NLP:Transformer的简介(优缺点)、架构详解之详细攻略

NLP:Transformer的简介(优缺点)、架构详解之详细攻略
目录
2、Transformer 结构—纯用attention搭建的模型→计算速度更快
Transformer的简介(优缺点)、架构详解之详细攻略
1、Transformer的简介

自 2017 年 Transformer 技术出现以来,便在 NLP、CV、语音、生物、化学等领域引起了诸多进展。
Transformer模型由Google在2017年在 Attention Is All You Need[1] 中提出。该文使用 Attention 替换了原先Seq2Seq模型中的循环结构,给自然语言处理(NLP)领域带来极大震动。随着研究的推进,Transformer 等相关技术也逐渐由 NLP 流向其他领域,例如计算机视觉(CV)、语音、生物、化学等。

因此,我们希望能通过此文盘点 Transformer 的基本架构,分析其优劣,并对近年来其在诸多领域的应用趋势进行梳理,希望这些工作能够给其他学科提供有益的借鉴。
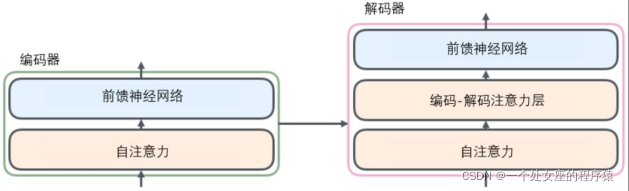
本节介绍 Transformer 基本知识。限于篇幅,在这篇推文中,我们先介绍 Transformer 的基本知识,以及其在 NLP 领域的研究进展;后续我们将介绍 Transformer 在其他领域(CV、语音、生物、化学等)中的应用进展。
(1)、Transforme的四4个优点和2个缺点
(1) 每层计算复杂度更优:Total computational complexity per layer,时间复杂度优于R、C等。

(2) 可直接计算点乘结果:作者用最小的序列化运算来测量可以被并行化的计算。也就是说对于某个序列x1,x2……xn ,self-attention可以直接计算xixj的点乘结果,而RNN就必须按照顺序从 x1计算到xn。
(3) 一步计算解决长时依赖问题:这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量。
(4) 模型更可解释:self-attention模型更可解释,attention结果的分布表明了该模型学习到了一些语法和语义信息。
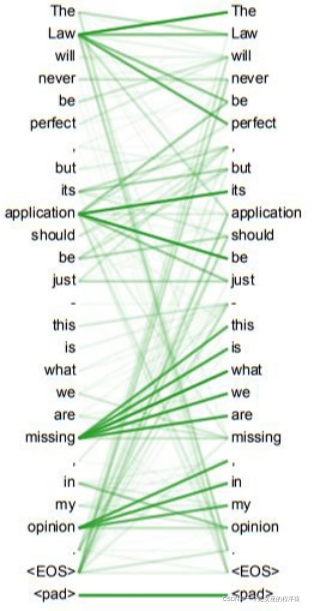
实践上:有些RNN轻易可以解决的问题,transformer没做到,比如复制string,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)。
理论上:transformers非computationally universal(图灵完备),(我认为)因为无法实现“while”循环。
2、Transformer 结构—纯用attention搭建的模型→计算速度更快
更新……
文章来源: yunyaniu.blog.csdn.net,作者:一个处女座的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:yunyaniu.blog.csdn.net/article/details/123172991

- 点赞
- 收藏
- 关注作者
评论(0)