万字保姆级Pandas核心知识操作大全

【摘要】
👆点击关注|设为星标|干货速递👆
分享最近常用到pandas做数据处理和分析,特意总结了以下常用内容。
pandas常用速查
引入依赖
# 导入模块import pymysqlimport pandas as pdimport numpy as&nb...
👆点击关注|设为星标|干货速递👆
分享最近常用到pandas做数据处理和分析,特意总结了以下常用内容。
pandas常用速查
引入依赖
-
# 导入模块
-
import pymysql
-
import pandas as pd
-
import numpy as np
-
import time
-
-
# 数据库
-
from sqlalchemy import create_engine
-
-
# 可视化
-
import matplotlib.pyplot as plt
-
# 如果你的设备是配备Retina屏幕的mac,可以在jupyter notebook中,使用下面一行代码有效提高图像画质
-
%config InlineBackend.figure_format = 'retina'
-
# 解决 plt 中文显示的问题 mymac
-
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
-
# 设置显示中文 需要先安装字体 aistudio
-
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
-
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
-
import seaborn as sns
-
# notebook渲染图片
-
%matplotlib inline
-
import pyecharts
-
-
# 忽略版本问题
-
import warnings
-
warnings.filterwarnings("ignore")

-
# 下载中文字体
-
!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
-
# 将字体文件复制到 matplotlib'字体路径
-
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/Lib/python3,7/site-packages/matplotib/mpl-data/fonts.
-
-
# 一般只需要将字体文件复制到系统字体田录下即可,但是在 studio上该路径没有写权限,所以此方法不能用
-
# !cp simhei. ttf /usr/share/fonts/
-
-
# 创建系统字体文件路径
-
!mkdir .fonts
-
# 复制文件到该路径
-
!cp simhei.ttf .fonts/
-
!rm -rf .cache/matplotlib
算法相关依赖
-
# 数据归一化
-
from sklearn.preprocessing import MinMaxScaler
-
-
# kmeans聚类
-
from sklearn.cluster import KMeans
-
# DBSCAN聚类
-
from sklearn.cluster import DBSCAN
-
# 线性回归算法
-
from sklearn.linear_model import LinearRegression
-
# 逻辑回归算法
-
from sklearn.linear_model import LogisticRegression
-
# 高斯贝叶斯
-
from sklearn.naive_bayes import GaussianNB
-
# 划分训练/测试集
-
from sklearn.model_selection import train_test_split
-
# 准确度报告
-
from sklearn import metrics
-
# 矩阵报告和均方误差
-
from sklearn.metrics import classification_report, mean_squared_error
获取数据
-
from sqlalchemy import create_engine
-
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/ry?charset=utf8')
-
-
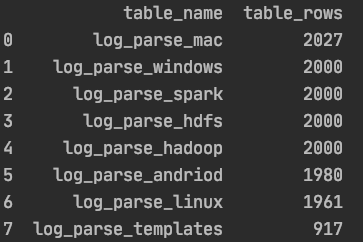
# 查询插入后相关表名及行数
-
result_query_sql = "use information_schema;"
-
engine.execute(result_query_sql)
-
result_query_sql = "SELECT table_name,table_rows FROM tables WHERE TABLE_NAME LIKE 'log%%' order by table_rows desc;"
-
df_result = pd.read_sql(result_query_sql, engine)
生成df
-
# list转df
-
df_result = pd.DataFrame(pred,columns=['pred'])
-
df_result['actual'] = test_target
-
df_result
-
-
# df取子df
-
df_new = df_old[['col1','col2']]
-
-
# dict生成df
-
df_test = pd.DataFrame({'A':[0.587221, 0.135673, 0.135673, 0.135673, 0.135673],
-
'B':['a', 'b', 'c', 'd', 'e'],
-
'C':[1, 2, 3, 4, 5]})
-
-
# 指定列名
-
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
-
-
# 使用numpy生成20个指定分布(如标准正态分布)的数
-
tem = np.random.normal(0, 1, 20)
-
df3 = pd.DataFrame(tem)
-
-
# 生成一个和df长度相同的随机数dataframe
-
df1 = pd.DataFrame(pd.Series(np.random.randint(1, 10, 135)))
重命名列
-
# 重命名列
-
data_scaled = data_scaled.rename(columns={'本体油位': 'OILLV'})
增加列
-
# df2df
-
df_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime'])
-
-
# 新增一列根据salary将数据分为3组
-
bins = [0,5000, 20000, 50000]
-
group_names = ['低', '中', '高']
-
df['categories'] = pd.cut(df['salary'], bins, labels=group_names)
缺失值处理
-
# 检查数据中是否含有任何缺失值
-
df.isnull().values.any()
-
-
# 查看每列数据缺失值情况
-
df.isnull().sum()
-
-
# 提取某列含有空值的行
-
df[df['日期'].isnull()]
-
-
# 输出每列缺失值具体行数
-
for i in df.columns:
-
if df[i].count() != len(df):
-
row = df[i][df[i].isnull().values].index.tolist()
-
print('列名:"{}", 第{}行位置有缺失值'.format(i,row))
-
-
# 众数填充
-
heart_df['Thal'].fillna(heart_df['Thal'].mode(dropna=True)[0], inplace=True)
-
-
# 连续值列的空值用平均值填充
-
dfcolumns = heart_df_encoded.columns.values.tolist()
-
for item in dfcolumns:
-
if heart_df_encoded[item].dtype == 'float':
-
heart_df_encoded[item].fillna(heart_df_encoded[item].median(), inplace=True)
独热编码
df_encoded = pd.get_dummies(df_data)
替换值
-
# 按列值替换
-
num_encode = {
-
'AHD': {'No':0, "Yes":1},
-
}
-
heart_df.replace(num_encode,inplace=True)
删除列
df_jj2.drop(['coll_time', 'polar', 'conn_type', 'phase', 'id', 'Unnamed: 0'],axis=1,inplace=True)
groupby
-
# 0.从sklearn加载iris数据集
-
from sklearn import datasets
-
# 加载数据集和目标
-
data, target = datasets.load_iris(return_X_y=True, as_frame=True)
-
# 合并数据集和目标
-
iris = pd.concat([data, target], axis=1, sort=False)
-
iris
-
-
# 创建groupby对象
-
iris_gb = iris.groupby('target')
-
-
# 1. 创建频率表,输出每个类中数量多少
-
iris_gb.size()
-
-
# 2. 计算常用的描述统计量
-
# min、max()、medianhe、std等
-
# 计算均值
-
iris_gb.mean()
-
# 单列
-
iris_gb['sepal length (cm)'].mean()
-
# 双列
-
iris_gb[['sepal length (cm)', 'sepal width (cm)']].mean()
-
-
# 3. 查找最大值(最小值)索引
-
iris_gb.idxmax()
-
-
# 按sepal_length最大值这个条件进行了筛选
-
sepal_largest = iris.loc[iris_gb['sepal length (cm)'].idxmax()]
-
-
# 4. Groupby之后重置索引
-
iris_gb.max().reset_index()
-
# ↑↓二者效果相同
-
iris.groupby('target', as_index=False).max()
-
-
# 5. 多种统计量汇总,聚合函数agg
-
iris_gb[['sepal length (cm)', 'sepal width (cm)']].agg(["min", "mean"])
-
-
# 6.特定列的聚合
-
# 为不同的列单独设置不同的统计量
-
iris_gb.agg({"sepal length (cm)": ["min", "max"], "sepal width (cm)": ["mean", "std"]})
-
-
# 7. NamedAgg命名统计量
-
# 把每个列下面的统计量和列名分别合并起来。可以使用NamedAgg来完成列的命名
-
-
iris_gb.agg(
-
sepal_min=pd.NamedAgg(column="sepal length (cm)", aggfunc="min"),
-
sepal_max=pd.NamedAgg(column="sepal length (cm)", aggfunc="max"),
-
petal_mean=pd.NamedAgg(column="petal length (cm)", aggfunc="mean"),
-
petal_std=pd.NamedAgg(column="petal length (cm)", aggfunc="std")
-
)
-
-
# 下述更简洁
-
iris_gb.agg(
-
sepal_min=("sepal length (cm)", "min"),
-
sepal_max=("sepal length (cm)", "max"),
-
petal_mean=("petal length (cm)", "mean"),
-
petal_std=("petal length (cm)", "std")
-
)
-
-
# 8. 使用自定义函数
-
iris_gb.agg(pd.Series.mean)
-
# 不仅如此,名称和功能对象也可一起使用。
-
iris_gb.agg(["min", pd.Series.mean])
-
# 我们还可以自定义函数,也都是可以的。
-
def double_length(x):
-
return 2*x.mean()
-
-
iris_gb.agg(double_length)
-
# 如果想更简洁,也可以使用lambda函数。总之,用法非常灵活,可以自由组合搭配。
-
iris_gb.agg(lambda x: x.mean())
透视表
-
import numpy as np
-
import pandas as pd
-
import seaborn as sns
-
titanic = sns.load_dataset('titanic')
-
-
titanic.pivot_table(index='sex', columns='class')
-
-
# 默认对所有列进行聚合,这时我们给与values参数,只计算想要的结果
-
agg = pd.cut(titanic["age"],[0,18,80]) # 对年龄数据列进行分段,便于观看
-
titanic.pivot_table(index=['sex','age'], columns='class',values=['survived','fare'])
-
-
# 在实际使用中,并不一定每次都要均值,使用aggfunc指定累计函数
-
titanic.pivot_table(index='sex', columns='class',aggfunc={'survived':sum, 'fare':'mean'})
-
-
# 当需要计算每一组的总数时,可以通过margins 参数来设置:
-
# margin 的标签可以通过margins_name 参数进行自定义,默认值是"All"。
-
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
数据筛选
-
# 取第33行数据
-
df.iloc[32]
-
-
# 某列以xxx字符串开头
-
df_jj2 = df_512.loc[df_512["transformer"].str.startswith('JJ2')]
-
-
df_jj2yya = df_jj2.loc[df_jj2["变压器编号"]=='JJ2YYA']
-
-
# 提取第一列中不在第二列出现的数字
-
df['col1'][~df['col1'].isin(df['col2'])]
-
-
# 查找两列值相等的行号
-
np.where(df.secondType == df.thirdType)
-
-
# 包含字符串
-
results = df['grammer'].str.contains("Python")
-
-
# 提取列名
-
df.columns
-
-
# 查看某列唯一值(种类)
-
df['education'].nunique()
-
-
# 删除重复数据
-
df.drop_duplicates(inplace=True)
-
-
# 某列等于某值
-
df[df.col_name==0.587221]
-
# df.col_name==0.587221 各行判断结果返回值(True/False)
-
-
# 查看某列唯一值及计数
-
df_jj2["变压器编号"].value_counts()
-
-
# 时间段筛选
-
df_jj2yyb_0501_0701 = df_jj2yyb[(df_jj2yyb['r_time'] >=pd.to_datetime('20200501')) & (df_jj2yyb['r_time'] <= pd.to_datetime('20200701'))]
-
-
# 数值筛选
-
df[(df['popularity'] > 3) & (df['popularity'] < 7)]
-
-
# 按数据类型选择列
-
df = pd.DataFrame({'a': [1, 2] * 3,
-
'b': [True, False] * 3,
-
'c': [1.0, 2.0] * 3})
-
print('df:', df)
-
-
# 输出包含 bool 数据类型的列
-
print('输出包含 bool 数据类型的列:', df.select_dtypes(include='bool'))
-
-
# 输出包含小数数据类型的列
-
print('输出包含小数数据类型的列:', df.select_dtypes(include=['float64']))
-
-
# 输出排除整数的列
-
print('输出包含小数数据类型的列:', df.select_dtypes(exclude=['int64']))
-
-
# 某列字符串截取
-
df['Time'].str[0:8]
-
-
# 随机取num行
-
ins_1 = df.sample(n=num)
-
-
# 数据去重
-
df.drop_duplicates(['grammer'])
-
-
# 按某列排序(降序)
-
df.sort_values("popularity",inplace=True, ascending=False)
-
-
# 取某列最大值所在行
-
df[df['popularity'] == df['popularity'].max()]
-
-
# 取某列最大num行
-
df.nlargest(num,'col_name')
-
# 最大num列画横向柱形图
-
df.nlargest(10).plot(kind='barh')
差值计算
-
# axis=0或index表示上下移动, periods表示移动的次数,为正时向下移,为负时向上移动。
-
print(df.diff( periods=1, axis=‘index‘))
-
print(df.diff( periods=-1, axis=0))
-
# axis=1或columns表示左右移动,periods表示移动的次数,为正时向右移,为负时向左移动。
-
print(df.diff( periods=1, axis=‘columns‘))
-
print(df.diff( periods=-1, axis=1))
-
-
# 变化率计算
-
data['收盘价(元)'].pct_change()
-
-
# 以5个数据作为一个数据滑动窗口,在这个5个数据上取均值
-
df['收盘价(元)'].rolling(5).mean()
数据修改
-
# 删除最后一行
-
df = df.drop(labels=df.shape[0]-1)
-
-
# 添加一行数据['Perl',6.6]
-
row = {'grammer':'Perl','popularity':6.6}
-
df = df.append(row,ignore_index=True)
-
-
# 某列小数转百分数
-
df.style.format({'data': '{0:.2%}'.format})
-
-
# 反转行
-
df.iloc[::-1, :]
-
-
# 以两列制作数据透视
-
pd.pivot_table(df,values=["salary","score"],index="positionId")
-
-
# 同时对两列进行计算
-
df[["salary","score"]].agg([np.sum,np.mean,np.min])
-
-
# 对不同列执行不同的计算
-
df.agg({"salary":np.sum,"score":np.mean})
时间格式转换
-
# 时间戳转时间字符串
-
df_jj2['cTime'] =df_jj2['coll_time'].apply(lambda x: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(x)))
-
-
# 时间字符串转时间格式
-
df_jj2yyb['r_time'] = pd.to_datetime(df_jj2yyb['cTime'])
-
-
# 时间格式转时间戳
-
dtime = pd.to_datetime(df_jj2yyb['r_time'])
-
v = (dtime.values - np.datetime64('1970-01-01T08:00:00Z')) / np.timedelta64(1, 'ms')
-
df_jj2yyb['timestamp'] = v
设置索引列
df_jj2yyb_small_noise = df_jj2yyb_small_noise.set_index('timestamp')
折线图
-
fig, ax = plt.subplots()
-
df.plot(legend=True, ax=ax)
-
plt.legend(loc=1)
-
plt.show()

-
plt.figure(figsize=(20, 6))
-
plt.plot(max_iter_list, accuracy, color='red', marker='o',
-
markersize=10)
-
plt.title('Accuracy Vs max_iter Value')
-
plt.xlabel('max_iter Value')
-
plt.ylabel('Accuracy')

散点图
-
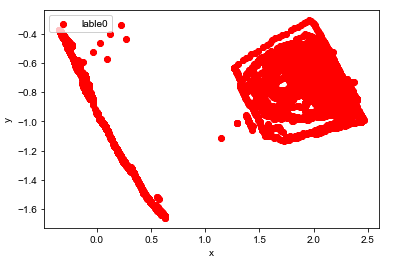
plt.scatter(df[:, 0], df[:, 1], c="red", marker='o', label='lable0')
-
plt.xlabel('x')
-
plt.ylabel('y')
-
plt.legend(loc=2)
-
plt.show()
柱形图
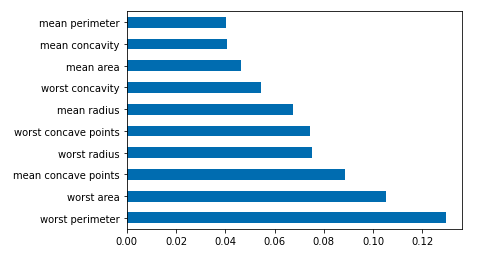
-
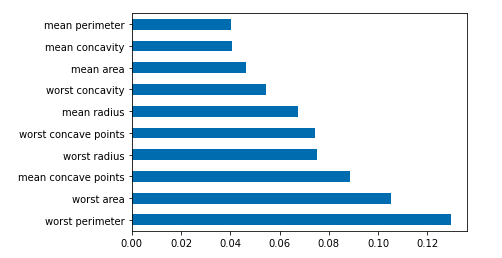
df = pd.Series(tree.feature_importances_, index=data.columns)
-
# 取某列最大Num行画横向柱形图
-
df.nlargest(10).plot(kind='barh')
热力图
-
df_corr = combine.corr()
-
plt.figure(figsize=(20,20))
-
g=sns.heatmap(df_corr,annot=True,cmap="RdYlGn")

66个最常用的pandas数据分析函数
-
df #任何pandas DataFrame对象
-
s #任何pandas series对象
从各种不同的来源和格式导入数据
-
pd.read_csv(filename) # 从CSV文件
-
pd.read_table(filename) # 从分隔的文本文件(例如CSV)中
-
pd.read_excel(filename) # 从Excel文件
-
pd.read_sql(query, connection_object) # 从SQL表/数据库中读取
-
pd.read_json(json_string) # 从JSON格式的字符串,URL或文件中读取。
-
pd.read_html(url) # 解析html URL,字符串或文件,并将表提取到数据帧列表
-
pd.read_clipboard() # 获取剪贴板的内容并将其传递给 read_table()
-
pd.DataFrame(dict) # 从字典中,列名称的键,列表中的数据的值
导出数据
-
df.to_csv(filename) # 写入CSV文件
-
df.to_excel(filename) # 写入Excel文件
-
df.to_sql(table_name, connection_object) # 写入SQL表
-
df.to_json(filename) # 以JSON格式写入文件
创建测试对象
-
pd.DataFrame(np.random.rand(20,5)) # 5列20行随机浮点数 pd.Series(my_list) # 从一个可迭代的序列创建一个序列 my_list
-
df.index = pd.date_range('1900/1/30', periods=df.shape[0]) # 添加日期索引
查看、检查数据
-
df.head(n) # DataFrame的前n行
-
df.tail(n) # DataFrame的最后n行
-
df.shape # 行数和列数
-
df.info() # 索引,数据类型和内存信息
-
df.describe() # 数值列的摘要统计信息
-
s.value_counts(dropna=False) # 查看唯一值和计数
-
df.apply(pd.Series.value_counts) # 所有列的唯一值和计数
数据选取
-
使用这些命令选择数据的特定子集。
-
df[col] # 返回带有标签col的列
-
df[[col1, col2]] # 返回列作为新的DataFrame
-
s.iloc[0] # 按位置选择
-
s.loc['index_one'] # 按索引选择
-
df.iloc[0,:] # 第一行
-
df.iloc[0,0] # 第一栏的第一元素
数据清理
-
df.columns = ['a','b','c'] # 重命名列
-
pd.isnull() # 空值检查,返回Boolean Arrray
-
pd.notnull() # 与pd.isnull() 相反
-
df.dropna() # 删除所有包含空值的行
-
df.dropna(axis=1) # 删除所有包含空值的列
-
df.dropna(axis=1,thresh=n) # 删除所有具有少于n个非null值的行
-
df.fillna(x) # 将所有空值替换为x
-
s.fillna(s.mean()) # 用均值替换所有空值(均值可以用统计模块中的几乎所有函数替换 )
-
s.astype(float) # 将系列的数据类型转换为float
-
s.replace(1,'one') # 1 用 'one'
-
s.replace([1,3],['one','three']) # 替换所有等于的值 替换为所有1 'one' ,并 3 用 'three' df.rename(columns=lambda x: x + 1) # 列的重命名
-
df.rename(columns={'old_name': 'new_ name'})# 选择性重命名
-
df.set_index('column_one') # 更改索引
-
df.rename(index=lambda x: x + 1) # 大规模重命名索引
筛选,排序和分组依据
-
df[df[col] > 0.5] # 列 col 大于 0.5 df[(df[col] > 0.5) & (df[col] < 0.7)] # 小于 0.7 大于0.5的行
-
df.sort_values(col1) # 按col1升序对值进行排序
-
df.sort_values(col2,ascending=False) # 按col2 降序对值进行 排序
-
df.sort_values([col1,col2],ascending=[True,False]) #按 col1 升序排序,然后 col2 按降序排序
-
df.groupby(col) #从一个栏返回GROUPBY对象
-
df.groupby([col1,col2]) # 返回来自多个列的groupby对象
-
df.groupby(col1)[col2] # 返回中的值的平均值 col2,按中的值分组 col1 (平均值可以用统计模块中的几乎所有函数替换 )
-
df.pivot_table(index=col1,values=[col2,col3],aggfunc=mean) # 创建一个数据透视表组通过 col1 ,并计算平均值的 col2 和 col3
-
df.groupby(col1).agg(np.mean) # 在所有列中找到每个唯一col1 组的平均值
-
df.apply(np.mean) #np.mean() 在每列上应用该函数
-
df.apply(np.max,axis=1) # np.max() 在每行上应用功能
数据合并
-
df1.append(df2) # 将df2添加 df1的末尾 (各列应相同)
-
pd.concat([df1, df2],axis=1) # 将 df1的列添加到df2的末尾 (行应相同)
-
df1.join(df2,on=col1,how='inner') # SQL样式将列 df1 与 df2 行所在的列col 具有相同值的列连接起来。'how'可以是一个 'left', 'right', 'outer', 'inner'
数据统计
-
df.describe() # 数值列的摘要统计信息
-
df.mean() # 返回均值的所有列
-
df.corr() # 返回DataFrame中各列之间的相关性
-
df.count() # 返回非空值的每个数据帧列中的数字
-
df.max() # 返回每列中的最高值
-
df.min() # 返回每一列中的最小值
-
df.median() # 返回每列的中位数
-
df.std() # 返回每列的标准偏差
16个函数,用于数据清洗
-
# 导入数据集
-
import pandas as pd
-
-
df ={'姓名':[' 黄同学','黄至尊','黄老邪 ','陈大美','孙尚香'],
-
'英文名':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'],
-
'性别':['男','women','men','女','男'],
-
'身份证':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'],
-
'身高':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'],
-
'家庭住址':['湖北广水','河南信阳','广西桂林','湖北孝感','广东广州'],
-
'电话号码':['13434813546','19748672895','16728613064','14561586431','19384683910'],
-
'收入':['1.1万','8.5千','0.9万','6.5千','2.0万']}
-
df = pd.DataFrame(df)
-
df

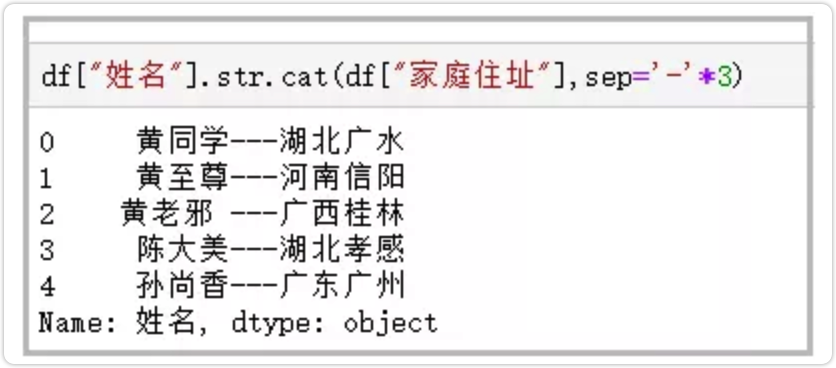
1.cat函数
用于字符串的拼接
df["姓名"].str.cat(df["家庭住址"],sep='-'*3)
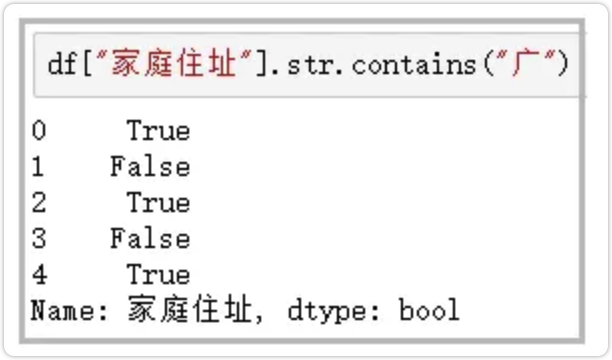
2.contains
判断某个字符串是否包含给定字符
df["家庭住址"].str.contains("广")
3.startswith/endswith
判断某个字符串是否以…开头/结尾
-
# 第一个行的“ 黄伟”是以空格开头的
-
df["姓名"].str.startswith("黄")
-
df["英文名"].str.endswith("e")
4.count
计算给定字符在字符串中出现的次数
df["电话号码"].str.count("3")

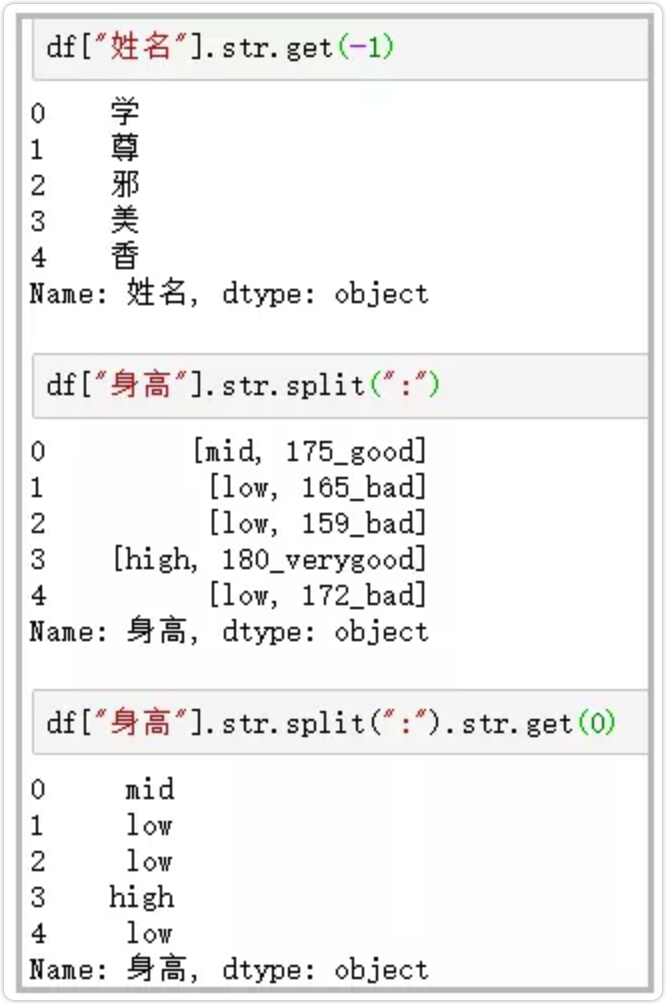
5.get
获取指定位置的字符串
-
df["姓名"].str.get(-1)
-
df["身高"].str.split(":")df["身高"].str.split(":").str.get(0)
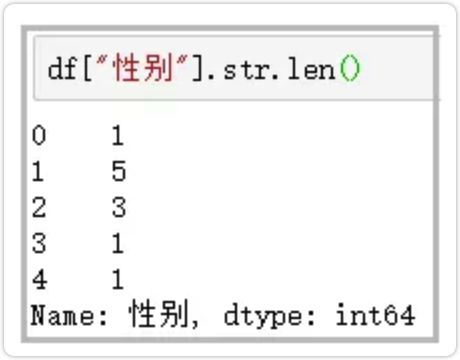
6.len
计算字符串长度
df["性别"].str.len()
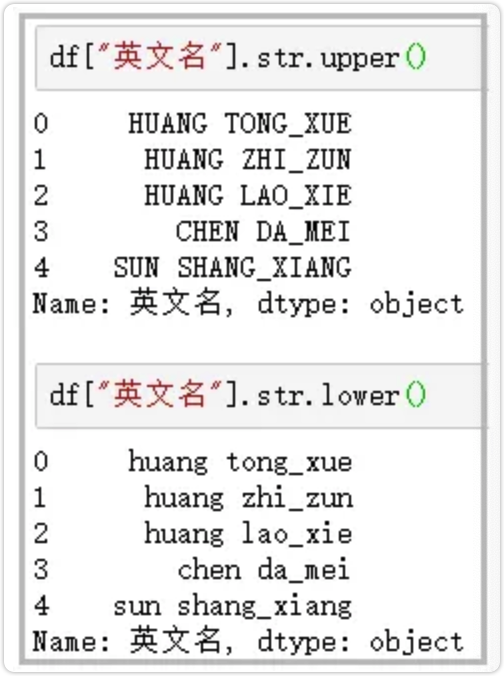
7.upper/lower
英文大小写转换
-
df["英文名"].str.upper()
-
df["英文名"].str.lower()
8.pad+side参数/center
在字符串的左边、右边或左右两边添加给定字符
-
df["家庭住址"].str.pad(10,fillchar="*") # 相当于ljust()
-
df["家庭住址"].str.pad(10,side="right",fillchar="*") # 相当于rjust()
-
df["家庭住址"].str.center(10,fillchar="*")

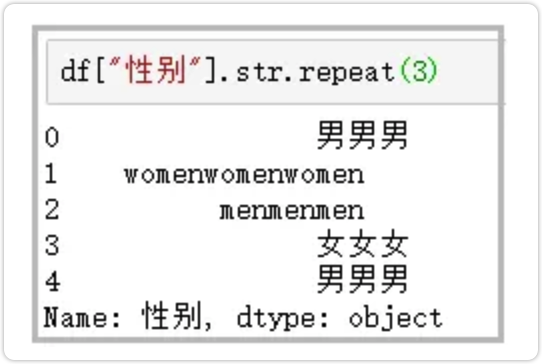
9.repeat
重复字符串几次
df["性别"].str.repeat(3)
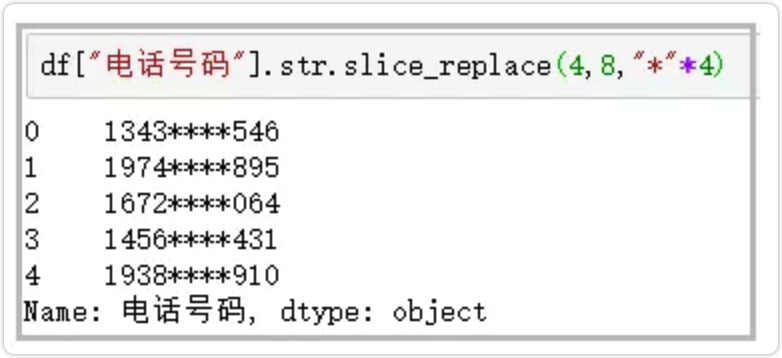
10.slice_replace
使用给定的字符串,替换指定的位置的字符
df["电话号码"].str.slice_replace(4,8,"*"*4)
11.replace
将指定位置的字符,替换为给定的字符串
df["身高"].str.replace(":","-")

12.replace
将指定位置的字符,替换为给定的字符串(接受正则表达式)
replace中传入正则表达式,才叫好用;
先不要管下面这个案例有没有用,你只需要知道,使用正则做数据清洗多好用;
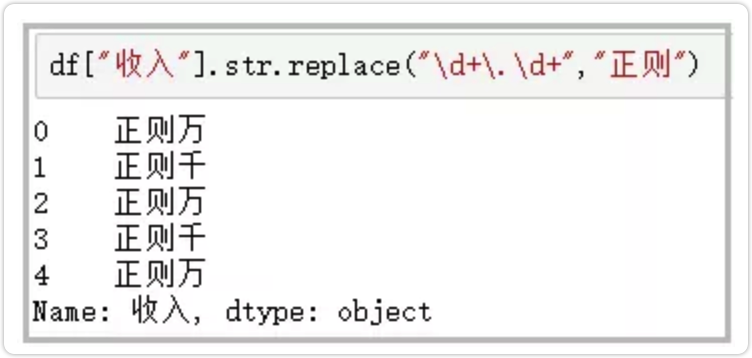
df["收入"].str.replace("\d+\.\d+","正则")
13.split方法+expand参数
搭配join方法功能很强大
-
# 普通用法
-
df["身高"].str.split(":")
-
# split方法,搭配expand参数
-
df[["身高描述","final身高"]] = df["身高"].str.split(":",expand=True)
-
df
-
# split方法搭配join方法
-
df["身高"].str.split(":").str.join("?"*5)

14.strip/rstrip/lstrip
去除空白符、换行符
-
df["姓名"].str.len()
-
df["姓名"] = df["姓名"].str.strip()
-
df["姓名"].str.len()

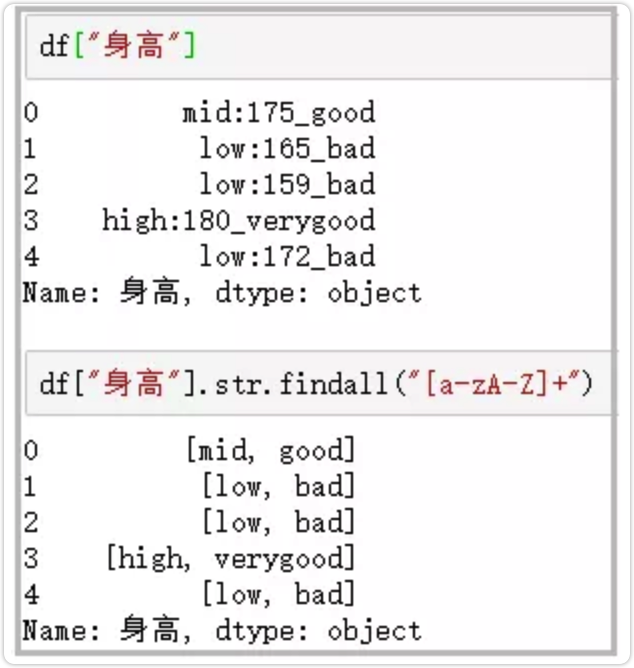
15.findall
利用正则表达式,去字符串中匹配,返回查找结果的列表
findall使用正则表达式,做数据清洗,真的很香!
-
df["身高"]
-
df["身高"].str.findall("[a-zA-Z]+")
16.extract/extractall
接受正则表达式,抽取匹配的字符串(一定要加上括号)
-
df["身高"].str.extract("([a-zA-Z]+)")
-
# extractall提取得到复合索引
-
df["身高"].str.extractall("([a-zA-Z]+)")
-
# extract搭配expand参数
-
df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True)

来源:https://github.com/SeafyLiang/Python_study
推荐阅读 点击标题可跳转
文章来源: ityard.blog.csdn.net,作者:Python小二,版权归原作者所有,如需转载,请联系作者。
原文链接:ityard.blog.csdn.net/article/details/123437179

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)