【愚公系列】2022年03月 .NET架构班 025-分布式中间件 Kafka介绍

【摘要】 一、Kafka简介Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。Kafka的特点有:同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)可进行持久化操作。将消息持久化到...
一、Kafka简介
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
Kafka的特点有:
- 同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失
- 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器
- 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online和offline的场景
二、Kafka使用场景
| 场景 | 说明 |
|---|---|
| 消息队列 | 比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并常常依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ |
| 行为跟踪 | Kafka的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理 |
| 元信息监控 | 作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控吧 |
| 日志收集 | 日志收集方面,其实开源产品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟 |
| 流处理 | 这个场景可能比较多,也很好理解。保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。Strom和Samza是非常著名的实现这种类型数据转换的框架 |
| 事件源 | 事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。比如动态汇总(News feed) |
| 持久性日志 | Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目 |
三、Kafka相关名称介绍
下面是kafka集群通信图:
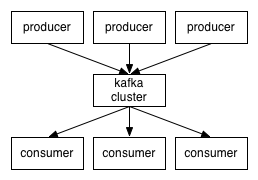
是不是和MQTT协议很像,其实原理都一样。
1.Topic
特指Kafka处理的消息源(feeds of messages)的不同分类。
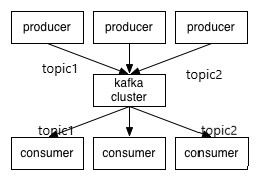
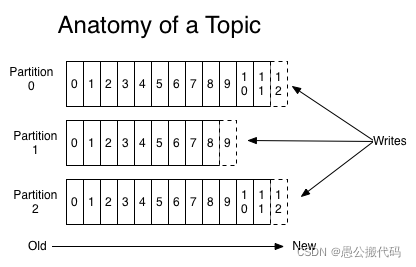
2.Partition
Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
3.Message
消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
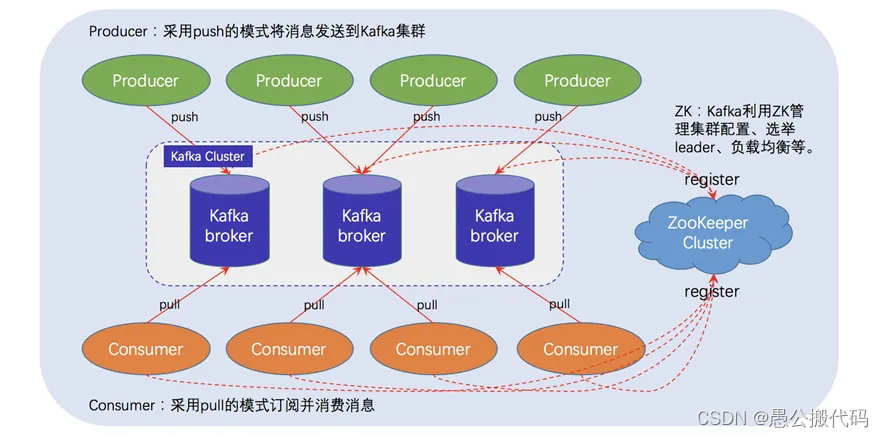
4.Producers
消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
5.Consumers
消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
6.Broker
缓存代理,Kafka集群中的一台或多台服务器统称为broker。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)