Oracle 数据怎么实时同步到 Kafka | 亲测干货分享建议收藏

摘要:
很多 DBA 同学经常会遇到要从一个数据库实时同步到另一个数据库的问题,同构数据还相对容易,遇上异构数据、表多、数据量大等情况就难以同步。我自己亲测了一种方式,可以非常方便地完成 Oracle 数据实时同步到 Kafka,跟大家分享一下,希望对你有帮助。
Oracle 数据实时同步到 Kafka ,目前支持的工具还比较少,一款免费的数据同步工具 是支持的。跟前面分享到的其他数据库同步的操作方式类似。
第一步:配置 Oracle 连接
1. 点击 Tapdata Cloud 操作后台左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择Oracle

![]()
2. 在打开的连接信息配置页面依次输入需要的配置信息

![]()
【连 接 名 称】:设置连接的名称,多个连接的名称不能重复
【数据库地址】:数据库 IP / Host
【端 口】:数据库端口
【数据库名称】:tapdata 数据库连接是以一个 db 为一个数据源。这里的 db 是指一个数据库实例中的 database,而不是一个 schema。
【账 号】:可以访问数据库的账号
【密 码】:数据库账号对应的密码
【时 间 时 区】:默认使用该数据库的时区;若指定时区,则使用指定后的时区设置
第二步:配置 Kafka 连接
3. 同第一步操作,点击左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择 Kafka
![]()
4.在打开的连接信息配置页面依次输入需要的配置信息,配置完成后测试连接保存即可。
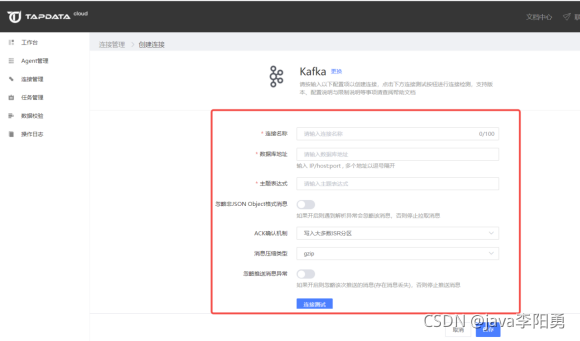
![]()
第三步:选择同步模式-全量/增量/全+增
进入Tapdata Cloud 操作后台任务管理页面,点击添加任务按钮进入任务设置流程

![]()
根据刚才建好的连接,选定源端与目标端。

![]()
根据数据需求,选择需要同步的库、表,如果你对表名有修改需要,可以通过页面中的表名批量修改功能对目标端的表名进行批量设置.

![]()
在以上选项设置完毕后,下一步选择同步类型,平台提供全量同步、增量同步、全量+增量同步,设定写入模式和读取数量。
如果选择的是全量+增量同步,在全量任务执行完毕后,Tapdata Agent 会自动进入增量同步状态。在该状态中,Tapdata Agent 会持续监听源端的数据变化(包括:写入、更新、删除),并实时的将这些数据变化写入目标端。

![]()
点击任务监控可以打开任务执行详情页面,可以查看任务执行的具体信息。

![]()
第四部:进行数据校验
一般同步完成后,我都习惯性进行一下数据校验,防止踩坑。
有三种校验模式,我常用最快的快速count校验 ,只需要选择到要校验的表,不用设置其他复杂的参数和条件,简单方便。

![]()
如果觉得不够用,也可以选择表全字段值校验 ,这个除了要选择待校验表外,还需要针对每一个表设置索引字段。

![]()
在进行表全字段值校验时,还支持进行高级校验。通过高级校验可以添加JS校验逻辑,可以对源和目标的数据进行校验。

![]()
还有一个校验方式关联字段值校验 ,创建关联字段值校验时,除了要选择待校验表外,还需要针对每一个表设置索引字段。

![]()
以上就是 Oracle 数据实时同步到 Kafka 的操作分享,希望上面的操作分享对你有帮助!码字不易,转载请注明出处~
其他数据库的同步操作
其他数据库实时同步到 PostgreSQL、MongoDB、DM DB 达梦数据库、SQL Server、Elasticsearch 、MySQL、Kafka 的方式也都是先配置源和目标的连接,然后新建任务选择同步模式:全量/增量/全量+增量,因为步骤相同,其他就不再贴图说明了。创建连接的时候,有没有发现:DB2、Sybase、Gbase 几个数据库现在是灰色锁定状态,应该是在开发中了,可能后续也会支持这些数据库的同步功能。
打卡 文章 更新 35 / 100天
大家可以点赞、收藏、关注、评论我啦 、有数据库相关的问题随时联系我或交流哟~!

![]()

- 点赞
- 收藏
- 关注作者
评论(0)