缓存:暂存、复用服务器响应
http缓存代理
http缓存代理即代理服务器具有了缓存功能,客户端向代理服务器请求数据时,代理服务器不必每次都从源服务器那里获取
还有一种是客户端的缓存(浏览器端),把部分数据保存到本地磁盘,并定期检查最新状态
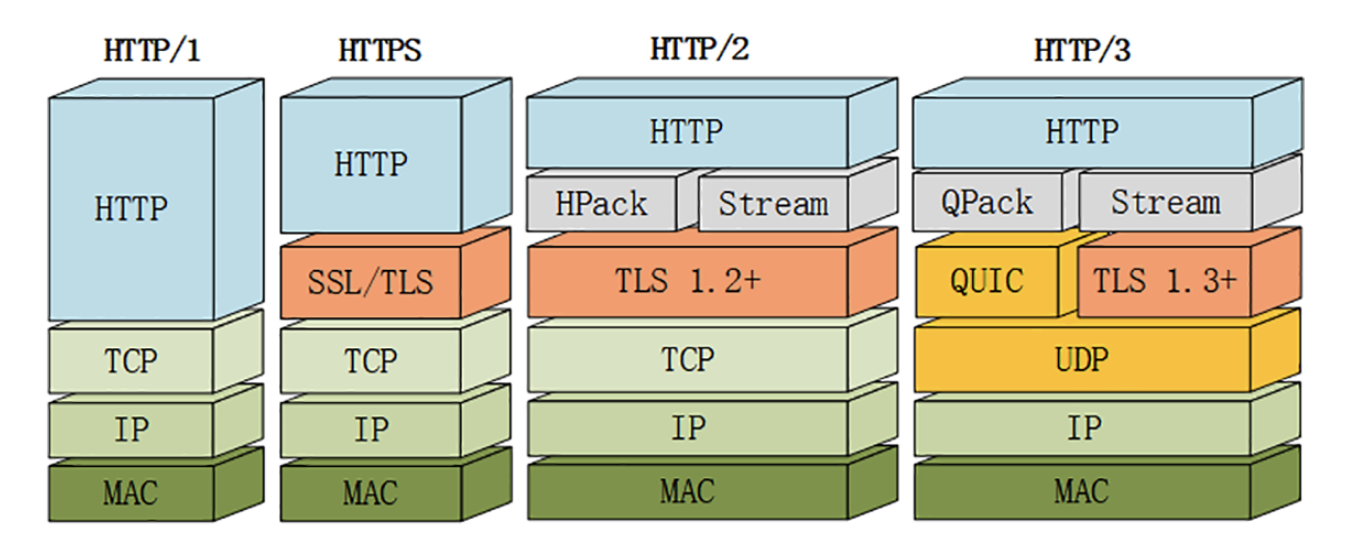
7.https
SSL/TLS保证了安全性,通过加密算法等,但性能还有待改进,所以有后续的 http/2和http/3
8.http/2
HTTP 协议取消了小版本号,所以 HTTP/2 的正式名字不是 2.0,之后也不会再出现小版本号
HTTP/2 在“语义”上兼容 HTTP/1,保留了请求方法、URI 等传统概念
HTTP/2 使用“HPACK”算法压缩头部信息,消除冗余数据节约带宽
HTTP/2 的消息不再是“Header+Body”的形式,而是分散为多个二进制“帧”
HTTP/2 使用虚拟的“流”传输消息,使请求/响应不需要排队等待,基本解决了困扰多年的“队头阻塞”问题,同时实现了“多路复用”,提高连接的利用率
HTTP/2 也增强了安全性,要求至少是 TLS1.2,而且禁用了很多不安全的密码套件
9.http/3
HTTP/3 基于 QUIC 协议,完全解决了“队头阻塞”问题(因为 HTTP/2 都是在应用层里,而在下层 TCP 协议里,还是会发生“队头阻塞”,这是TCP协议固有的)
QUIC 是一个新的传输层协议,建立在 UDP 之上,换掉了TCP,实现了可靠传输
QUIC 内含了 TLS1.3,只能加密通信,支持 0-RTT 快速建连
QUIC 的连接使用“不透明”的连接 ID,不绑定在“IP 地址 + 端口”上,支持“连接迁移”
QUIC 的流与 HTTP/2 的流很相似,但 HTTP/2里的流都是双向的,而HTTP/3则分为双向流和单向流
HTTP/3 没有指定默认端口号如80、443之类的,需要用 HTTP/2 的扩展帧“Alt-Svc”来发现
10.Nginx /OpenResty
二者都是优秀的web服务器,OpenResty在nginx的基础上进行了改进
11.网络保护
web攻击:
- DDos攻击(洪水攻击):黑客会控制许多“僵尸”计算机,向目标服务器发起大量无效请求。因为服务器无法区分正常用户和黑客,只能“照单全收”,这样就挤占了正常用户所应有的资源。如果黑客的攻击强度很大,就会像“洪水”一样对网站的服务能力造成冲击,耗尽带宽、CPU 和内存,导致网站完全无法提供正常服务
- SQL注入:黑客可以构造出非正常的 SQL 语句,获取数据库内部的敏感信息
- HTTP头注入:在“Host”“User-Agent”“X-Forwarded-For”等字段里加入了恶意数据或代码,服务端程序如果解析不当,就会执行预设的恶意代码
- “跨站脚本”(XSS)攻击:它属于“JS 代码注入”,利用 JavaScript 脚本获取未设防的 Cookie
保护方式:
-
传统防火墙:工作在三层(网络层)或四层(传输层),隔离了外网和内网,使用预设的规则,只允许某些特定 IP 地址和端口号的数据包通过,拒绝不符合条件的数据流入或流出内网
-
网络防火墙(WAF):工作在第七层应用层,看到的不仅是 IP 地址和端口号,还能看到整个 HTTP 报文,所以就能够对报文内容做更深入细致的审核,使用更复杂的条件、规则来过滤数据
12.CDN
Content Delivery Network(内容分发网络),它是专门为解决“长距离”上网络访问速度慢而诞生的一种网络应用服务,CDN 的最核心原则是“就近访问”,利用前面讲到的”缓存代理“技术,这种距离最近的节点也叫“边缘节点”,
CDN负载均衡
-
全局负载均衡(Global Sever Load Balance):一般简称为 GSLB,它是 CDN 的“大脑”,主要的职责是当用户接入网络的时候在 CDN 专网中挑选出一个“最佳”节点提供服务,解决的是用户如何找到“最近的”边缘节点,对整个 CDN 网络进行“负载均衡”
-
缓存系统:两个 CDN 的关键概念“命中”和“回源”,“命中”就是指用户访问的资源恰好在缓存系统里,“回源”则正相反,缓存里没有,必须用代理的方式回源站取,好的 CDN应该是命中率越高越好,回源率越低越好
13.WebSocket
“WebSocket”是一种基于 TCP 的轻量级网络通信协议,在地位上是与HTTP“平级”的
HTTP 的“请求 - 应答”模式不适合开发“实时通信”应用,“请求 - 应答”是一种“半双工”的通信模式,虽然可以双向收发数据,但同一时刻只能 一个方向上有动作,传输效率低。更关键的一点,它是一种“被动”通信模式,服务器只能“被动”响应客户端的请求,无法主动向客户端发送数据,效率低,难以实现动态页面,虽然后来的 HTTP/2、HTTP/3 新增了 Stream、Server Push 等特性,但“请求 - 应答”依然是主要的工作方式,所以出现了 WebSocket。
WebSocket 是一个“全双工”的通信协议,相当于对 TCP 做了一层“薄薄的包装”,让它运行在浏览器环境里。
WebSocket 没有使用 TCP 的“IP 地址 + 端口号”,而是使用兼容 HTTP 的 URI 来发现服务,但定义了新的协议名“ws”和“wss”,端口号也沿用了 80 和 443。
WebSocket 使用二进制帧,结构比较简单,特殊的地方是有个“掩码”操作,客户端发数据必须掩码,服务器则不用。
WebSocket 利用 HTTP 协议实现连接握手,发送 GET 请求要求“协议升级”,握手过程中有个非常简单的认证机制,目的是防止误连接。
“Connection: Upgrade”,表示要求协议“升级”
“Upgrade: websocket”,表示要“升级”成 WebSocket 协议
为了防止普通的 HTTP 消息被“意外”识别成 WebSocket,握手消息还增加了两个额外的认证用头字段(所谓的“挑战”,Challenge)。
Sec-WebSocket-Key:一个 Base64 编码的 16 字节随机数,作为简单的认证密钥
Sec-WebSocket-Version:协议的版本号
看到上面的四个字段,就知道这不是一个普通的 GET 请求,而是 WebSocket 的升级请求,接下来就不用 HTTP 了,全改用WebSocket 协议通信。

- 点赞
- 收藏
- 关注作者
评论(0)