事务隔离级别是怎么实现的?

事务隔离级别是怎么实现的?
这是我的钱包,共有 100 万元。

今天我心情好,我决定给你的转账 100 万,最后的结果肯定是我的余额变为 0 元,你的余额多了 100 万元,是不是想到就很开心?
转账这一动作在程序里会涉及到一系列的操作,假设我向你转账 100 万的过程是有下面这几个步骤组成的:

可以看到这个转账的过程涉及到了两次修改数据库的操作。
假设在执行第三步骤之后,服务器忽然掉电了,就会发生一个蛋疼的事情,我的账户扣了 100 万,但是钱并没有到你的账户上,也就是说这 100 万消失了!
要解决这个问题,就要保证转账业务里的所有数据库的操作是不可分割的,要么全部执行成功 ,要么全部失败,不允许出现中间状态的数据。
数据库中的「事务(*Transaction*)」就能达到这样的效果,我们在转账操作前先开启事务,等所有数据库操作执行完成后,才提交事务,对于已经提交的事务来说,该事务对数据库所做的修改将永久生效,如果中途发生发生中断或错误,那么该事务期间对数据库所做的修改将会被回滚到没执行该事务之前的状态。
没错,今天就来图解 MySQL 事务啦,开车!
事务有哪些特性?
事务是由 MySQL 的引擎来实现的,我们常见的 InnoDB 引擎它是支持事务的。
不过并不是所有的引擎都能支持事务,比如 MySQL 原生的 MyISAM 引擎就不支持事务,也正是这样,所以大多数 MySQL 的引擎都是用 InnoDB。
事务看起来感觉简单,但是要实现事务必须要遵守 4 个特性,分别如下:
- 原子性(*Atomicity*):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,而且事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样;
- 一致性(*Consistency*):数据库的完整性不会因为事务的执行而受到破坏,比如表中有一个字段为姓名,它有唯一约束,也就是表中姓名不能重复,如果一个事务对姓名字段进行了修改,但是在事务提交后,表中的姓名变得非唯一性了,这就破坏了事务的一致性要求,这时数据库就要撤销该事务,返回初始化的状态。
- 隔离性(*Isolation*):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- 持久性(*Durability*):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
InnoDB 引擎通过什么技术来保证事务的这四个特性的呢?
- 原子性和持久性是通过 redo log (重做日志)来保证的;
- 一致性是通过 undo log(回滚日志) 来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
这次将重点介绍事务的隔离性,这也是面试时最常问的知识的点。
为什么事务要有隔离性,我们就要知道并发事务时会引发什么问题。
并行事务会引发什么问题?
MySQL 服务端是允许多个客户端连接的,这意味着 MySQL 会出现同时处理多个事务的情况。
那么在同时处理多个事务的时候,就可能出现脏读(*dirty read*)、不可重复读(*non-repeatable read*)、幻读(*phantom read*)的问题。
接下来,通过举例子给大家说明,这些问题是如何发生的。
脏读
如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库中读取小林的余额数据,然后再执行更新操作,如果此时事务 A 还没有提交事务,而此时正好事务 B 也从数据库中读取小林的余额数据,那么事务 B 读取到的余额数据是刚才事务 A 更新后的数据,即使没有提交事务。
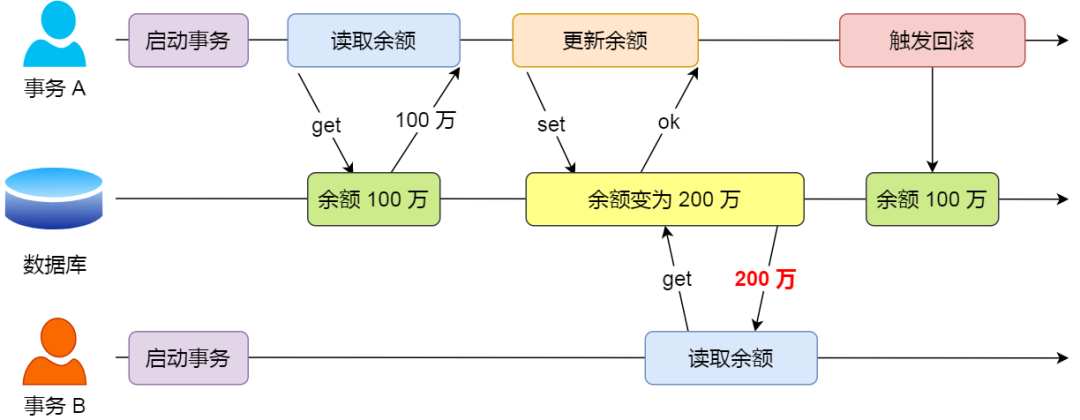
因为事务 A 是还没提交事务的,也就是它随时可能发生回滚操作,如果在上面这种情况事务 A 发生了回滚,那么事务 B 刚才得到的数据就是过期的数据,这种现象就被称为脏读。
不可重复读
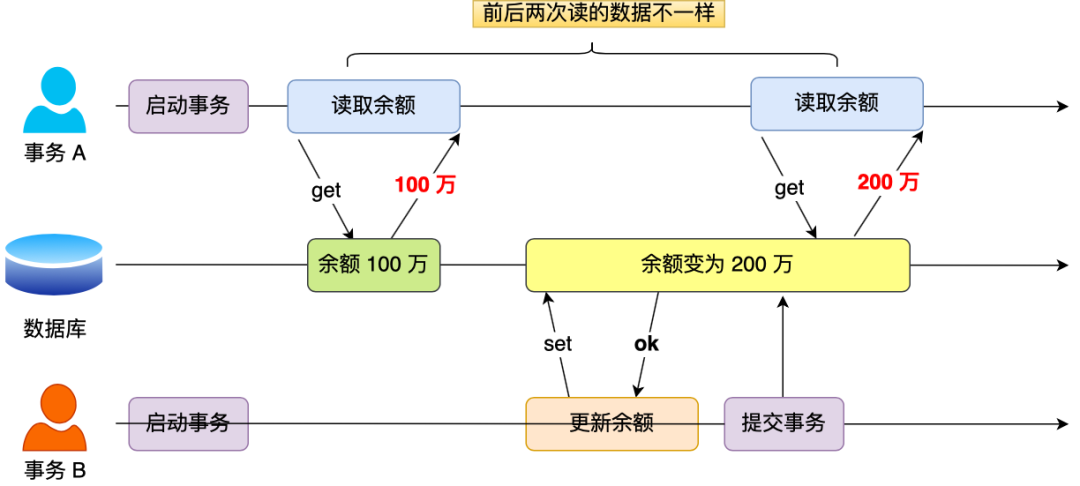
在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,就意味着发生了「不可重复读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库中读取小林的余额数据,然后继续执行代码逻辑处理,在这过程中如果事务 B 更新了这条数据,并提交了事务,那么当事务 A 再次读取该数据时,就会发现前后两次读到的数据是不一致的,这种现象就被称为不可重复读。
幻读
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库查询账户余额大于 100 万的记录,发现共有 5 条,然后事务 B 也按相同的搜索条件也是查询出了 5 条记录。
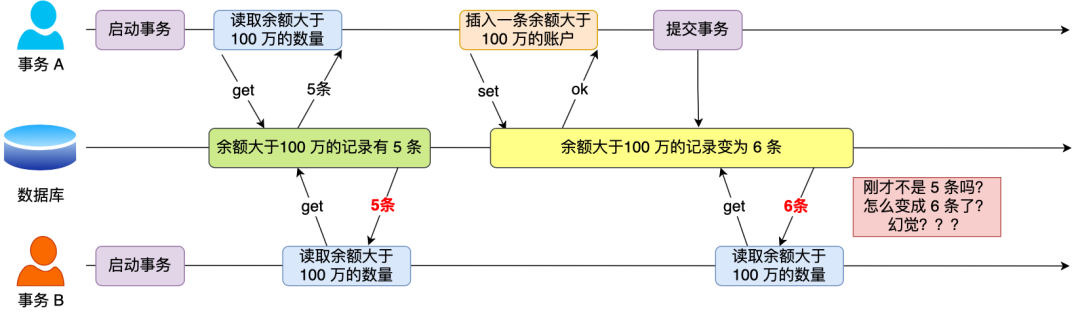
接下来,事务 A 插入了一条余额超过 100 万的账号,并提交了事务,此时数据库超过 100 万余额的账号个数就变为 6。
然后事务 B 再次查询账户余额大于 100 万的记录,此时查询到的记录数量有 6 条,发现和前一次读到的记录数量不一样了,就感觉发生了幻觉一样,这种现象就被称为幻读。
事务的隔离级别有哪些?
前面我们提到,当多个事务并发执行时可能会遇到「脏读、不可重复读、幻读」的现象,这些现象会对事务的一致性产生不同程序的影响。
- 脏读:读到其他事务未提交的数据;
- 不可重复读:前后读取的数据不一致;
- 幻读:前后读取的记录数量不一致。
这三个现象的严重性排序如下:

SQL 标准提出了四种隔离级别来规避这些现象,隔离级别约高,性能效率就越低,这四个隔离级别如下:
- 读未提交(*read uncommitted*),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(*read committed*),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(*repeatable read*),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(*serializable* );会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:
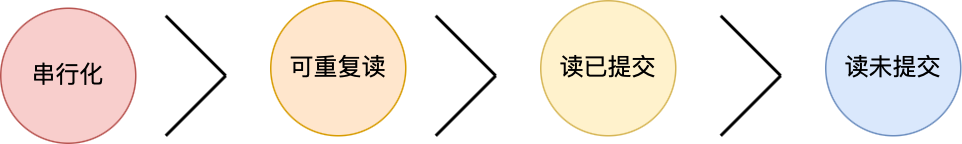
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
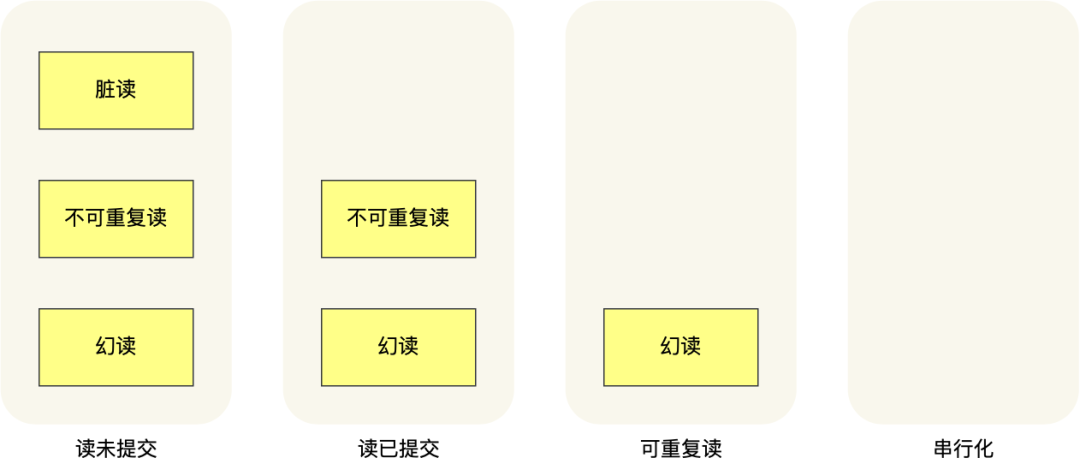
也就是说:
- 在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
- 在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
- 在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
- 在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
所以,要解决脏读现象,就要升级到「读提交」以上的隔离级别;要解决不可重复读现象,就要升级到「可重复读」的隔离级别。
不过,要解决幻读现象不建议将隔离级别升级到「串行化」,因为这样会导致数据库在并发事务时性能很差。InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它通过next-key lock 锁(行锁和间隙锁的组合)来锁住记录之间的“间隙”和记录本身,防止其他事务在这个记录之间插入新的记录,这样就避免了幻读现象。
接下里,举个具体的例子来说明这四种隔离级别,有一张账户余额表,里面有一条记录:
然后有两个并发的事务,事务 A 只负责查询余额,事务 B 则会将我的余额改成 200 万,下面是按照时间顺序执行两个事务的行为:
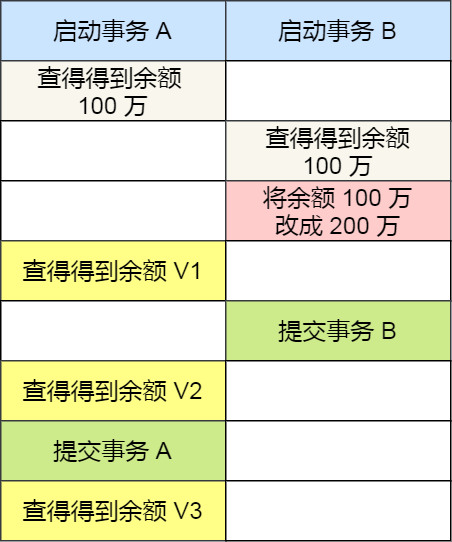
在不同隔离级别下,事务 A 执行过程中查询到的余额可能会不同:
- 在「读未提交」隔离级别下,事务 B 修改余额后,虽然没有提交事务,但是此时的余额已经可以被事务 A 看见了,于是事务 A 中余额 V1 查询的值是 200 万,余额 V2、V3 自然也是 200 万了;
- 在「读提交」隔离级别下,事务 B 修改余额后,因为没有提交事务,所以事务 A 中余额 V1 的值还是 100 万,等事务 B 提交完后,最新的余额数据才能被事务 A 看见,因此额 V2、V3 都是 200 万;
- 在「可重复读」隔离级别下,事务 A 只能看见启动事务时的数据,所以余额 V1、余额 V2 的值都是 100 万,当事务 A 提交事务后,就能看见最新的余额数据了,所以余额 V3 的值是 200 万;
- 在「串行化」隔离级别下,事务 B 在执行将余额 100 万修改为 200 万时,由于此前事务 A 执行了读操作,这样就发生了读写冲突,于是就会被锁住,直到事务 A 提交后,事务 B 才可以继续执行,所以从 A 的角度看,余额 V1、V2 的值是 100 万,余额 V3 的值是 200万。
这四种隔离级别具体是如何实现的呢?
- 对于「读未提交」隔离级别的事务来说,因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好了;
- 对于「串行化」隔离级别的事务来说,通过加读写锁的方式来避免并行访问;
- 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。「读提交」隔离级别是在每个读取数据前都生成一个 Read View,而「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View。
接下来详细说下,「读提交」和「可重复读」隔离级别到底怎样实现的,Read View 又是如何工作的?
可重复读隔离级别是如何实现的?
「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View。
想要知道可重复读隔离级别是如何实现的,我们需要了解两个知识:
- Read View 中四个字段作用;
- 聚族索引记录中两个跟事务有关的隐藏列;
那 Read View 到底是个什么东西?
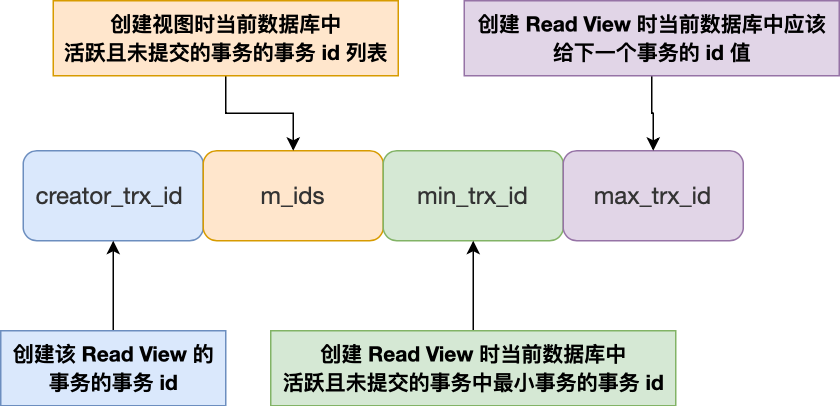
Read View 有四个重要的字段:
- m_ids :指的是创建 Read View 时当前数据库中活跃且未提交的事务的事务 id 列表,注意是一个列表。
- min_trx_id :指的是创建 Read View 时当前数据库中活跃且未提交的事务中最小事务的事务 id,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
知道了 Read View 的字段,我们还需要了解聚族索引记录中的两个隐藏列,假设在账户余额表插入一条小林余额为 100 万的记录,然后我把这两个隐藏列也画出来,该记录的整个示意图如下:
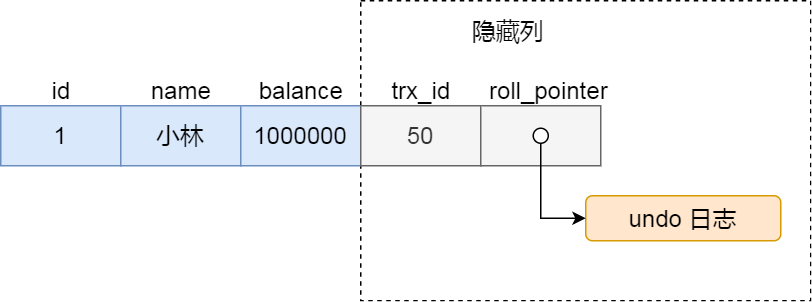
对于使用 InnoDB 存储引擎的数据库表,它的聚族索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚族索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚族索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
了解完这两个知识点后,就可以跟大家说说可重复读隔离级别是如何实现的。
假设事务 A 和 事务 B 差不多同一时刻启动,那这两个事务创建的 Read View 如下:

事务 A 和 事务 B 的 Read View 具体内容如下:
- 在事务 A 的 Read View 中,它的事务 id 是 51,由于与事务 B 同时启动,所以此时活跃的事务的事务 id 列表是 51 和 52,活跃的事务 id 中最小的事务 id 是事务 A 本身,下一个事务 id 应该是 53。
- 在事务 B 的 Read View 中,它的事务 id 是 52,由于与事务 A 同时启动,所以此时活跃的事务的事务 id 列表是 51 和 52,活跃的事务 id 中最小的事务 id 是事务 A,下一个事务 id 应该是 53。
然后让事务 A 去读账户余额为 100 万的记录,在找到记录后,它会先看这条记录的 trx_id,此时发现 trx_id 为 50,通过和事务 A 的 Read View 的 m_ids 字段发现,该记录的事务 id 并不在活跃事务的列表中,并且小于事务 A 的事务 id,这意味着,这条记录的事务早就在事务 A 前提交过了,所以该记录对事务 A 可见,也就是事务 A 可以获取到这条记录。
接着,事务 B 通过 update 语句将这条记录修改了,将小林的余额改成 200 万,这时 MySQL 会记录相应的 undo log,并以链表的方式串联起来,形成版本链,如下图:
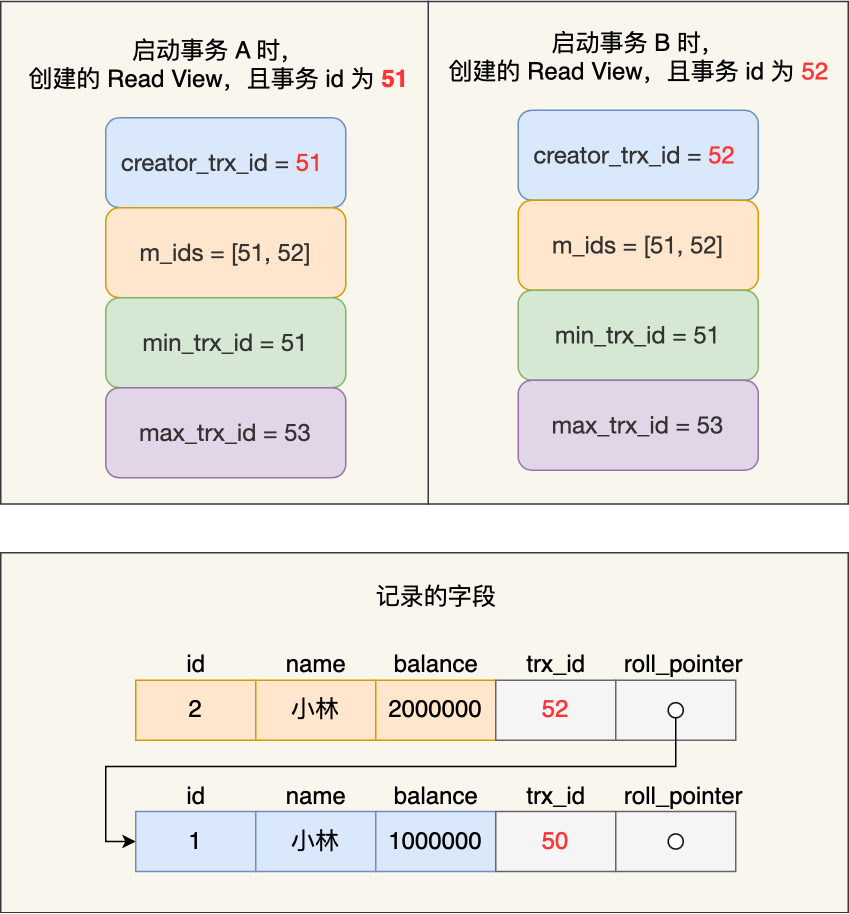
你可以在上图的「记录字段」看到,由于事务 B 修改了该记录,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的 trx_id 是事务 B 的事务 id。
然后如果事务 A 再次读取该记录,发现这条记录的 trx_id 为 52,比自己的事务 id 还大,并且比下一个事务 id 53 小,这意味着,事务 A 读到是和自己同时启动事务的事务 B 修改的数据,这时事务 A 并不会读取这条记录,而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 等于或者小于事务 A 的事务 id 的第一条记录,所以事务 A 再一次读取到 trx_id 为 50 的记录,也就是小林余额是 100 万的这条记录。
「可重复读」隔离级别就是在启动时创建了 Read View,然后在事务期间读取数据的时候,在找到数据后,先会将该记录的 trx_id 和该事务的 Read View 里的字段做个比较:
- 如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要小,且不在 m_ids 列表里,这意味着这条记录的事务早就在该事务前提交过了,所以该记录对该事务可见;
- 如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要大,且在 m_ids 列表里,这意味着该事务读到的是和自己同时启动的另外一个事务修改的数据,这时就不应该读取这条记录,而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 等于或者小于该事务 id 的第一条记录。
就是通过这样的方式实现了,「可重复读」隔离级别下在事务期间读到的数据都是事务启动前的记录。
这种通过记录的版本链来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
读提交隔离级别是如何实现的?
「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
那读提交隔离级别是怎么实现呢?我们还是以前面的例子来聊聊。
假设事务 A 和 事务 B 差不多同一时刻启动,然后事务 B 将小林的账户余额修改成了 200 万,但是事务 B 还未提交,这时事务 A 读到的数据,应该还是小林账户余额为 100 万的数据,那具体怎么做到的呢?
事务 A 在找到小林这条记录时,会看这条记录的 trx_id,发现和事务 A 的 Read View 中的 creator_trx_id 要大,而且还在 m_ids 列表里,说明这条记录被事务 B 修改过,而且还可以知道事务 B 并没有提交事务,因为如果提交了事务,那么这条记录的 trx_id 就不会在 m_ids 列表里。因此,事务 A 不能读取该记录,而是沿着 undo log 链条往下找。
当事务 B 修改数据并提交了事务后,这时事务 A 读到的数据,就是小林账户余额为 200 万的数据,那具体怎么做到的呢?

事务 A 在找到小林这条记录时,会看这条记录的 trx_id,发现和事务 A 的 Read View 中的 creator_trx_id 要大,而且不在 m_ids 列表里,说明该记录的 trx_id 的事务是已经提交过的了,于是事务 A 就可以读取这条记录,这也就是所谓的读已提交机制。
总结
事务是在 MySQL 引擎层实现的,我们常见的 InnoDB 引擎是支持事务的,事务的四大特性是原子性、一致性、隔离性、持久性,我们这次主要讲的是隔离性。
当多个事务并发执行的时候,会引发脏读、不可重复读、幻读这些问题,那为了避免这些问题,SQL 提出了四种隔离级别,分别是读未提交、读已提交、可重复读、串行化,从左往右隔离级别顺序递增,隔离级别越高,意味着性能越差,InnoDB 引擎的默认隔离级别是可重复读。
要解决脏读现象,就要将隔离级别升级到读已提交以上的隔离级别,要解决不可重复读现象,就要将隔离级别升级到可重复读以上的隔离级别。而对于幻读现象,不建议将隔离级别升级为串行化,因为这会导致数据库并发时性能很差。InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它通过next-key lock 锁(行锁和间隙锁的组合)来锁住记录之间的“间隙”和记录本身,防止其他事务在这个记录之间插入新的记录,这样就避免了幻读现象。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 **Read View **来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
文章来源: blog.csdn.net,作者:小林coding,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_34827674/article/details/123448068

- 点赞
- 收藏
- 关注作者
评论(0)