ZooKeeper源码阅读心得分享+源码基本结构+源码环境搭建

一、心得分享
如何阅读ZooKeeper源码?从哪里开始阅读?最近把ZooKeeper源码看了个大概,有一些心得想和大家分享和探讨:
1、寻找迷宫入口
ZooKeeper源码的脉络就像一个迷宫,要想玩这个迷宫游戏,必须找到迷宫的入口。有两条入口可供选择:
- 从服务端的启动流程开始看起,可以了解配置文件
zoo.cfg解析过程和配置项在源码中的应用,以及Leader选举流程等。服务端源码比较复杂,在了解服务端启动和Leader选举的过程中,又涉及很多其他知识点,包括内存数据库DataTree的原理,日志机制(事务日志和快照日志),数据恢复与同步等。最接近核心,也最难,容易劝退或者举步维艰。 - 从客户端向服务端建立连接开始看起,可以了解客户端是如何建立连接、发送请求和处理响应等,相对于服务端,客户端源码要简单很多。从客户端开始突破,要顺利些。
2、画流程图
看源码一定要画流程图。源码走向是错综复杂,每个流程、每个走向都画好流程图或者时序图,有助于原理理解。
客户端源码只有两个线程还好说,服务端源码有很多线程,直接绕晕。比如请求处理,就分为事务请求和非事务请求,事务请求又需要经过两阶段提交,不画流程图,根本梳理不清事务请求是如何在Leader和Learner之间流转的。
3、任务分解
任务拆分,化繁为简,化整为零,是大家都懂的道理,但是如何拆分并不是一件易事。
Zookeeper源码有很多大知识点,攻克大知识点很花时间,有时候会因为太难,而一拖再拖,举步维艰。将大知识点拆分为一个个小知识点,一步步攻克。拆分的过程不是一步到位,不要纠结于如何拆分,而是先拆起来,进行的过程中不断拆分,不知不觉一个大的,难的知识点就被攻克了。
4、思维导图
看完源码,总结是非常重要的。将一个知识点扩展成一个思维导图,每一个分支都是最精华的总结,这样会更加印象深刻。
二、源码基本结构
ZooKeeper源码分为客户端源码和服务端源码。
1、客户端源码

客户端源码从一行初始化代码开始:
String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
ZooKeeper zooKeeper = new ZooKeeper(connectString, 20000, null);
初始化一个ZooKeeper实例,初始化过程会解析connectString,并随机挑选一个服务器地址建立长连接。
(1)ClientCnxn客户端连接抽象
ClientCnxn是对客户端连接的抽象和封装,负责连接管理和watcher管理。有两个核心线程:
- 负责与服务端建立连接和通信的
SendThread线程。 - 负责处理
watcher远程回调和本地事件回调的EventThread线程。
在客户端实例ZooKeeper初始化时,会初始化并启动ClientCnxn,启动ClientCnxn就是启动SendThread和EventThread两个线程。
(2)SendThread
SendThread线程主要负责与服务端建立长链接,后续的 getData、setData 等操作都通过SendThread线程与服务端通信。
SendThread的核心知识点有:
-
向服务端建立连接的过程
-
建立会话的过程
-
心跳机制保证长链接存活
-
读写IO处理
负责底层网络建立连接和I/O处理的是ClientCnxnSocket ,实现类有 ClientCnxnSocketNIO 和 ClientCnxnSocketNetty。
(3)EventThread
SendThread接收到服务端的 watcher 通知后,会交由EventThread线程去触发回调。注册watcher的功能只有非事务请求(getData、exists、getChildren)才有,而事务请求,如getData可以注册本地事件,事务请求响应成功后会触发本地事件回调,这里的回调流程也是在EventThread线程中。
(4)getData非事务请求
非事务请求不仅仅有getData,但流程都差不多。
getData可以注册watcher,但是如何注册,并且是如何远程向服务端注册?其实注册 watcher 只是向服务端发送一个是否注册watcher的布尔值,具体注册什么事件不会在注册时声明,而是在触发时判断。
getData构建好请求体和响应体,并提交给SendThread线程进行底层网络的异步发送,因为是异步,所以有两种方式接收响应:
- 同步阻塞,
getData将请求提交给SendThread之后就会阻塞,直到响应到来唤醒。 - 异步回调,
getData可以传入一个本地回调事件,等响应到了就会交由EventThread线程进行回调。
(5)setData事务请求
事务请求也并非只有setData,还有create、delete。其实事务请求和非事务请求在客户端差别不大,也就是事务请求不能注册watcher,请求发送也是异步,所以响应处理也有两种,同步阻塞和异步回调。
无论是事务请求还是非事务请求,响应都是需要按顺序处理。
2、服务端源码

服务端源码较为复杂,突破口在启动流程上。在服务端启动的过程中,涉及到的知识点:
- 配置文件解析和配置项在源码中应用。
- 读取日志文件恢复内存数据库。
- 监听和接收客户端连接。
- Leader选举。
- Leader和Learner之间差异化数据同步。
- … …
(1)配置解析
将配置文件zoo.cfg加载为一个java.util.Properties对象,然后解析映射到QuorumPeerConfig对象中,再将QuorumPeerConfig的变量设置给QuorumPeer对象,QuorumPeer就是ZAB协议的具体实现类。
(2)恢复内存数据库
在服务端启动时,需要通过读取日志文件恢复内存数据库。首先读取快照日志文件反序列化出一棵DataTree,然后再读取事务日志文件修补增量数据。这只是初步恢复,等Leader选举完成以后,服务节点之间还需要进行差异化数据同步。
(3)监听客户端连接
在配置文件zoo.cfg中指定的clientPort就是用来监听客户端连接的。客户端连接监听是常规的Reactor响应式线程模型。一个AcceptThread线程监听连接事件,多个SelectorThread轮询封装注册连接,具体网络IO事件处理交给一个线程池。
AcceptThread线程接收到来自客户端连接后,轮询选择一个SelectorThread来处理连接;每一个客户端连接在服务端都被抽象化成一个ServerCnxn对象,默认实现类为NIOServerCnxn,负责底层网络IO处理;具体的IO读写事件处理抽象成一个IOWorkRequest任务对象交给线程池workerPool异步处理。
无论是事务请求还是非事务请求从底层网络读取完数据并构建好请求体后,都会提交给一个节流阀线程RequestThrottler,RequestThrottler控制请求量,并将请求提交给一个包含多个处理器RequestProcessor的职责链处理。

(4)Leader选举
在配置文件中,有几行这样格式的配置:
server.A=B:C:D
- A是一个数字,表示每个zk实例的
myid文件中的编号,即SID。 - B是ip地址,每个zk实例所在机器ip。
- C是集群中
Leader和Learner通信的端口。 - D是集群中用于
Leader选举同步票据的端口。
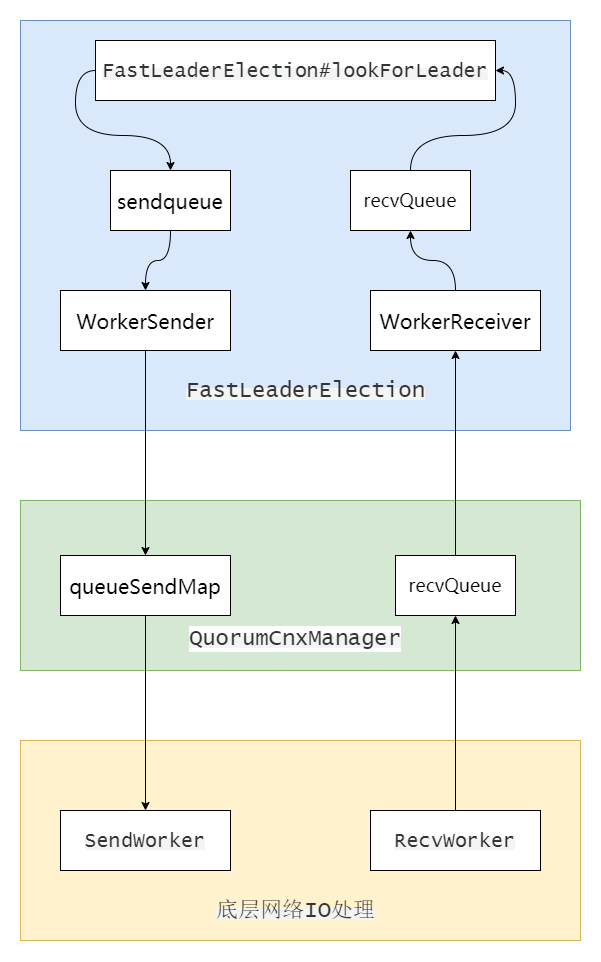
首先创建一个或者一组线程用于监听投票端口,然后创建一个快速选举Leader算法FastLeaderElection,并启动两个线程WorkerSender和WorkerReceiver分别用于选票发送和选票接收。
在交换选票前,服务节点间互相建立连接,为避免连接重复建立,只有SID较大的服务器才可以主动向其他服务器发起建立连接请求。建立连接后,会为每个连接创建两个线程SendWorker和RecvWorker分别用于网络底层的IO事件处理。
FastLeaderElection#lookForLeader是Leader选举的核心实现,包括将选票广播给所有其他服务,处理其他服务同步过来的选票,选票PK,最终选出Leader,完成选票。
(5)数据差异化同步
数据差异化同步发生在Leader选举完成之后。Learner服务器(Follower和Observer)需要向Leader服务器发起建立连接请求,Leader启动LearnerCnxAcceptor线程监听Learner的连接请求,每一个建立的连接会被抽象成一个LearnerHandler对象。
Leader检测到有过半数的Follower(Observer不参与过半数决策)建立连接后,就开始校对Learner的数据与自己的数据有哪些差异:
- 如果
Learner少了数据,Leader就会发送缺少的数据给Learner; - 如果
Learner多出数据,Leader就会让Learner回滚到指定位置; - 实在差异太大,就全量同步。
(6)事务日志和快照日志
在服务器正常运行的过程,查询数据都是直接从内存数据库中获取,所以响应速度很快,但是为了服务重启后数据还在,才有了将数据持久化到磁盘日志文件中。
每条事务请求都会先落地到事务日志文件,再提交到内存数据库中。经过一定事务请求次数,还会将整个内存数据库持久化成一个快照日志文件。一个快照日志文件和其后生成的事务日志文件共同组成全局数据。
FileTxnLog是事务日志文件持久化实现类,主要封装对磁盘文件的追加、读取、截断、滚动等操作。
FileSnap是快照日志文件持久化实现类,主要封装两个操作:将DataTree和会话列表序列化到磁盘文件和读取磁盘文件反序列化出DataTree和会话列表。
FileTxnSnapLog是对FileTxnLog和FileSnap整合,方便调用。
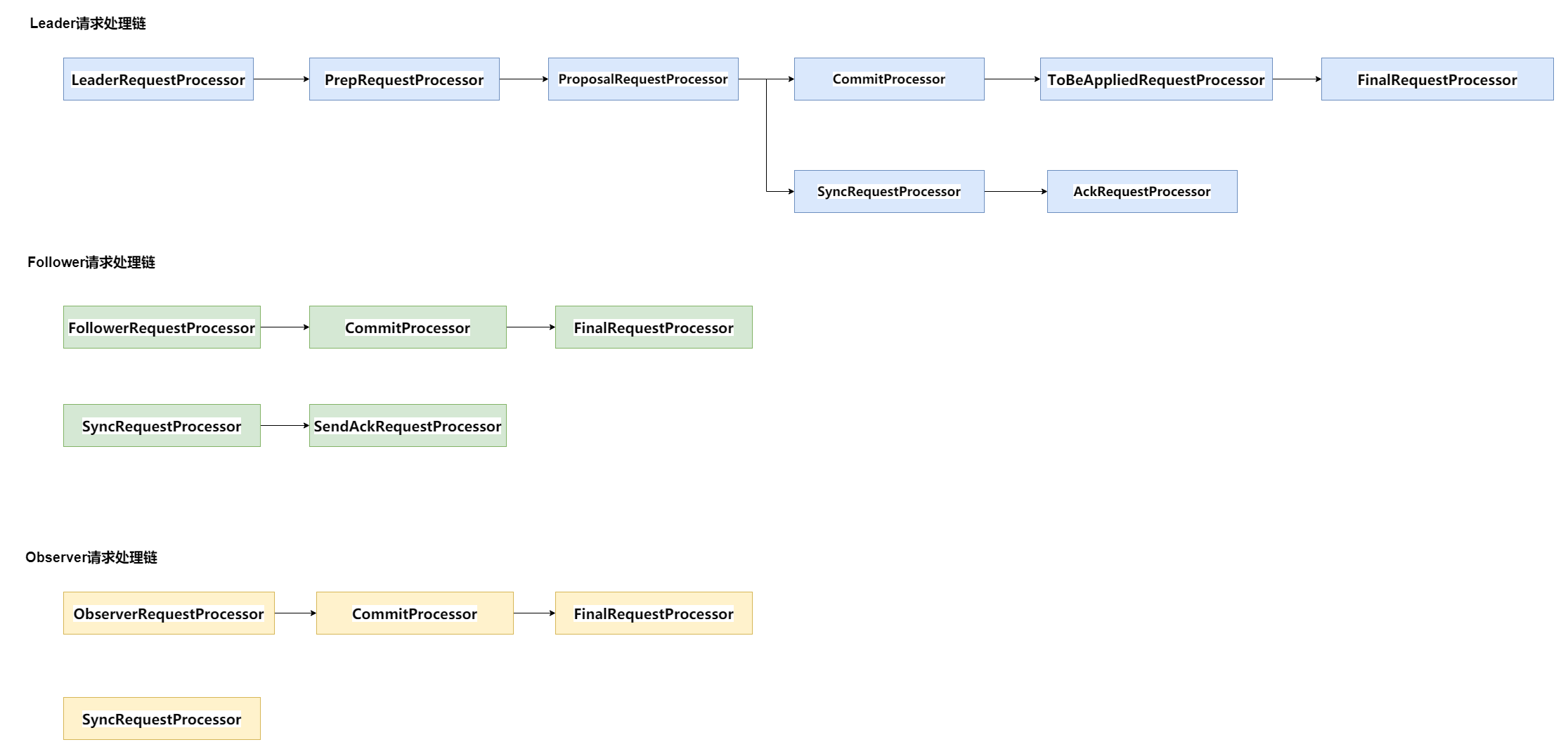
(7)事务请求流程
事务请求和非事务请求都会经过一个职责链处理,不同的是,事务请求需要经过两阶段提交,而非事务请求不需要。
两阶段提交只能由Leader发起提案和进行提交操作,所以Follower和Observer接收到事务请求必须先转发给Leader,由Leader发起两阶段提交。
服务节点有三种类型Leader、Follower、Observer,所以有三条请求处理的职责链,其中个别处理器相同。
比如三条处理链最后都有一个FinalRequestProcessor来处理响应或者将请求应用到内存数据库;Follower和Observer首个处理器都是将事务请求转发给 Leader;Observer没有投票权,不参与两阶段决策,所以没有响应Leader的ACK处理器。
(8)会话管理
客户端与服务端建立连接后,紧接着必须建立会话,之后所有通信都要在会话有效的基础上进行。会话建立也是事务请求,sessionID的创建和会话超时时间协商由当前服务实例完成,但是会话管理包括会话超时检查、清理、激活等都必须交由Leader负责。
客户端发向服务端的请求,无论是正常请求还是心跳都会重新激活会话,即重置会话超时时间。而Learner没有激活会话的权限,只有在Leader向Learner发送心跳,Learner响应心跳时,将需要激活的会话发给Leader,由Leader激活会话。

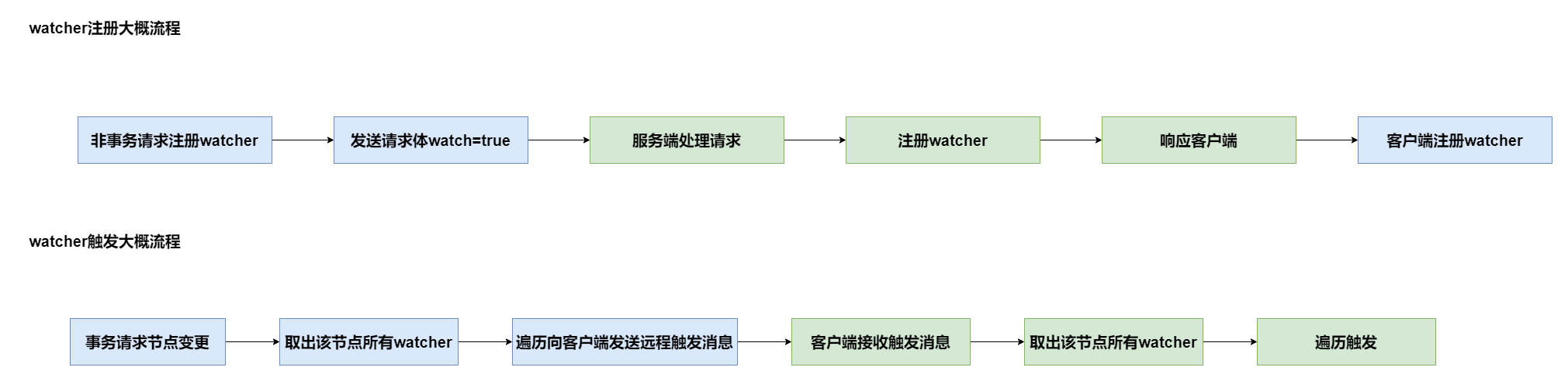
(9)watcher注册与触发
watcher 注册是非事务请求特有的。客户端并不会将 watcher 的详细信息发送给服务器,而是只发送一个是否注册watcher 的布尔值。
服务器在处理请求时检测到请求体里的watch=true,就在内存数据库里注册一个watcher;数据发生变更,就取出该节点上注册的所有watcher,进行触发,触发的动作由服务端传递给客户端;客户端也保存了节点和watcher的关系,客户端从内存中取出该节点的所有watcher,一个个触发,触发的过程中判断是发生了什么事件,如节点创建、节点内容变更、节点删除等。
三、源码环境搭建
1、IDEA导入源码
从 github下拉ZooKeeper源码最新稳定版https://github.com/apache/zookeeper,为了和当时看源码时的版本一致,这里选择 release-3.7.0:
git clone -b release-3.7.0 git@github.com:apache/zookeeper.git
源码导入IDEA即可。org.apache.zookeeper.proto和org.apache.zookeeper.data等包下的类会出现异常:
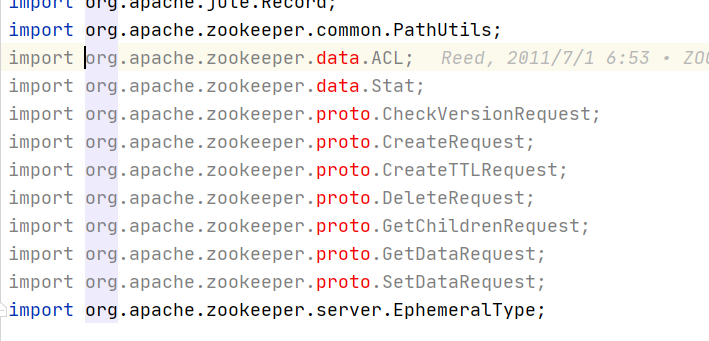
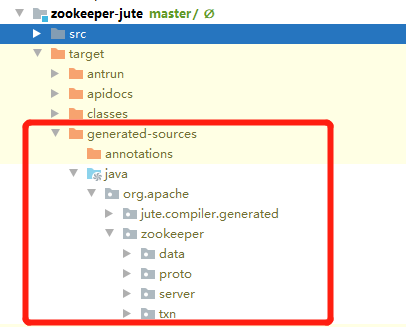
这是因为这些包的源码不是现成的,需要通过编译Jute模块自动生成。生成的代码路径如下:
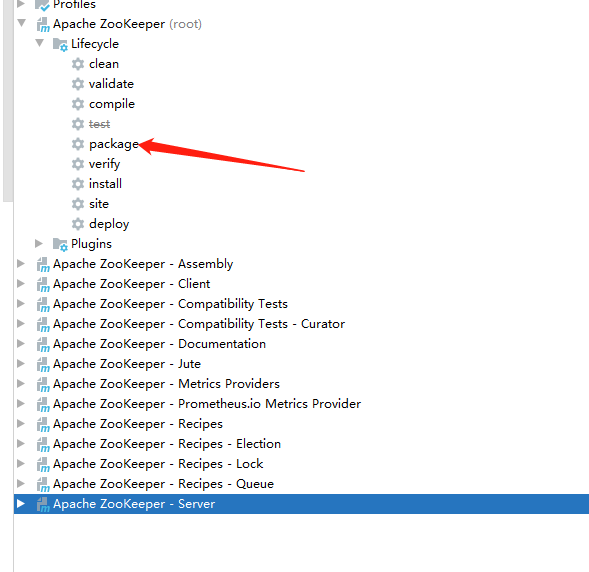
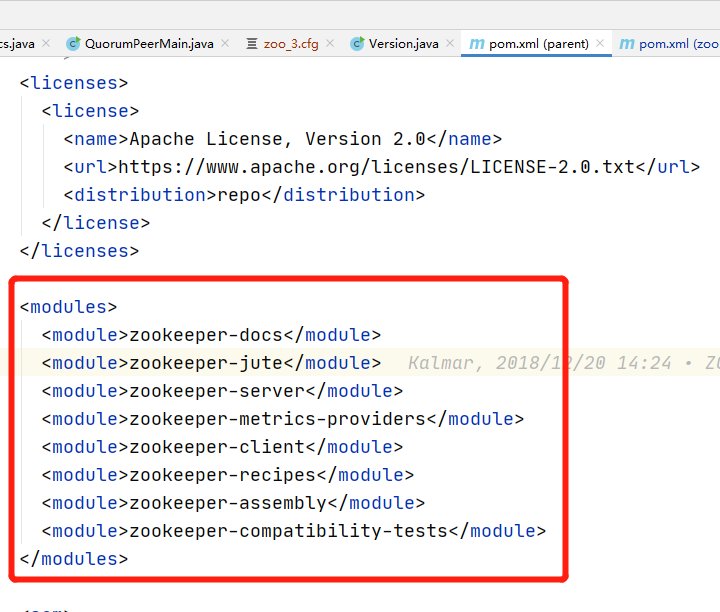
也可以一劳永逸,直接编译root项目,这样就会编译所有模块了。
2、本地运行
root项目编译成功后,就可以像搭建伪集群一样本地运行源码了。
(1)伪集群搭建准备
如果不知道伪集群搭建需要准备哪些东西,请参考《分布式系统的基石之ZooKeeper——基本原理+场景应用+集群搭建(最强万字入门指南)》。
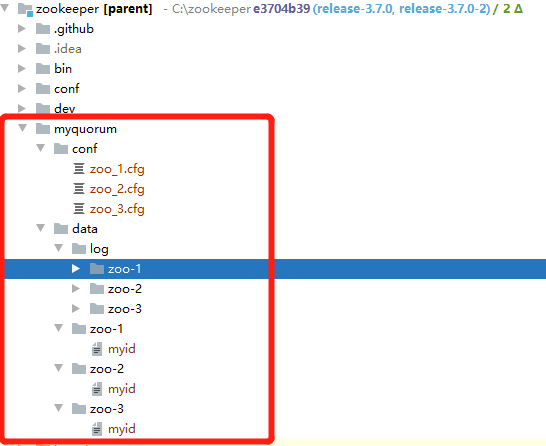
分别创建三个Application,Program arguments 指定配置文件路径,Main class有两种,一种是单体模式ZooKeeperServerMain,一种是集群模式QuorumPeerMain,这里选择QuorumPeerMain。
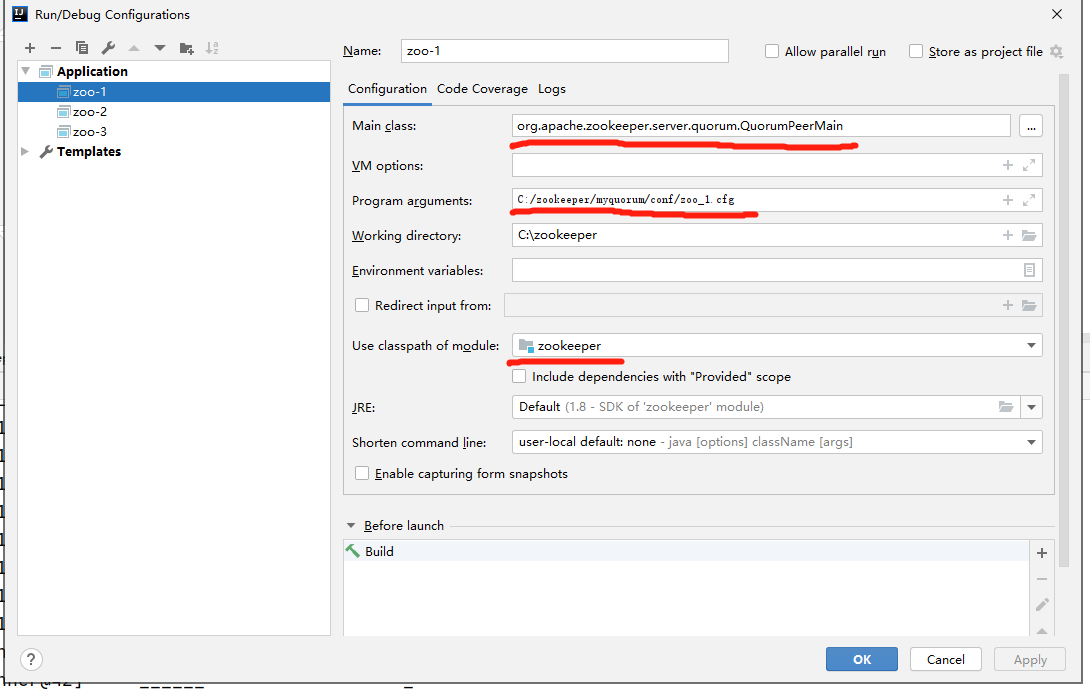
(2)运行
分别启动zoo-1、zoo-2、zoo-3。可能会出现某些类找不到的情况:
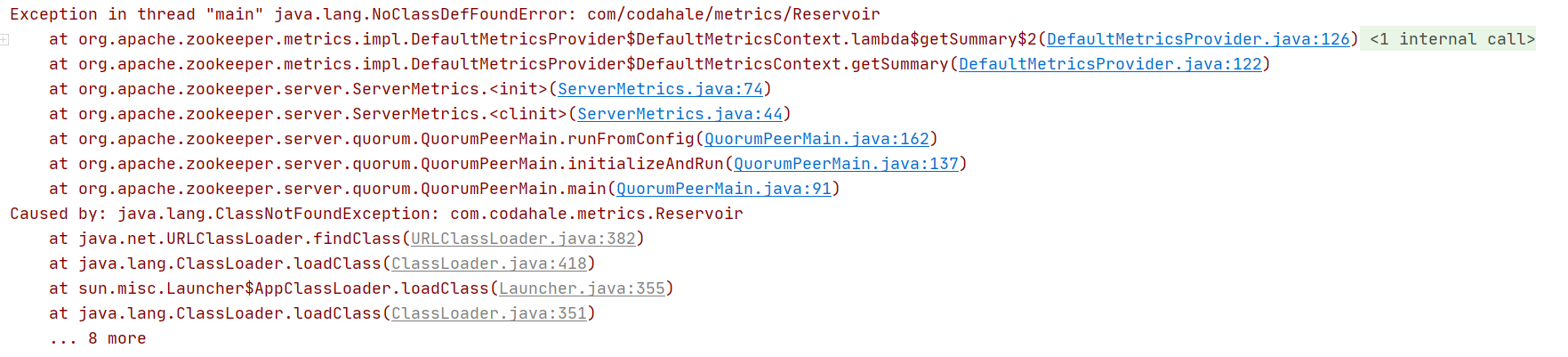
这是因为zookeeper-server模块的pom.xml文件部分依赖的scope是provided的,只有编译和测试环境中依赖才起作用,想在运行时也起作用,可以将provided改为compile,或者去掉scope,因为默认scope是compile,编译,运行,测试环境依赖都起作用。
修改完zookeeper-server模块的pom.xml文件后重新编译就可以了。
如果运行的过程中控制台没有打印日志,首先查看zookeeper-server/src/main/resources路径下是否有log4j.properties文件,如果没有,就把conf目录下的log4j.properties复制过来。同时指定zookeeper-server/src/main/resources为Resources目录才会生效。
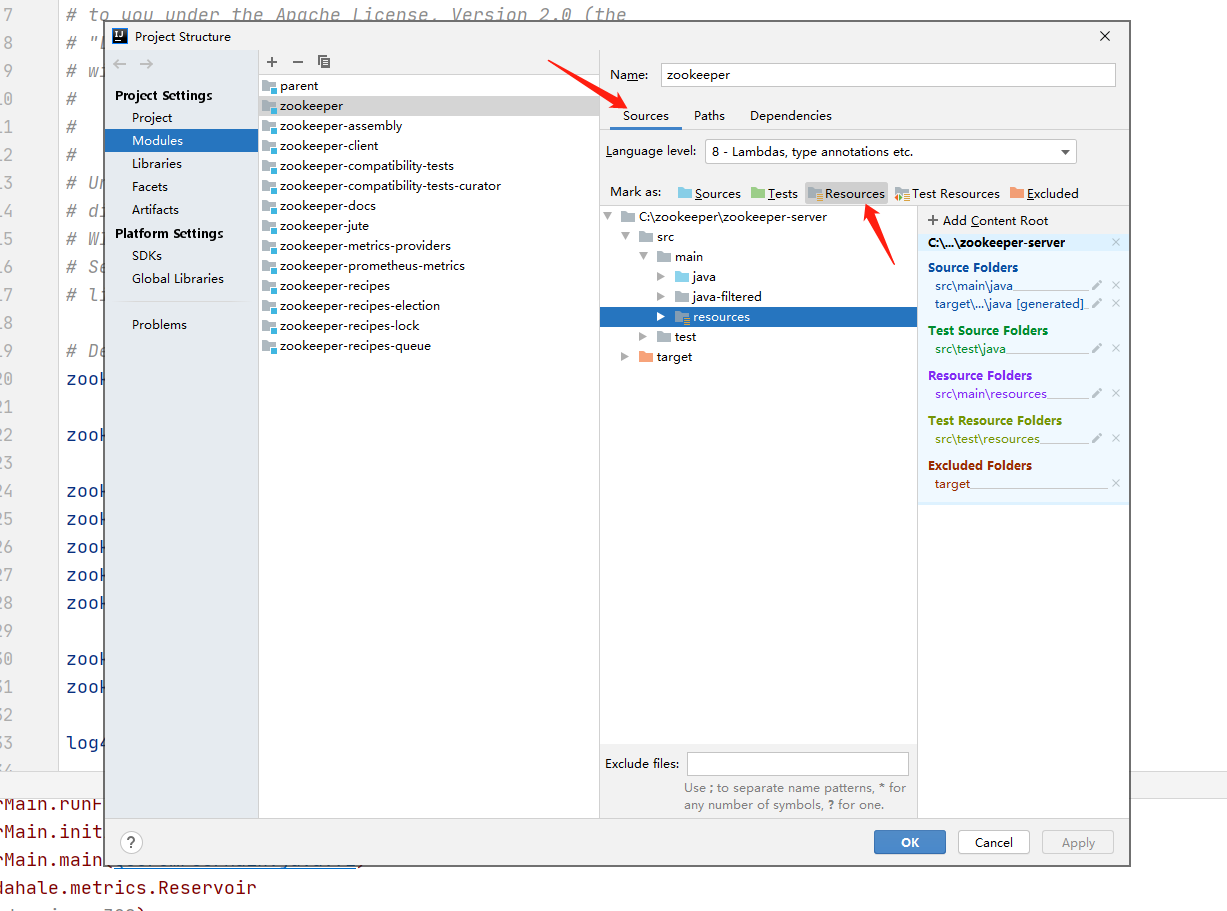
如此这般就可以运行了:

在本地运行源码的好处就是可以debug,debug对于阅读源码,理解一些流程非常有帮助。
ZooKeeper源码注释:https://github.com/stefanxfy/ZooKeeperLearning
如若文章有错误理解,欢迎批评指正,同时非常期待你的评论、点赞和收藏。
如果想了解更多优质文章,和我更密切的学习交流,请关注如下同名公众号【徐同学呀】,期待你的加入。

- 点赞
- 收藏
- 关注作者
评论(0)