【组队学习】Task02:学习Attention和Transformer

@TOC
组队学习资料:
datawhale8月组队学习
-基于transformers的自然语言处理(NLP)入门
Task02主要学习内容:
2.1-图解attention.md
2.2-图解transformer.md
声明:NLP纯小白,本文内容主要是作为个人学习笔记,可能很多地方我自己理解也不是很到位,仅供参考,有争议的话可以多查点儿其他资料,并请评论区留言指正!谢谢
学习建议
对于我这种小白来说,应该以2.2transformer为主,2.1attention作为补充知识,一开始先看2.1完全不知道在讲什么,看完2.2再回过来看2.1很多就通了,所以一开始我觉得顺序错了,看到后面发现不应该有顺序,2.1应该是对2.2的补充说明。总的来说还是先看2.2的transformer更好理解些。
另外建议提前了解下word2vec,RNN
一、Transformer概述
前面有提到attention是对transformer的补充解释,所以笔记以介绍Transformer为主,attention作为补充知识穿插
1.1、transformer是干什么的
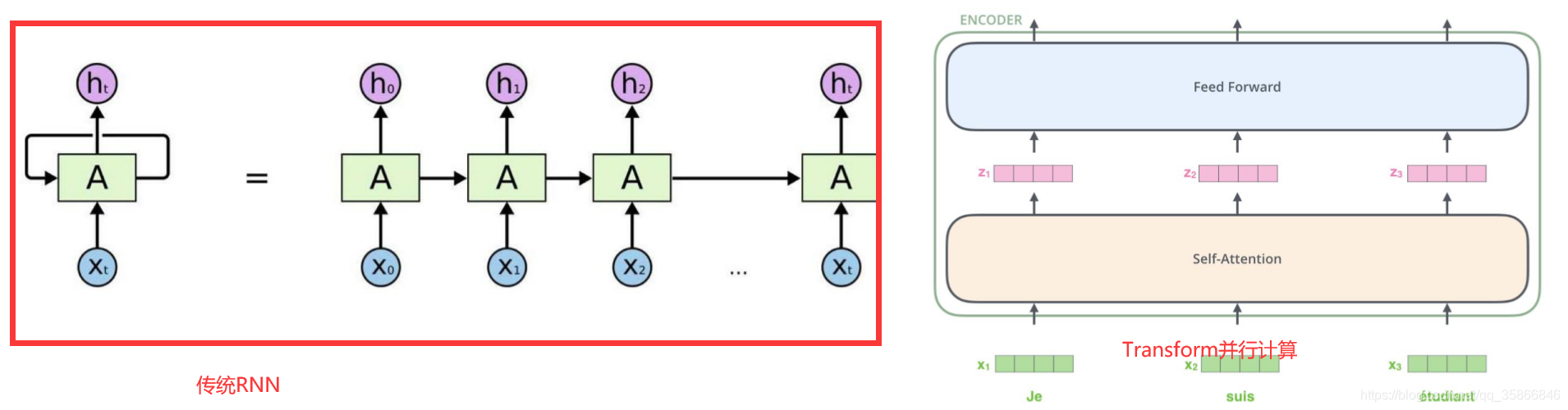
1.1.1相对于传统RNN网络结构一种加强

如上图所示:transformer作为一种网络结构取代了传统seq2seq中的RNN模型,解决了并行计算的问题,为模型训练提供了加速能力
用来并行计算的机制主要是Self.attention机制,为了区分一句话中的侧重点信息,即赋予每个单词不同权重,相比较于传统RNN模型多考虑了位置序列信息
1.1.2 相对于传统word2vec的区别
传统的word2vec:
- 训练好的词向量是静态的,固定不变的,同词同向量
Transform:
- 动态变化的词向量,结合不同的上下文,同一个词的词向量可能是不同的
1.1.3transform的整体架构
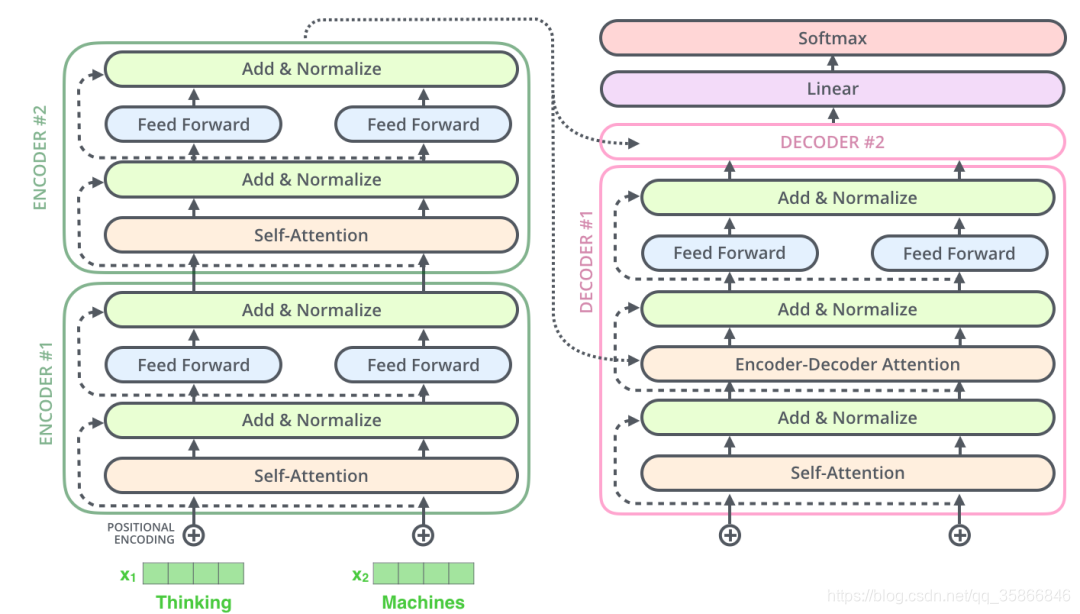
学习目标 | transform需要做什么?
- 输入如何编码
- 输出结果是什么
- Attention的目的
- 怎么组合
二 Self.attention机制
2.1、Attention什么意思
- 对于输入数据,你的关注点是什么
- 如何才能让计算机关注到这些有价值的信息
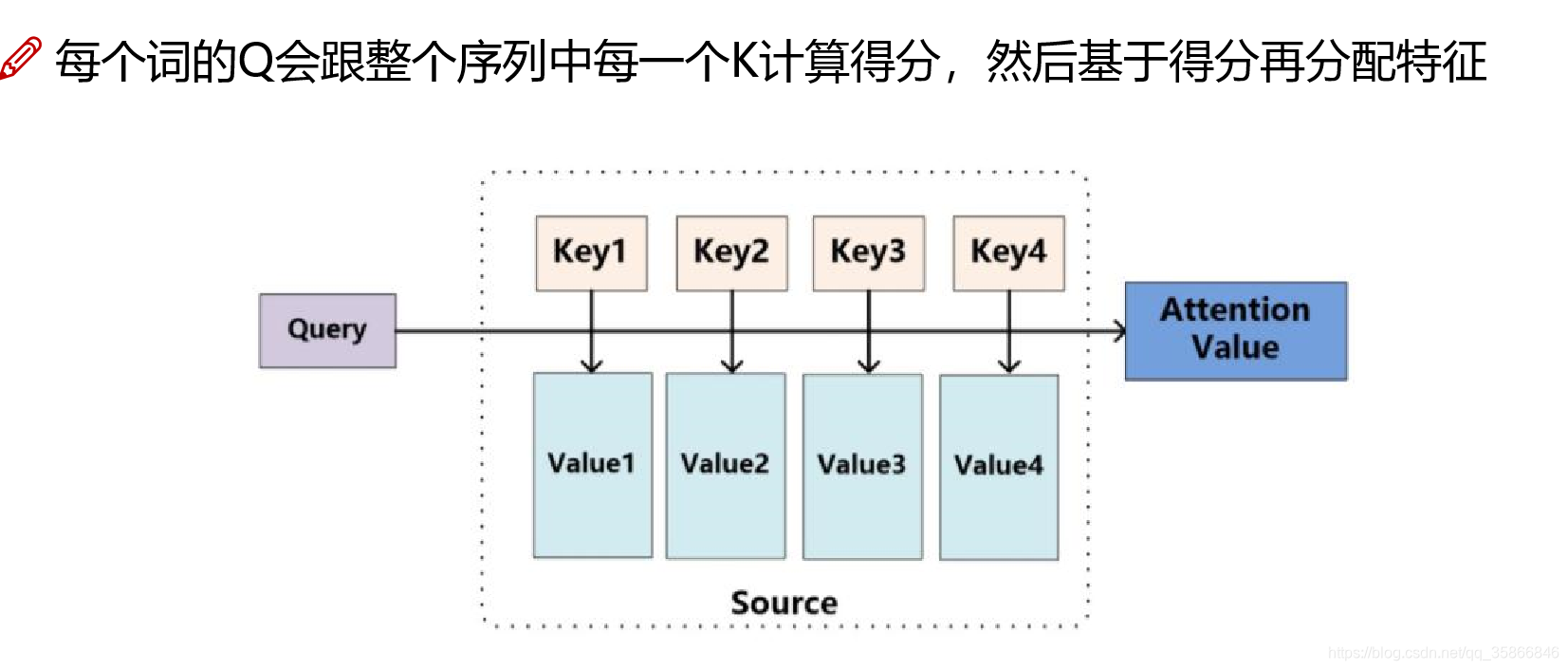
2.2、Self.attention是如何计算的
矩阵运算的方式,使得 Self Attention 的计算能够并行化,这也是 Self Attention 最终的实现方式

-
第 1 步:对输入编码器的每个词向量,都创建 3 个向量,分别是:Q向量(query 要去查询的),K向量(key等着被查的),V向量(Value实际的特征信息)。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数(先初始化,然后调整),最终需要整合的是V向量
-
第 2 步:计算 Attention Score(注意力分数)
通过计算 “Thinking” 对应的 Query 向量和其他位置的每个词的 Key 向量的点积(内积),而得到的。如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积(内积)
第m个词(共n个词)得到n个内积:
qmk1,qmk2,、、、qmkm,、、、qnkn
内积分乘法:对应位置元素相乘求和,内积越大,相关性越大
- 第 3 步:把每个分数除以 (√dkey) (dkey是 Key 向量的长度)
为了剔除向量维度影响,避免向量维度越大分数越高的不合理性
- 第 4 步:接着把这些分数经过一个 Softmax 层,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于 1
剔除度量值,比例化,方便对比
-
第 5 步:得到每个位置的分数后,将每个分数分别与每个 Value 向量相乘
-
第 6 步:把上一步得到的向量相加,就得到了 Self Attention 层在这个位置的输出。
每个词不再代表自己,代表的是全文加权后的特征
总结:
假设所有词向量组成矩阵
,权重矩阵
,
,
根据第1步,可得:
根据第2~6步,可得Self-Attention的输出
三、multi-head attention多头注意力机制
类似于卷积神经网络中的filter卷积核与特征图
multi-head:
- 通过不同的head得到多个特征表达(一般做8个头)
- 将所有特征拼接在一起
- 可以通过再一层全连接来降维
通俗地讲,不知道哪种方法好,多做几种方法,最后把几种方法的特征拼接在一起再降维
四、其他相关知识点
4.1堆叠多层:
- 经过self.attention&多头机制得到的输出还是向量
- 把得到的向量再重复做self.attention&多头机制继续输出向量
- 循环多层堆叠,计算方法一致,一般只做一层是不够的
4.2位置信息表达:
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识。
解决方法如下图:在embeddings后加一个位置编码
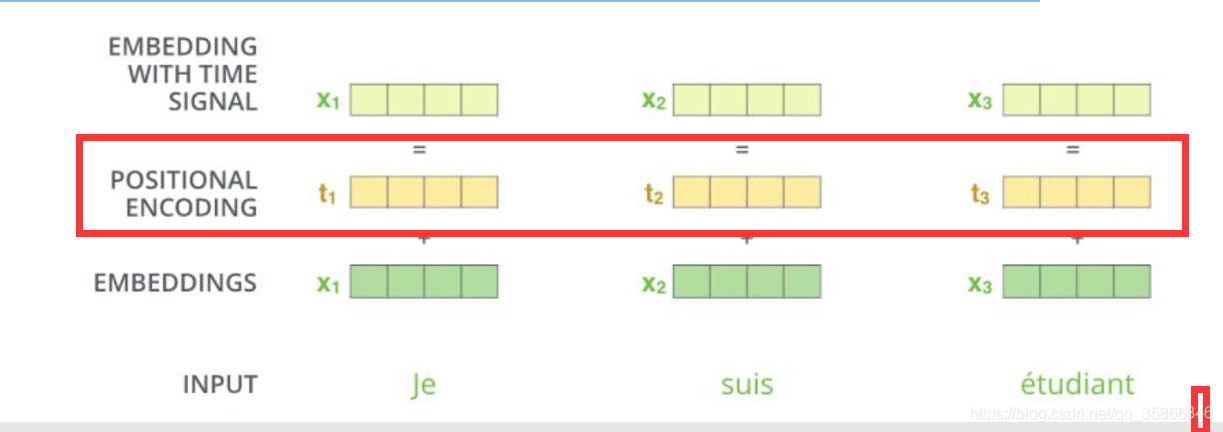
传统机器学习一般使用one-hot编码,transformer中使用余弦|正弦的周期性表达
4.3 残差连接
卷积神经网络中《深度残差网络》
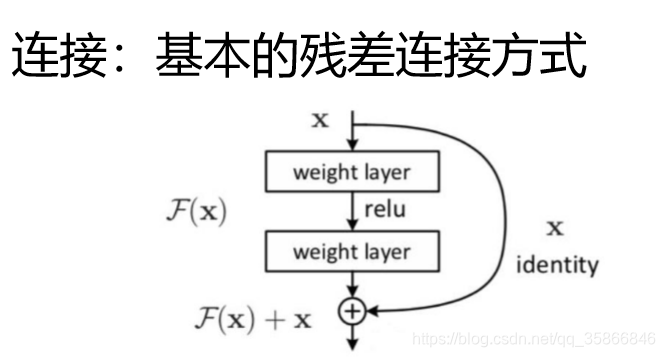
两条路:
- 经过self.attention 多头等特征变换
- 直接把原先特征拿过来
丢到网络中,让网络自己选择最优的特征
残差链接的结果:至少不比原来差
4.4 归一化
传统:batch的归一化
transform:layer层的归一化
五、代码实现
5.1使用PyTorch的MultiheadAttention来实现Attention的计算
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
参数说明:
- embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
- num_heads:设置多头注意力的数量。如果设置为 1,那么只使用一组注意力。如果设置为其他数值,那么 num_heads 的值需要能够被 embed_dim 整除
- dropout:这个 dropout 加在 attention score 后面
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
参数说明:
- query:对应于 Key 矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
- key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- key_padding_mask:如果提供了这个参数,那么计算 attention score 时,忽略 Key 矩阵中某些 padding 元素,不参与计算 attention。形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度。
-
- 如果 key_padding_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
-
- 如果 key_padding_mask 是 BoolTensor,那么 True 对应的位置会被忽略
- attn_mask:计算输出时,忽略某些位置。形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
-
- 如果 attn_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
-
- 如果 attn_mask 是 BoolTensor,那么 True 对应的位置会被忽略
import torch
import torch.nn as nn
## nn.MultiheadAttention 输入第0维为length
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(12,64,300)
# batch_size 为 64,有 10 个词,每个词的 Key 向量是 300 维
key = torch.rand(10,64,300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value= torch.rand(10,64,300)
embed_dim = 300
num_heads = 1
# 输出是 (attn_output, attn_output_weights)
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output = multihead_attn(query, key, value)[0]
# output: torch.Size([12, 64, 300])
# batch_size 为 64,有 12 个词,每个词的向量是 300 维
print(attn_output.shape)
torch.Size([12, 64, 300])
5.2使用自编程实现Attention的计算
import torch
from torch import nn
class MultiheadAttention(nn.Module):
def __init__(self, hid_dim, n_heads, dropout):
super(MultiheadAttention, self).__init__()
# 每个词输出的向量维度
self.hid_dim = hid_dim
# 多头注意力的数量
self.n_heads = n_heads
# 强制 hid_dim 必须整除 n_heads
assert hid_dim % n_heads == 0
# 定义 W_q 矩阵
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定义 W_k 矩阵
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定义 W_v 矩阵
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
# 缩放
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))
def forward(self, query, key, value, mask=None):
# K: [64,10,300], batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
# V: [64,10,300], batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# Q: [64,12,300], batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 这里把 K Q V 矩阵拆分为多组注意力,变成了一个 4 维的矩阵
# 最后一维就是是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度, 每个 head 的向量长度是:300/6=50
# 64 表示 batch size,6 表示有 6组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度
# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 -> [64,6,12,50]
# 转置是为了把注意力的数量 6 放到前面,把 10 和 50 放到后面,方便下面计算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# 第 1 步:Q 乘以 K的转置,除以scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention:[64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 把 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# 第 2 步:计算上一步结果的 softmax,再经过 dropout,得到 attention。
# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax
# attention: [64,6,12,10]
attention = self.do(torch.softmax(attention, dim=-1))
# 第三步,attention结果与V相乘,得到多头注意力的结果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# Z: [64,6,12,50]
Z = torch.matmul(attention, V)
# 因为 query 有 12 个词,所以把 12 放到前面,把 5 和 60 放到后面,方便下面拼接多组的结果
# Z: [64,6,12,50] 转置-> [64,12,6,50]
Z = Z.permute(0, 2, 1, 3).contiguous()
# 这里的矩阵转换就是:把多组注意力的结果拼接起来
# 最终结果就是 [64,12,300]
# Z: [64,12,6,50] -> [64,12,300]
Z = Z.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
Z = self.fc(Z)
return Z
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(64, 12, 300)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 300 维
key = torch.rand(64, 10, 300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
# output: torch.Size([64, 12, 300])
print(output.shape)
torch.Size([64, 12, 300])
六、篇章小测
问题1: Transformer中的softmax计算为什么需要除以dk?
为了剔除向量维度影响,避免向量维度越大分数叠加越高的不合理性
具体可参考:transformer中的attention为什么scaled?
问题2: Transformer中attention score计算时候如何mask掉padding位置?
在训练的过程中,自然语言数据往往都是以Batch的形式输入进的模型,而一个batch中的每一句话不能保证长度都是一样的,所以需要使用PADDING的方式将所有的句子都补全到最长的长度,比如拿0进行填充,但是我们知道这种用0填充的位置的信息是完全没有意义的,因此我们希望这个位置不参与后期的反向传播过程。以此避免最后影响模型自身的效果,因此提出了在训练时将补全的位置给Mask掉的做法。而在Self-attention的计算当中,我们自然也不希望有效词的注意力集中在这些没有意义的位置上,因此使用了PADDING MASK的方式.
PADDING MASK在attention的计算过程中处于softmax之前,通过PADDING MASK的操作,使得补全位置上的值成为一个非常大的负数(可以是负无穷),这样的话,经过Softmax层的时候,这些位置上的概率就是0。以此操作就相当于把补全位置的无用信息给遮蔽掉了(Mask掉了)
具体可参考:Transformer 中self-attention以及mask操作的原理以及代码解析
问题3: 为什么Transformer中加入了positional embedding?
位置和顺序对于一些任务十分重要,例如理解一个句子、一段视频。位置和顺序定义了句子的语法、视频的构成,它们是句子和视频语义的一部分。循环神经网络RNN本质上考虑到了句子中单词的顺序。因为RNN以顺序的方式逐字逐句地解析一个句子,这将把单词的顺序整合到RNN中。
Transformer使用MHSA(Multi-Head Self-Attention),从而避免使用了RNN的递归方法,加快了训练时间,同时,它可以捕获句子中的长依赖关系,能够应对更长的输入。
当句子中的每个单词同时经过Transformer的Encoder/Decoder堆栈时,模型本身对于每个单词没有任何位置/顺序感 (permutation invariance)。 因此,仍然需要一种方法来将单词的顺序信息融入到模型中。
为了使模型能够感知到输入的顺序,可以给每个单词添加有关其在句子中位置的信息,这样的信息就是位置编码(positional embedding, PE)
具体可参考:Transformer 中的 positional embedding
其他参考资料
attention主要的发展路径及目前的主流方法
唐宇迪老师-深度学习-PyTorch框架实战系列
面经:什么是Transformer位置编码?
深度学习attention机制中的Q,K,V分别是从哪来的?
插个题外话:
csdn的markdown写it类的文章还是比较方便的,但是我要微信公众号上再排版一遍还是比较麻烦的,今天发现一个特别的东西,可以一键转微信公众号排版,还是比较方便的,
微信公众号:诡途 欢迎关注
如何将Markdown文章轻松地搬运到微信公众号并完美地呈现代码内容
微信公众号 Markdown 编辑器 - OpenWrite
数学公式转图片生成网站

- 点赞
- 收藏
- 关注作者
评论(0)