快速下载一个网站

有时候我们需要分析一个网站,或者基于一个网站进行魔改,这个就需要一些特殊的手段将网站源码下载到本地了,其实目前大部分网站都是有代码压缩的,很难去有修改。
这里我就教大家如何快速获取一个网站的所有资源,包括源码,图片,js,css。
以这个页面为例
https://loading.io/spinner/

这个页面所显示的图标都是付费的,但我们可以通过一些简单的手段将所有资源下载到本地。其实这并不是什么神奇的技能,有需求,就有供应,就有牛逼的程序来教你做事。
第一种CTRL+S
浏览器打开https://loading.io/spinner/, 按下 CTRL+S, 选择一个保存网站的目录,并且保存类型 选择 网页,全部(*.htm, *.html )
待下载完成后,打开,和原网站相差无几。这个页面所有的资源都保存在了你选择的文件目录里。想要那个图片,svg都可以直接拿去用。是不是很方便。另外需要注意的时候,打开页面的时候最好用http协议打开,以为有些网站不能在file协议下访问。
如果你打算将这个页面,修改完善,当做一个系统的一部分。这里我提供一个修改,优化的思路。
首先要将js挑拣出来,引入了几个包,每个包都是干嘛的,能否去掉,查看控制台,报错显示是那个js报的,能否去掉。有些页面,完全不需要js,只用html和css就能和网站长得一样。我改过很多个网站。
下载后访问效果
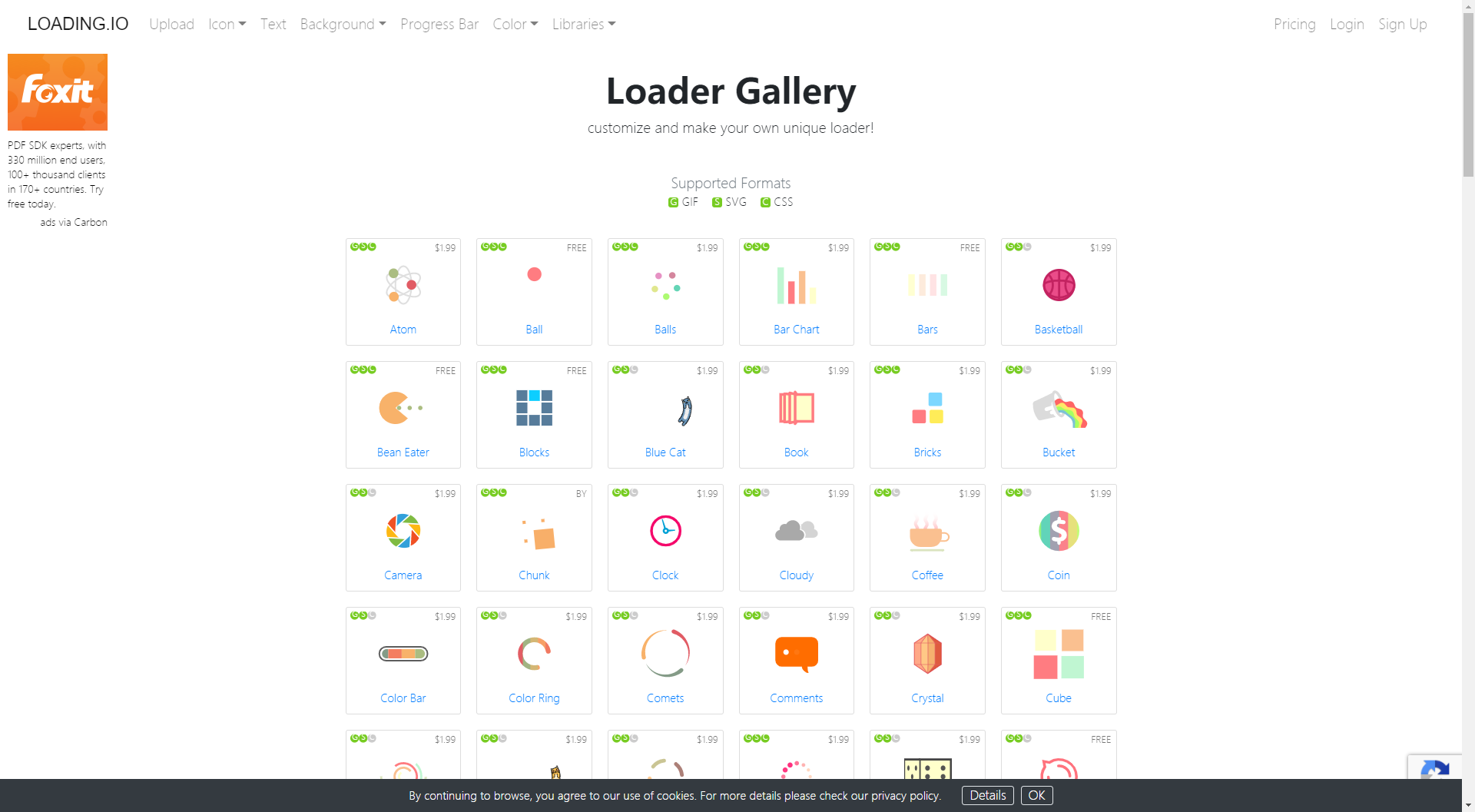
第二种使用Cyotek WebCopy软件
Cyotek WebCopy是一个免费的分析网站拓扑资源图,并提供下载全站资源的功能的软件。非常好用,之前我也用过很多下载网站的,都不如它好。下载地址 https://www.cyotek.com/cyotek-webcopy
下载后一键安装,然后将网站的主页输入,点击开始,程序就能自动分析网站的资源引用关系,并且创建好目录,分门别类下载到对应的文件夹中。你根本不用修改html的资源引用路径。
点击旁边的Scan 可以对整个网站的资源进行分析。分析后的资源图
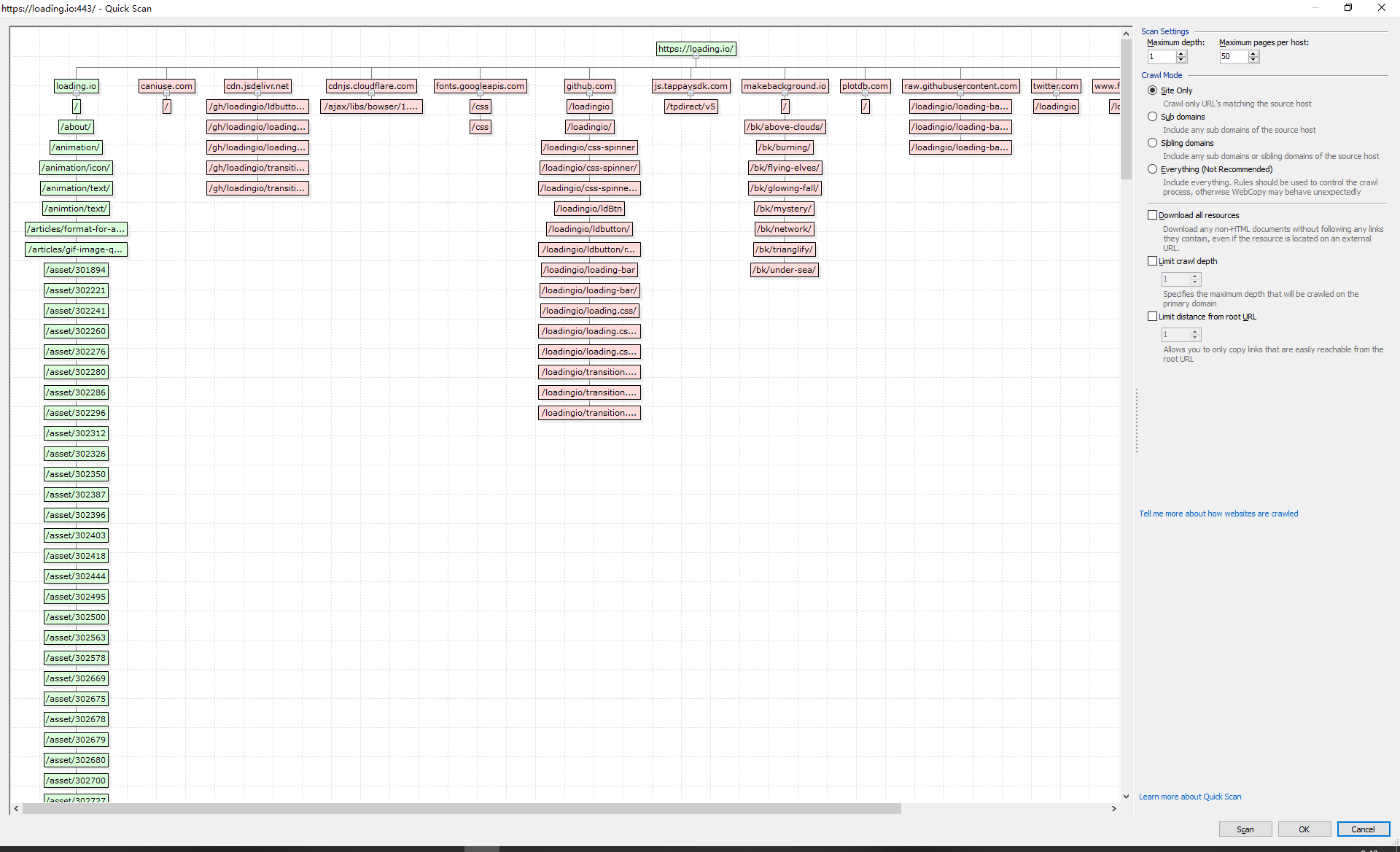
因为一个网站资源可能会有其他域名的,你可以在这里选择,将一些其他域名的资源排除,或者爬取。如果第一次爬取效果不好的话,可以尝试将所有资源加入扒取列表。
下载整个网站的资源,过程是漫长的。你可以砌杯咖啡,慢慢等待。有时候你不用等程序下载完成。
下载完成后,直接将整个文件夹放到web服务器里,就能访问了,链接,图片很多交互,程序都帮你处理好了。
下载后,可能会有多个一个页面,可能会存在多个html,你需要找到效果最好的一个页面作为首页
下面是爬取后的展示
首发地址 https://www.ebaina.com/articles/140000005130
文章来源: fizzz.blog.csdn.net,作者:拿我格子衫来,版权归原作者所有,如需转载,请联系作者。
原文链接:fizzz.blog.csdn.net/article/details/111029235

- 点赞
- 收藏
- 关注作者
评论(0)