【计算机二级Python】客观题(总结版)

【摘要】
二级备赛系列博文
【计算机二级Python】客观题(总结版)【计算机二级Python】主观题(总结版)【计算机二级Python】易忘知识点总结【计算机二级Python】阶段性总结版
一、数据结构的...
二级备赛系列博文
一、数据结构的相关知识点
- 算法
- 算法具有可行性、确定性、有穷性的基本特征;
- 算法是指解题方案的准确而完整的描述;
- 算法的有穷性是指算法必须能在执行有限个步骤之后终止
- 算法的复杂度主要包括时间复杂度和空间复杂度;
- 算法的时间复杂度是指执行算法所需要的计算工作量(执行过程中所需要的基本运算次数)
- 算法的空间复杂度是指执行这个算法所需要的内存空间
- 算法的基本要素包括数据对象的运算和操作及算法的控制结构
- 简单插入排序和选择排序法在最坏的情况下需要比较n(n-1)/2次
- 快速排序法比冒泡排序法的速度快
- 冒泡排序法是通过相邻数据元素的交换逐步将线性表变成有序
- 希尔排序法属于插入类排序法
- 算法是解题方案的准确而完整的描述
- 算法分析的目的是:分析算法的效率以求改进
-
二叉树
- 在深度为x的满二叉树中,叶子结点的个数为 2 x − 1 2^{x-1} 2x−1个
- 在深度为7的满二叉树中,结点个数总共是 2 7 − 1 {2^7-1} 27−1
- 设一颗完全二叉树共有699个结点,则该节点的叶子节点数是350(N+1/2)
- 二叉树包含度为0的结点、度为1的结点、度为2的结点(度为0的节点总是比度为2的结点多一个,度为1的节点=全部节点-度为1的-度为2的)
- 二叉树的前序遍历是指先访问根节点 -> 遍历左子树 -> 遍历右子树
- 二叉树的遍历可以分为三种:前序遍历、中序遍历、后序遍历
- 后序遍历二叉树的过程是一个递归的过程
- 二叉树的遍历是指不重复地访问二叉树中的所有结点
- 二叉树是一种非线性结构
- 二叉树具有两个特点:非空二叉树只有一个根结点;每一个结点最多有两棵子树,且分别称为该结点的左子树与右子树
-
数据结构
- 数据结构指相互有关联的数据元素的集合
- 在数据结构中,从逻辑上可以把数据结构分成线性结构和非线性结构
- 数据的逻辑结构反应数据之间的对应关系,与存储结构并不是一一对应的
- 用树形结构表示实体之间联系的模型是:层次模型
- 循环队列中元素的个数是由队头指针和队尾指针共同决定
- 数据的逻辑结构是反映数据元素之间逻辑关系的数据结构
- 对长度为n的线性表进行顺序查找,在最坏的情况下所需要的比较次数是n
- 只有一个根节点的数据结构不一定是线性结构
- 查找是指在一个给定的数据结构中查找某个特定的元素
- 二分查找只适用于顺序存储的有序表
- 如果采用链式存储结构的有序线性表,只能用顺序查找
- 线性数据结构:线性表、队列、栈!
- 二叉树不是线性数据结构
- 队列是先进先出的线性表,而栈是先进后出的线性表,两个的共同点是:只允许在端点处插入和删除数据
- 归并排序是要求内存量最大的
- 数据的逻辑结构是与所使用的计算机无关的
- 顺序存储结构是随机存取的存储结构
- 链式存储结构是顺序存取的存储结构
- 在单链表中,增加表头节点的目的是:方便运算的实现
- 已知数据表A中每个元素距其位置不远,为节省时间,宜采用的算法是:直接插入排序
- 用链表表示线性表的优点是:便于插入和删除操作
- 关系模型采用二维表来表示
- 表框架由N个命名的属性组成,每个属性有一个取值范围称为值域
- 二维表由表框架及表的元组组成
- 数据是现实世界符号的抽象,数据模型是数据特征的抽象
- 数据模型描述的内容有三个部分:数据结构、数据操作和数据约束
-
程序设计
- 结构化程序设计的原则是:逐步求精->自顶向下->模块化
- 与信息隐蔽的概念直接相关的概念是 - 模块独立性
- 为了使模块尽可能独立,模块的内聚程度要尽量高,且各模块间的耦合程度要尽量弱
- 数据独立性是数据与程序间的互不依赖性
- 数据流图(DFD)是结构化方法的需求分析工具
- 在黑盒测试中,测试用例的主要根据是-程序外部功能
- 结构化程序设计主要强调的是:程序的易读性
- 结构分析常用的是:判定树、数据字典、数据流图,没有PAD图
- 源代码的文档化包括:符号命名要有意义、正确的程序注释、良好的视觉组织
- 在结构化设计方法中,生成的结构图中,带有箭头的连线表示:模块之间的调用关系
- 在面向对象的程序设计中,各个对象之间相对独立,相互依赖性小
-
面向对象
- 继承是指类之间共享属性和操作的机制
- Python 3.x 解释器内部采用完全面向对象的方式实现
- 面向对象方法与人类习惯的思维方法一致
- 面向对象方法可重用性好
- 对象是属性和方法的封装体
- 对象间的通信靠消息传递
- 操作是对象的动态性属性
- 软件工程
- 软件工程是应用于计算机软件的定义、开发和维护的一整套方案、工具、文档和实践标准和工序
- 软件设计包括软件的结构、数据接口和过程设计
- 过程设计包括:系统结构部件转换成软件的过程描述
- 系统结构部件转换成软件的过程描述
- 软件是程序、数据与相关文档的集合
- 软件工程的主要思想是强调软件开发过程中需要应用工程化原则
- 软件工程设计工具:程序流程图、N-S、PAD、HIPO、判定表、PDL(伪码)
- 软件危机体现在三个方面:生产率低、质量难以控制、成本不断提高
- 软件测试的主要目的是发现程序中的错误
- 软件生命周期中开发阶段任务是:详细设计、软件测试、概要设计
- 软件调试的关键在于腿短程序内部的错误位置和原因
- 软件调试可以分为静态调试和动态调试
- 软件调试的主要方法有强行排错法、回溯法、原因排除法
- 软件交付使用后还需要进行维护
- 需求分析阶段的任务是:需求规格说明书评审、确定软件系统的功能需求、性能需求
- 在软件生命周期中,能准确地确定软件系统必须做什么和必须具备哪些功能的阶段是:需求设计
- 软件测试实施步骤中包括:单元测试、确认测试和集成测试
- 用于检测软件产品是否符合需求定义的是:确认测试
- 软件生命周期是指软件产品从提出、实现、使用维护到停止使用退役的过程
- 数据库
- 数据库技术的根本目标是要解决数据共享的问题
- 数据库系统的核心是:数据库管理系统
- 在数据库设计中,用E-R图来描述信息结构但不涉及信息在计算机中的表示的阶段是:概念设计阶段
- 数据库设计的四个阶段按顺序为:概念设计、需求分析、逻辑设计、物理设计
- 概念设计过程:由底向上、自顶向下、由内向外
- 数据库设计可以采用生命周期法
- 数据库设计是数据库应用的核心
- 数据库设计的基本任务是根据用户对象的信息需求、处理需求和数据库的支持环境设计出数据模式
- 当对关系R和S进行自然连接时,要求R和S含有一个或者多个共有的:属性
- 能够给出数据库物理存储结构与物理存取方法的是:内模式
- 在数据库中,索引属于:内模式
- 数据库设计中,反应用户对数据要求的模式是:外模式
- 描述单个用户使用的数据视图是:外模式
- 数据库系统减少了数据冗余
- 数据库设计内容的两个方面包括:概念设计和逻辑设计
- 关系数据库管理系统能实现的专门关系运算是:选择、投影、连接
- 设关系R是4元关系,关系S是一个5元关系,关系T是R与S的笛卡儿积,即T=R×S,则T是9元关系
- 数据库处理的最小单位是:数据项
- 数据库是一个结构化的数据集合
- 文件系统和数据库系统主要区别的:数据库系统具有特定的数据模型
- 数据库描述内容:数据操作、数据结构、数据约束
- 层次型、网状型和关系型数据库划分的原则是:数据之间的联系方式
- 在一个关系中,如果存在多个属性(或属性组)都能用来唯一标识该关系的元组,且其任何子集都不具有这一特性。该关系的这些属性(或属性组)被定义为候选码
- 某个数据约束规则为:设属性A是关系R的主属性,则属性A不能取空值。则该数据约束规则的名称是:实体完整性规则
- 将E-R图转换为关系模式时,可以表示实体与联系的是关系
- 在E-Rt图中,用来表示联系的图形是:菱形
- 属于概念数据模型的是:关系
- 数据模型按不同应用层次分为三种类型:概念数据模型、逻辑数据模型和物理数据模型
- DML是数据操纵语言
- DDL是数据定义语言
- DCL是数据控制语言
- 对数据库进行规划、设计、维护、监视等管理工作的人员称为数据库管理员
- 数据库管理员对多个应用的数据需求作全面规划、设计与集成
- 数据库管理员需要完成数据库维护,完成对数据库中数据的安全性、完整性、并发性控制及系统恢复、数据定期转存等工作
- 其他
-
关系表中的每一横行成为元组
-
PFD图中用箭头表示控制流
-
二、python相关
-
编程语言基础
- 静态语言采用编译方式执行,脚本语言采用解释方式执行;
- 编译是将源代码转换成目标代码的过程;
- 解释是将源代码逐条转换成目标代码同时逐条运行目标代码的过程;
- C语言是静态语言,Python语言是脚本语言
- python语言特点:黏性扩展、平台无关、强制可读
- python变量的命名特点:随时命名、随时赋值、随时使用
- 三种基本数字类型:整数类型、浮点数类型、复数类型
- 程序设计的基本结构:顺序、分支、循环
- 注意变量的命名不能以数字开头;变量名中不允许出现特殊符号例如*!等
- python发生异常后经过适当的处理可以继续运行而不崩溃;
- 异常语句可以与 else 和 finally 保留字配合使用
- 局部变量为组合数据类型且未创建,等同于全局变量
- 局部变量和全局变量是不同的变量,但可以使用global保留字在函数内部使用全局变量
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 假设函数中不包括global保留字,对于改变参数值的方法:参数是list类型时,改变原参数的值;参数是int类型时,不改变原参数的值;参数是组合类型(可变对象)时,改变原参数的值
-
程序设计基础
- max是python的内置函数,所以应该这样用
print(max(listV)),而这样用是错的print(listV.max()) - 执行 eval(“Hello”) 和执行 eval(" ‘Hello’ ") 得到不相同的结果,前者是错误的
fo.write(",".join(ls)+ "\n")数据之间用逗号分隔开,最后加一个换行- 浮点数0.0和证书0具有相同的值,硬件执行单元,计算机指令处理方法和数据类型均不同
- 关于random.uniform(a,b)的作用:生成一个[a, b]之间的随机小数
- range(1,4):是1~3
sorted(a,reverse = True)降序排列
- max是python的内置函数,所以应该这样用
-
python小知识
- 复数的虚数部分通过后缀“J”或者“j”来表示
- 组合数据类型可以分为 3 类:序列类型、集合类型和映射类型
- python的索引下标从0开始
- 列表的切片[nⓂ️k] 从n到m,步长为k
- Python 语言要求所有浮点数必须带有小数部分
- x**y表示x的y次幂,其中,y也可以是整数
- x // y x与y之整数商,即:不大于x与y之商的最大整数
- python的字符编码均采用Unicode编码
- chr(x) 和 ord(x) 函数用于在单字符和 Unicode 编码值之间进行转换
- 字符串比较规则:从第一个字符开始,一一比较编码大小,当一个字符串全部字符和另一个字符串前部分字符相同时,长度长的字符串为大
- 关于函数的可变参数,可变参数*args传入函数时存储的类型是tuple
- f = lambda x,y:x+y 执行后,f的类型为function
-
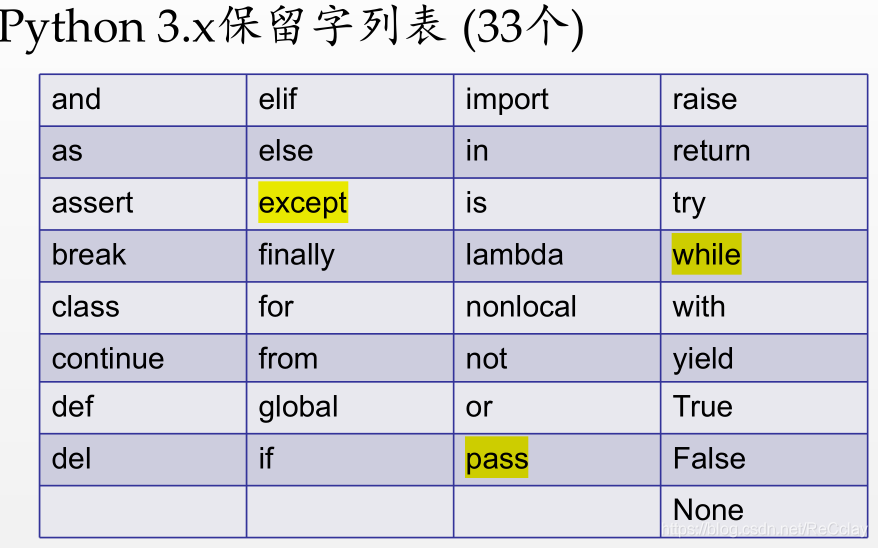
保留字(后面附有所有的保留字表)
- python的33个保留字
- do不是python的保留字
- Python 使用 def 保留字定义一个函数
-
序列类型
- 序列类型是一维元素向量,元素之间存在先后关系,通过序号访问
- str、tuple 和 list 类型都属于序列类型
- 列表类型用以表示一维和二维数据
-
字典
- 字典是集合类型的延续,各个元素并没有顺序之分
- 字典是可以存储可变数量键值对的数据结构,键和值可以是任意数据类型
- 字典的主要用法是通过索引符号来实现查找与特定键对应的值
- 若想保持一个集合中元素的顺序,需要使用列表,而不是元组
- 字典要求键值对中的键是不可改变变量类型,所以
d = {[1,2]:1, [3,4]:3}不能建立字典 - d.get(key, default)根据键信息查找并返回值信息,如果key存在则返回相应值,否则返回default
- 与其他组合类型一样,字典可以遍历循环对其元素进行遍历
for < 变量名> in < 字典名>的语法格式;其中for循环返回的变量名是字典的索引值。如果需要获得键对应的值,可以在语句块中通过get()方法获得:
for k in d:
print(" 字典的键和值分别是:{} 和{}".format(k, d.get(k)))
- 1
- 2
-
文件
-
考题概览
- 当文件以文本文件方式打开时,读写按照字符串方式,采用当前计算机使用的编码或指定编码;
- 当文件以二进制文件方式打开时,读写按照字节流方式
- writetext函数不是 Python 对文件的写操作方法.
- 高维数据有键值对类型的数据构成,采用对象方式组织;
- 二维数据采用表格方式组织,对应于数学中的矩阵;
- 一维数据采用线性方式组织,对应于数学中的数组和集合等概念
- 文本文件可以看成是由行组成的组合类型,因此,可以使用遍历循环逐行遍历文件
- 如果一个文本文件从网络中获得,增加encoding参数,指定编码方式打开;如果python程序生成了一个文件,并再次打开,则不需要指定encoding参数。
-
操作相关
- 创建写模式’x’
- 覆盖写模式w
- 只读模式r
- 追加写模式a
f.read()是最常用的一次性读入文件的函数,其结果是一个字符串;f.readlines()也是一次性读入文件的函数,其结果是一个列表f.write(s)向文件写入一个字符串或字节流(要显式的使用’\n’对写入文本进行分
行)f.writelines(lines)将一个元素为字符串的列表写入文件f.seek(offset)改变当前文件操作指针的位置 0-开头 2-结尾
-
-
CSV文件
- CSV文件采用纯文本格式,通过单一编码表示字符
- 以行为单位,开头不留空行
- 每行表示一个一维数据,多行表示多维数据
- 以逗号分隔每列数据,列数据为空也要保留逗号
- 整个CSV文件是一个二维数据
- CSV文件格式是一种通用的文件格式,应用于程序之间转移表格数据
- CSV文件的每一行是一维数据,可以使用Python中的列表类型表示
-
time标准库
time.strftime()函数是时间格式化最有效的方法,几乎可以以任何通用格式输出时间。该方法利用一个格式字符串,对时间格式进行表达time.perf_counter()返回一个CPU级别的精确时间计数值,单位是秒。由于这个计数值起点不确定,连续调用才有意义- time.sleep(5) 推迟调用线程的运行,单位为秒
-
第三方库
-
考题概览
- 数据分析的相关第三方库:numpy;scipy;pandas
- python用于界面开发的第三方库有:pygtk、pyqt、wxpython
- 数据分析的第三方库有:numpy、pandas
- 数据可视化方向的第三方库有:mayavi2
- 适用于web开发的第三方库有:pyramid、flask、Django
- 网络爬虫的第三方库有:scrapy
-
jieba
- 三种模式:精确模式、全模式、搜索引擎模式
jieba.cut(s)是精确模式,返回一个可迭代的数据类型;jieba.lcut(s)是精确模式,返回列表类型;没有冗余度;jieba.lcut(s, cut_all = True)用于全模式,返回的是列表;冗余度最大jieba.lcut_for_search(s)用于搜索引擎模式(首先执行精确模式,然后再对其中长词继续切分),返回的是列表;倾向于寻找短词语;具有一定的冗余度,但是比全模式冗余度小jieba.add_word()函数,用来向jieba词库增加新的单词
-
文章来源: recclay.blog.csdn.net,作者:ReCclay,版权归原作者所有,如需转载,请联系作者。
原文链接:recclay.blog.csdn.net/article/details/88360163

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)