Java中容易混淆的基础知识

面向对象
三大特性:
继承,封装,多态
封装
3中修饰符:public,private,protected,给位于同一个或不同包中的对象赋予了不同的访问权限
封装的一些好处
- 通过隐藏对象的属性来保护对象内部的状态
- 提高代码的可用性,可维护性
- 提高模块化
继承
给对象提供从基类获取字段和方法的能力,基础提高代码的重用性,可以在不修改类的情况下添加新的特性
多态
多态就是同一函数在不同类中有不同的实现;
- 面向对象的多态性,即“一个接口,多个方法”。
- 多态性体现在基类中定义的属性和方法被子类继承后,可以具有不同的属性或表现方式。
- 多态性允许一个接口被多个同类使用,弥补了单继承的不足。
final,finally,finalize的区别
final
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个 常量不能被重新赋值。
finally
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码放入finally代码块中,表示不管是 否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
finalize
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调 用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
int和integer的区别
int
int是基本数据类型
integer
integer是其包装类,是一个类
为了在各种类型中转换,通过各种方法调用
int a = 0;
String result = Integer.toString(a);
//将int转换为String
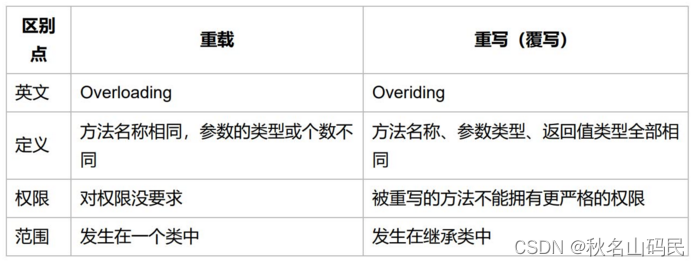
重载与重写的区别
override重写
overload重载
抽象类和接口的区别
接口时公开的,不能有私有的方法和变量,
抽象类可以有私有的方法或私有的变量
抽象类和接口的区别
反射的用途以及实现
反射机制所提供的功能
在运行时创造一个类的对象;
判断一个类所具有的成员变量和方法
调用一个对象的方法
生成动态代理
Java反射的主要功能:
确定一个对象的类
取出类的modifiers,数据成员,方法,构造类,超类
在运行时刻调用动态对象的方法.
创建数组,数组大小和类型
自定义注解的场景及实现
登陆、权限拦截、日志处理,以及各种Java 框架,如Spring,Hibernate,JUnit 提到注解就不能不说反射,Java自定义注解是通过运行时靠反射获取注解。实际开发中,例如我们要获取某个方法的调用日志,可以通过AOP(动态代理机制)给方法添加切面,通过反射来获取方法包含的注解,如果包含日志 注解,就进行日志记录。
http请求的get和post方式的区别
原理区别
一般我们在浏览器输入一个网址访问网站都是GET请求;再FORM表单中,可以通过设置Method指定提交方式为GET或者POST提交方式,默认为GET提交方式。
HTTP定义了与服务器交互的不同方法,其中最基本的四种:GET,POST,PUT,DELETE,HEAD,其中GET和HEAD被称为安全方法,因为使用GET和HEAD的HTTP请求不会产生什么动作。不会产生动作意味着GET和HEAD的HTTP请求不会在服务器上产生任何结果。但是安全方法并不是什么动作都不产生,这里的安全方法仅仅指不会修改信息。
根据HTTP规范,POST可能会修改服务器上的资源的请求。比如CSDN的博客,用户提交一篇文章或者一个读者提交评论是通过POST请求来实现的,因为再提交文章或者评论提交后资源(即某个页面)不同了,或者说资源被修改了,这些便是“不安全方法”。
请求的区别
GET方法会把名值对追加在请求的URL后面。因为URL对字符数目有限制,进而限制了用在 客户端请求的参数值的数目。并且请求中的参数值是可见的,因此,敏感信息不能用这种方式传递。
POST方法通过把请求参数值放在请求体中来克服GET方法的限制,因此,可以发送的参数的数目是没有限制的。最后,通过POST请求传递的敏感信息对外部客户端是不可见的。
seesion与cookie的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上.
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
- 设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
JDBC流程
- 加载JDBC驱动程序:
在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.lang.Class类的静态方法forName(String className)实现。
例如:
try{
//加载MySql的驱动类
Class.forName("com.mysql.jdbc.Driver") ;
}catch(ClassNotFoundException e){
System.out.println("找不到驱动程序类 ,加载驱动失败!");
e.printStackTrace() ;
成功加载后,会将Driver类的实例注册到DriverManager类中。
- 提供JDBC连接的URL
连接URL定义了连接数据库时的协议、子协议、数据源标识。书写形式:协议:子协议:数据源标识
协议:在JDBC中总是以jdbc开始 子协议:是桥连接的驱动程序或是数据库管理系统名称。数据源标识:标记找到数据库来源的地址与连接端口。
例如:
jdbc:mysql://localhost:3306/test? useUnicode=true&characterEncoding=gbk;useUnicode=true;(MySql的连接URL)
表示使用Unicode字符集。如果characterEncoding设置为 gb2312或GBK,本参数必须设置
为true 。characterEncoding=gbk:字符编码方式。 - 创建数据库的连接
java.sql.DriverManager Connection
代表一个数据库的连接。
使用DriverManager的getConnectin(String url , String username , String password )方法传入指定的欲连接的数据库的路径、数据库的用户名和 密码来获得。
例如: //连接MySql数据库,用户名和密码都是root
String url = "jdbc:mysql://localhost:3306/test" ;
String username = "root" ;
String password = "root" ;
try{
Connection con = DriverManager.getConnection(url , username , password
) ;
}catch(SQLException se){
System.out.println("数据库连接失败!");
se.printStackTrace() ;
-
• 要执行SQL语句,必须获得java.sql.Statement实例,Statement实例分为以下3 种类型:
1、执行静态SQL语句。通常通过Statement实例实现。
2、执行动态SQL语句。通常通过PreparedStatement实例实现。
3、执行数据库存储过程。通常通过CallableStatement实例实现。具体的实现方式:
Statement stmt = con.createStatement() ; PreparedStatement pstmt = con.prepareStatement(sql) ; CallableStatement cstmt = con.prepareCall("{CALL demoSp(? , ?)}") ; -
执行SQL语句
Statement接口提供了三种执行SQL语句的方法:executeQuery 、executeUpdate 和execute
1、ResultSet executeQuery(String sqlString):执行查询数据库的SQL语句 ,返回一个结果集(ResultSet)对象。
2、int executeUpdate(String sqlString):用于执行INSERT、UPDATE或 DELETE语句以及SQL DDL语句,如:CREATE TABLE和DROP TABLE等
3、execute(sqlString):用于执行返回多个结果集、多个更新计数或二者组合的 语句。 具体实现的代码:
ResultSet rs = stmt.executeQuery(“SELECT * FROM …”) ; int rows =
stmt.executeUpdate(“INSERT INTO …”) ; boolean flag = stmt.execute(String sql) ; -
处理结果
两种情况:
1、执行更新返回的是本次操作影响到的记录数。
2、执行查询返回的结果是一个ResultSet对象。
• ResultSet包含符合SQL语句中条件的所有行,并且它通过一套get方法提供了对这些 行中数据的访问。
• 使用结果集(ResultSet)对象的访问方法获取数据:
while(rs.next()){
String name = rs.getString(“name”) ;
String pass = rs.getString(1) ; // 此方法比较高效
}
(列是从左到右编号的,并且从列1开始) -
关闭JDBC对象
操作完成以后要把所有使用的JDBC对象全都关闭,以释放JDBC资源,关闭顺序和声 明顺序相反:
1、关闭记录集
2、关闭声明
3、关闭连接对象
if(rs!=null){ // 关闭记录集
try{
rs.close();
}catch(SQLException e){e.printStackTrace();
}
}try{
stmt.close();
}
}catch(SQLException e){e.printStackTrace();
}
if(conn!=null){ // 关闭连接对象
try{
conn.close();
}catch(SQLException e){
e.printStackTrace();20}
}
MVC思想
M:Model 模型
V:View 视图
C:Controller控制器
模型就是封装业务逻辑和数据的一个一个的模块,控制器就是调用这些模块的(java中通常是 用Servlet来实现,框架的话很多是用Struts2来实现这一层),视图就主要是你看到的,比如JSP 等.
当用户发出请求的时候,控制器根据请求来选择要处理的业务逻辑和要选择的数据,再返回去 把结果输出到视图层,这里可能是进行重定向或转发等.
equals 与 == 的区别
值类型(int,char,long,boolean等)都是用==判断相等性。对象引用的话,判断引用所指的对象 是否是同一个。equals是Object的成员函数,有些类会覆盖(override)这个方法,用于判 断对象的等价性。例如String类,两个引用所指向的String都是"abc",但可能出现他们实际对应的对象并不是同一个(和jvm实现方式有关),因此用 ==判断他们可能不相等,但用equals判断一定是相等的。
线程
创建线程的方法及实现
Java中创建线程主要有三种方式:
一、继承Thread类创建线程类
(1) 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2) 创建Thread子类的实例,即创建了线程对象。
(3) 调用线程对象的start()方法来启动该线程。
package com.thread;
public class FirstThreadTest extends Thread{
int i = 0;
//重写run方法,run方法的方法体就是现场执行体public void run()
{
for(;i<100;i++){ System.out.println(getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i< 100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i):
if(i==20)
{
new FirstThreadTest().start();
new FirstThreadTest().start();
}
}
}
二、通过Runnable接口创建线程类
(1) 定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2) 创建 Runnable实现类的实例的target来创建Thread对象,该
Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程
package com.thread;
public class RunnableThreadTest implements Runnable
{
private int i; public void run()
{
for(i = 0;i <100;i++)
{
System.out.println(Thread.currentThread().getName()+"
"+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+"
"+i);
if(i==20)
{
RunnableThreadTest rtt = new RunnableThreadTest();
new Thread(rtt,"新线程1").start();
new Thread(rtt,"新线程2").start();
}
}
}
}
三、通过Callable和Future创建线程
(1) 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2) 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3) 使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4) 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
package com.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableThreadTest implements Callable<Integer> {
public static void main(String[] args) {
CallableThreadTest ctt = new CallableThreadTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
13 for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " 的循 环变量i的值" + i);
if (i == 20) {
new Thread(ft, "有返回值的线程").start();
}
}
try {
System.out.println("子线程的返回值:" + ft.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
@Override
public Integer call() throws Exception 34
{
int i = 0;
for (; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
return i;
}
}
采用实现Runnable、Callable接口的方式创见多线程时,优势是:
线程类只是实现了 接口或 接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同 一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面 向对象的思想。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
使用继承Thread类的方式创建多线程时优势是:
编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this 即可获得当前线程。
劣势是:
线程类已经继承了Thread类,所以不能再继承其他父类。
sleep() 、join()、yield()的区别
一、sleep()
在指定的毫秒数内让当前正在执行的线程休眠(暂停执行),此操作受到系统计时器和调度 程序精度和准确性的影响。 让其他线程有机会继续执行,但它并不释放对象锁。也就是如 果有Synchronized同步块,其他线程仍然不能访问共享数据。注意该方法要捕获异常
比如有两个线程同时执行(没有Synchronized),一个线程优先级为MAX_PRIORITY,另一 个为MIN_PRIORITY,如果没有Sleep()方法,只有高优先级的线程执行完成后,低优先级 的线程才能执行;但当高优先级的线程sleep(5000)后,低优先级就有机会执行了。
总之,sleep()可以使低优先级的线程得到执行的机会,当然也可以让同优先级、高优先级的 线程有执行的机会。
二、join()
Thread的非静态方法join()让一个线程B“加入”到另外一个线程A的尾部。在A执行完毕之前, B不能工作。
保证当前线程停止执行,直到该线程所加入的线程完成为止。然而,如果它加入的线程没有 存活,则当前线程不需要停止。
三、yield()
yield()方法和sleep()方法类似,也不会释放“锁标志”,区别在于,它没有参数,即yield()方 法只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态 后马上又被执行,另外yield()方法只能使同优先级或者高优先级的线程得到执行机会,这也 和sleep()方法不同。
再给大家推荐一本书:Java并发编程想要电子版也可以私信我
线程池的几种方式
newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数 量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程
newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当 需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制
newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会 创建一个新的来替代它;它的特点是能确保依照任务在队列
中的顺序来串行执行
newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
private static final Executor exec=Executors.newFixedThreadPool(50);
Runnable runnable=new Runnable(){
public void run(){
...
}
}
exec.execute(runnable);
Callable<Object> callable=new Callable<Object>() {
public Object call() throws Exception {
return null;
}
}
Future future=executorService.submit(callable);
future.get(); // 等待计算完成后,获取结果
future.isDone(); // 如果任务已完成,则返回 true
future.isCancelled(); // 如果在任务正常完成前将其取消,则返回 true
future.cancel(true); // 试图取消对此任务的执行,true中断运行的任务,false 允许正在运行的任务运行完成
线程的生命周期
新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和死亡(Dead)5种状态
(1)生命周期的五种状态
新建(new Thread)
当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。
例如:Thread t1=new Thread();
就绪(runnable)
线程已经被启动,正在等待被分配给CPU时间片,也就是说此时线程正在就绪队列中排队 等候得到CPU资源。例如:t1.start();
运行(running)
线程获得CPU资源正在执行任务(run()方法),此时除非此线程自动放弃CPU资源或者有 优先级更高的线程进入,线程将一直运行到结束。
死亡(dead)
当线程执行完毕或被其它线程杀死,线程就进入死亡状态,这时线程不可能再进入就绪状态 等待执行。
自然终止:正常运行run()方法后终止
异常终止:调用**stop()**方法让一个线程终止运行
堵塞(blocked)
由于某种原因导致正在运行的线程让出CPU并暂停自己的执行,即进入堵塞状态。
正在睡眠:用sleep(long t) 方法可使线程进入睡眠方式。一个睡眠着的线程在指定的时间过去可进入就绪状态。
正在等待:调用wait()方法。(调用motify()方法回到就绪状态)
被另一个线程所阻塞:调用suspend()方法。(调用resume()方法恢复)
锁机制
线程安全
线程安全是指要控制多个线程对某个资源的有序访问或修改,而在这些线程之间没有产生冲 突。
在Java里,线程安全一般体现在两个方面:
1、多个thread对同一个java实例的访问(read和modify)不会相互干扰,它主要体现在关 键字synchronized。如ArrayList和Vector,HashMap和Hashtable(后者每个方法前都有synchronized关键字)。如果你在interator一个List对象时,其它线程remove一个element, 问题就出现了。
2、每个线程都有自己的字段,而不会在多个线程之间共享。它主要体现在java.lang.ThreadLocal类,而没有Java关键字支持,如像static、transient那样。
volatle实现原理
悲观锁,乐观锁
是一种思想。可以用在很多方面。比如数据库方面。
悲观锁就是for update(锁定查询的行)
乐观锁就是 version字段(比较跟上一次的版本号,如果一样则更新,如果失败则要重复读
比较写的操作。)
JDK方面:
悲观锁就是sync
乐观锁就是原子类(内部使用CAS实现)
本质来说,就是悲观锁认为总会有人抢我的。乐观锁就认为,基本没人抢。
乐观锁是一种思想,即认为读多写少,遇到并发写的可能性比较低,所以采取在写时先读出 当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重 复读比较写的操作。
CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。CAS顶多算是乐观锁写那一步操作的一种实现方式罢了,不用CAS自己加锁也是可以的。
乐观锁的业务场景及实现方式
每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁, 但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不 进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁, 期间该数据可以被其他线程进行读写操作。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可 能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量 的查询操作,降低了系统的吞吐量。
最后
都看到这了,给孩子一个三连支持一下吧,
Java对初学者很友好;
Java资源丰富,因为它可以解决不同的问题;
Java有一个庞大而友好的社区;
Java无处不在,因此更容易找到第一份工作;
Java开发人员缺口大,薪水很高。
只要你具备能力,薪资待遇你敢要公司就敢给。

- 点赞
- 收藏
- 关注作者
评论(0)