[hadoop3.x系列]Hadoop常用文件存储格式及BigData File Viewer工具的使用(三)

前言
目前博客Hadoop文章大都停留在Hadoop2.x阶段,本系列对2.x没有的新特性进行补充更新,一键三连加关注,下次不迷路!
历史文章
[hadoop3.x系列]HDFS REST HTTP API的使用(一)WebHDFS
[hadoop3.x系列]HDFS REST HTTP API的使用(二)HttpFS
🍑Hadoop常用文件存储格式
传统系统常见文件存储格式
在Windows有很多种文件格式,例如:JPEG文件用来存储图片、MP3文件用来存储音乐、DOC文件用来存储WORD文档。每一种文件存储某一类的数据,例如:我们不会用文本来存储音乐、不会用文本来存储图片。windows上支持的存储格式是非常的多。

文件系统块大小
l 在服务器/电脑上,有多种块设备(Block Device),例如:硬盘、CDROM、软盘等等。
l 每个文件系统都需要将一个分区拆分为多个块,用来存储文件。不同的文件系统块大小不同。
[root@node1 ~]# stat -f . File: “.” ID: fd0000000000 Namelen: 255 Type: xfsBlock size: 4096 Fundamental block size: 4096Blocks: Total: 15144730 Free: 11924333 Available: 11924333Inodes: Total: 30304256 Free: 30139006
例如:我们看到该文件系统的块大小为:4096字节 = 4KB。如果我们需要在磁盘中存储5个字节的数据,也会占据4096字节的空间。
Hadoop中文件存储格式
接下来,我们要讲解的是在Hadoop中的数据存储格式。Hadoop上的文件存储格式,肯定不会像Windows这么丰富,因为目前我们用Hadoop来存储、处理数据。我们不会用Hadoop来听歌、看电影、或者打游戏。J

l 文件格式是定义数据文件系统中存储的一种方式,可以在文件中存储各种数据结构,特别是Row、Map,数组以及字符串,数字等。
l 在Hadoop中,没有默认的文件格式,格式的选择取决于其用途。而选择一种优秀、适合的数据存储格式是非常重要的。
l 后续我们要学习的,使用HDFS的应用程序(例如MapReduce或Spark)性能中的最大问题、瓶颈是在特定位置查找数据的时间和写入到另一个位置的时间,而且管理大量数据的处理和存储也很复杂(例如:数据的格式会不断变化,原来一行有12列,后面要存储20列)。
l Hadoop文件格式发展了好一段时间,这些文件存储格式可以解决大部分问题。我们在开发大数据中,选择合适的文件格式可能会带来一些明显的好处:
-
可以保证写入的速度
-
可以保证读取的速度
-
文件是可被切分的
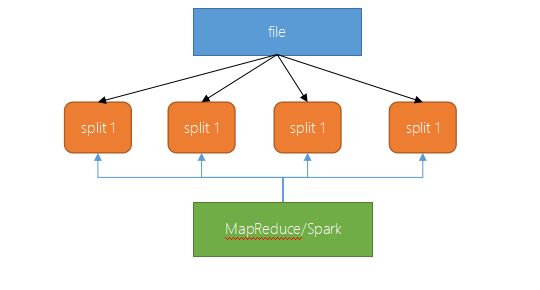
-
对压缩支持友好
-
支持schema的更改
l 某些文件格式是为通用设计的(如MapReduce或Spark),而其他文件则是针对更特定的场景,有些在设计时考虑了特定的数据特征。因此,确实有很多选择。
每种格式都有优点和缺点,数据处理的不同阶段可以使用不同的格式才会更有效率。通过选择一种格式,最大程度地发挥该存储格式的优势,最小化劣势。
🍑 BigData File Viewer工具
介绍
l 一个跨平台(Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如Parquet,ORC,AVRO等。支持本地文件系统,HDFS,AWS S3等。
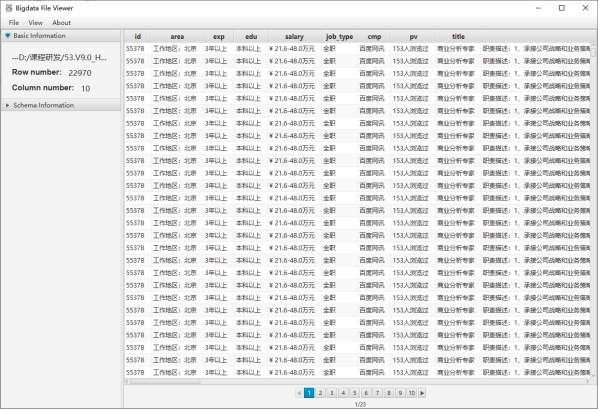
github地址:https://github.com/Eugene-Mark/bigdata-file-viewer
功能清单
l 打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等。
l 将二进制格式的数据转换为文本格式的数据,例如CSV
l 支持复杂的数据类型,例如数组,映射,结构等
l 支持Windows,MAC和Linux等多种平台
式的数据,例如CSV
l 支持复杂的数据类型,例如数组,映射,结构等
l 支持Windows,MAC和Linux等多种平台
l 代码可扩展以涉及其他数据格式
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 manor 原创,首发于 CSDN博客🙉

- 点赞
- 收藏
- 关注作者
评论(0)