【ESWIN实习】第一次培训笔记(宁宇leader主讲)

培训主题:要做什么?能做什么?需要做什么?
成熟的AI软件团队
- 开发了从底层驱动,AI算子库,并行计算框架,AI框架的完整工具链
- 对接了Tensorflow等通用框架,用户程序可以零修改运行到自主AI芯片上
- 开发了自主轻量级推理框架,实现模型转换,图优化,高效运行推理模型
- 开发了AI性能分析,量化等工具
- 开发了基于LLVM/GCC 的并行计算编译器,OpenCL 编译器
ESWIN 是一个芯片公司,成都site主要是软件团队!
一个芯片能不能卖,卖的如何,决定性因素除了硬件还有软件!
- 软件做到什么程度,用户用的顺手与否?
- 它的工具是否丰富?
- 对生态支持完不完善?
以上因素综合决定了它在后期市场上的表现!
软件团队主要是配合硬件在市场上与客户对接!
涉及面广,深度比较深,从下往上:指令集、架构都是自己开发的。
从编译、驱动、框架、模型算法、应用(对接通用的训练框架、AI框架)
底层的话用的是 RISC-V 的指令集,一个趋势。指令集演变趋势:x86 -> ARM -> RISC-V
RSIC-V除了通用的指令集,针对AI加速(PINT平台)制定了自己的指令。
自组指令的支持,编程上性能优化。涉及东西比较多。
底层基于Linux平台开发,涉及到内核态、用户态的驱动。
驱动作用,让硬件怎么样可以用软件的方式去驱动!
并行计算:
- NVIDIA 通过 CUDA 对接 GPU
- ESWIN 通过 OpenCL 对接 PINT
EAS0020软件栈
- 通过第一代产品迭代,已形成较为完整AI软件栈
- 可以与已有通用框架无缝对接
- 无缝对接Tensorflow
- 用户程序零改动运行
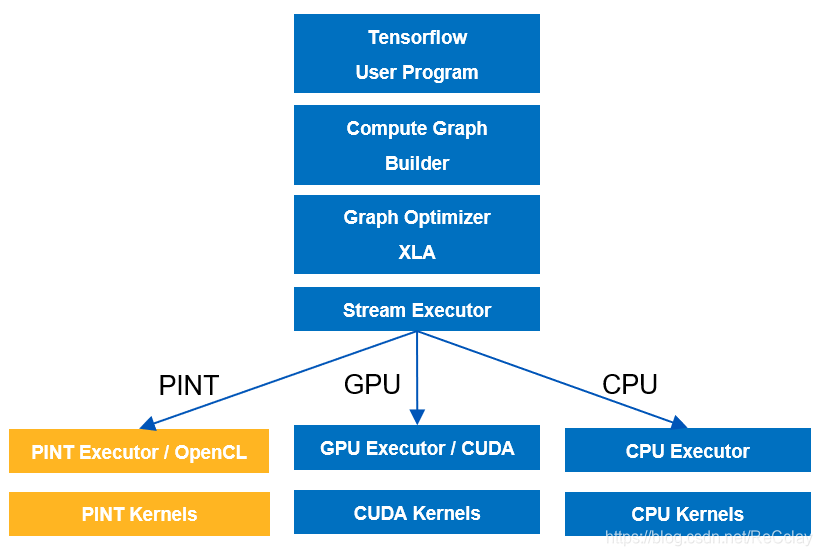
对 Tensorflow 的后端进行支持,Tensorflow 默认是基于CUDA,PINT 即把基于CUDA的后端直接port到基于PINT的后端。
利用其存储生态,训练推理框架可以直接对接到我们的产品上!
NVIDIA 是利用CUDA这样一个库,来后面对接实现自己的算子,在他们厂的硬件上进行运算和加速!
PINT 是利用OpenCL这样一个库,针对各个算子,针对自己的硬件平台进行功能实现和性能优化!
曾颖超主要做算子的优化这方面的!
优化的跟平台和硬件设计特别相关,

从客户来讲,基于成熟的硬件训练平台,如TensorFlow等,结合自己的业务会生成自己的算法或模型。不会愿意花费太多的精力在另一个平台上学东西。因此PINT 框架支持了模型转换、性能调优。
用户可以拿他们的模型在PINT上方便的部署,并且对性能进行一定的调优。
驱动框架是下面的驱动和通用平台之间的适配层。目前主要是OpenCL,但是也提供了类似CUDA的Driver API的PINT API。
进来的同学:应用、算子、RTL(仿真)【不太偏底层】
RTL说白了,可能就是利用API或OpenCL加速一些相应的计算,应用领域不一样,实现方式略有不同!
为了支持这种生态,进行了接口上的适配和功能上的实现。
软件栈

编程模型
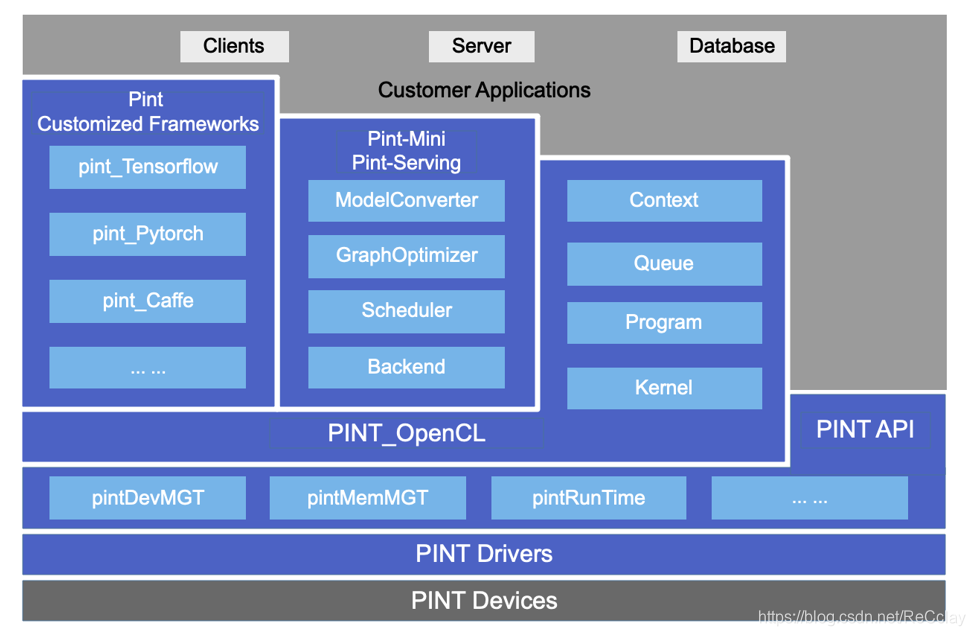
APU成都软件团队介绍
mcore + ncore = APU
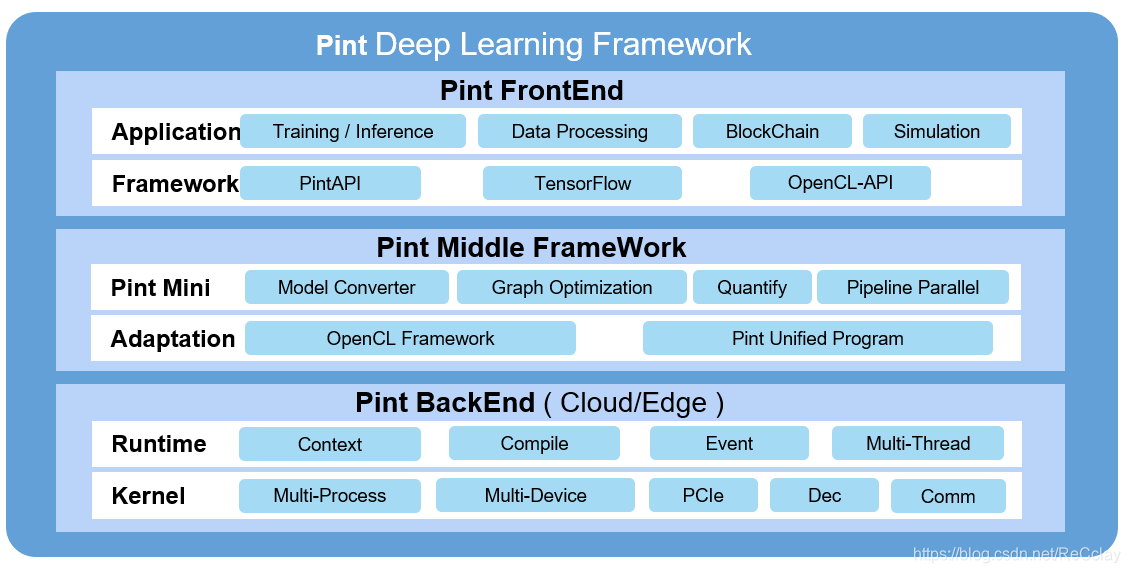
指令架构
- RISC-V、Spc/Customer、GCC/LLVM
系统集成
- Driver PCIe/Decoder/UAP、Framework OpenCL/PintUP
运行框架
- Training TensorFlow、Inference PintMini
算子算法
- Multiple Scenario、Detect/Identify/Track/…
应用工具
- Debug/Performance/Demo
自动化测试
- CI/CD Jenkins
协同验证
- Simulation/FPGA/ASIC
项目管理
- Confluence(会议、文档)/Jira(任务)/Bitbucket(代码)
- OA(事务的处理:请假出差、财务上的流程)
成都软件团队
- 系统驱动【编译、内核态用户态实现】
- 系统应用【API、Demo、用户对接比较多】
- 框架【对主流AI框架移植,自有的高效推理框架实现小组】
- 算子【针对硬件平台进行功能实现、性能加速的小组】
- 算法【针对项目的模型的调试,现有及以后算法趋势的研究,对产品的架构和设计提供参考】
- 测试
硬件介绍
并行加速的芯片,可以同时运算的计算单元。主要概念就是core,基于RSIC-V指令,是标量计算。
AI里面运算量比较大的,如矩阵运算等,PINT也有一些硬件加速,如Systolic Array。
PINT core 类比 NVIDIA 的 CUDA Core
Systolic Array 类比 NVIDIA 的 Tensor Core
core也是分区域的,8个core是一组PE,PE 类比 NVIDIA 的 SM
Systolic Array对卷积和矩阵运算效率比较高!在CV领域,对特定计算进行加速,对性能提示!
各个core连接到Interconnection Network进行处理,进行并行计算的时候,各个core都可以对自己需要的一些数据进行处理,处理完之后,在框架上得到想要的结果。
对外的接口,产品有两种形态,一种加速卡,一个叫边缘盒子,对外接口的话通过PCIE对host端进行交互!
芯片架构介绍

做算子对具体的硬件设计要求比较高,特别在计算里面对性能提升多的,比如存储的访问,对计算加速的特殊指令使用。

core的计算,它的性能,数据流怎么走?
core对资源的访问,分了几级的存储,比如说对它自己来讲有Dcache,其他 core 不能访问它的Dcache。故Dcache对该core来讲是访问最快的!
对于所有core 来讲,有shared-cache,全局的。
在shared-cache以下有一个DDR。
很多算子要提升性能,就是在这里考虑很多事情,比如访问的存储资源的空间的分配,怎么比较优!
优即该资源在对应的Dcache里就能拿到,没必要去其他地方去取。有点类似Local Memory。
性能分析和调优,即访
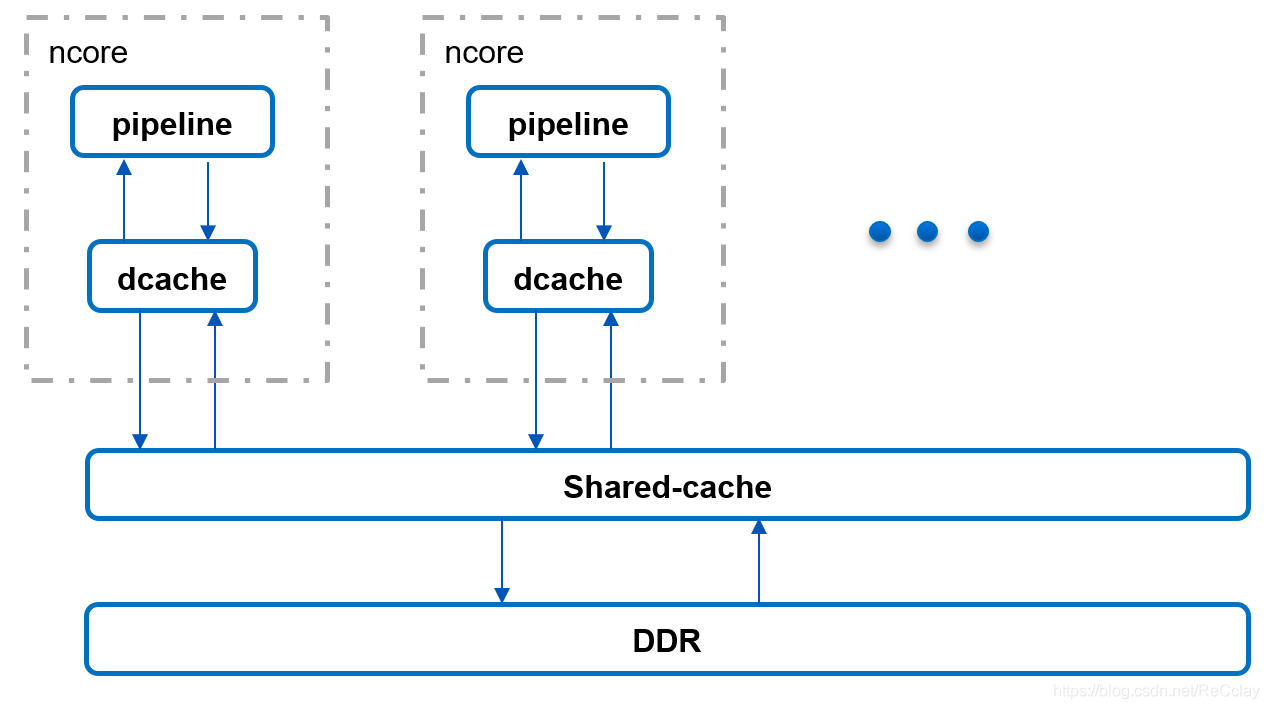
异构并行加速器的框架
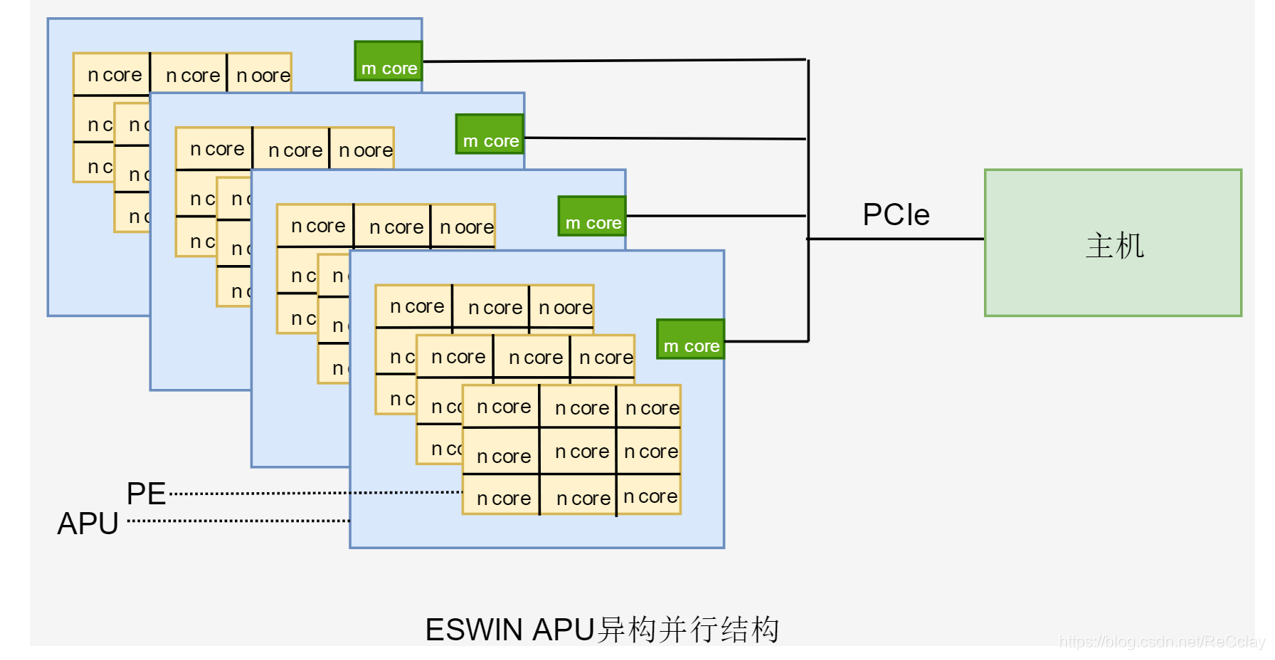
ncore:实现并行的能力
mcore:相当于对并行core的汇总的一个关系
不退出设备的前提实现多个并行处理!NVIDIA的CUDA不能这样!
Pint OpenCL简介
- OpenCL针对并行计算的通用框架,接口的规范工作。
- 异构并行计算机能加速计算任务的完成,异构框架下的加速器衍生出了多种类型,如GPU、FPGA、APU、TPU等,每种类型的加速器也会有不同厂家产品,如AMD、NVIDIA、Intel等,各厂商通常仅仅提供对于自己设备编程的实现,这样对上层应用的规范和迁移带来困难。
- OpenCL(Open Computing Language),旨在满足上述需求, 它是一个通用的由很多公司和组织共同发起的多CPU\GPU\其他芯片异构计算(heterogeneous)的标准,它是跨平台的。
- OpenCL( 官网链接)的标准定义和学习资料在官网和互联网上都非常容易获取,不多做赘述。
- OpenCL编程模型的系统框图如下边:
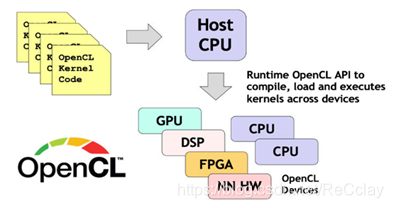
相当于针对并行计算的通用框架,进行接口的规范。
利用OpenCL框架做,也是考虑到生态,我们的东西与其他第三方的进行对接,采用相应的标准,对后续的拓展和兼容是比较好的,可以省下后续的成本。
框架和应用也是通过OpenCL的方式把它封装起来!
算子在设备端运行,主要用的RSIC-V编译器,将我们的算子通过OpenCL的语法,将其编译成我们设备端能运行的形式。
基本上软件实现的从上到下的一个框架
设备代码编译与运行
- 使用OpenCL Kernel Wrapper/C++编程方式
- 实现kernel函数(可使用完整C++语法),记为cpp_kernel
- cpp_kernel包装成标准C语言可以调用的函数,记为clinkage_kernel
- 使用riscv-gcc编译器,将clinkage_kernel编译为静态库(.a文件)
- 将clinkage_kernel包装成opencl C语法的kernel函数,记为ocl_kernel
- 编写CPU端opencl程序。使用build from source的方式,将ocl_kernel源码文件送入opencl与生成的静态库一起进行编译。之后创建kernel,运行kernel。
问题提问
- 结合自己要从事方向
- 并行计算的芯片公司,做出来的东西可能要给客户用,怎么样能把自己做的事融入到项目里面来。
- 要做些什么?要做的是哪些?要做到哪些程度?免得自己不清楚在软件里面的定位!
- 疑问、疑惑对工作有哪些改善的?
- 对任务的要求急不急啊?
- 怎么分配任务?
- 平时怎么汇报任务?汇报方式?
- 例会是结合每个小组。
- 开会是以什么样的方式的组织?
- 进来之后有个仪式感?
- 遇到问题找哪些人?上下游做什么的?你做的工作是哪一部分?
- 性能调优是根据什么调优的?
- 细一点:counter等…,在计算过程中,在访问资源的过程中有没有达到很好的利用。
- 大一点:结合模型,借助性能分析工具,通过打点的方式,知道它在设备上的占用情况是不是已经让设备一直不停的再动。
- 高一点:整个业务上,多个模型,多个进程等等,把任务分配合理,设备利用起来等!
- 老员工也在学
- CV、仿真加速、区块链、大数据分析
- 多交流
类似寒武纪这样的AI公司,纯做推理,讲究功耗性能比,单位功耗里面输出多少算力。在硬件上考虑很多东西,他们一个比较常用的方法就是算法硬件化。(用ASIC方式实现)
- 优点:功耗很低,面积很小,速度很快!
- 弊端:模型支持有限制
ESWIN与这些纯做推理AI公司主要区别:
- 定位不同,导致了实现细节不同,进而在软件层面工作的差异,ESWIN主要做通用型的硬件加速,通用型指很多实现是靠软件来实现的!比如:算子实现、任务调度等都是通过可编程的方式实现,对于软件来讲,灵活度比较大,挑战性比较高,优化能力都会有一个很高的要求!
对于ASIC,主要把网络的流程打成一个流,以状态机的方式流动。
两者实现场景有些不一样!
ESWIN人不多,但同时做很多东西!实现的方式决定了很多东西需要自己去做。
文章来源: recclay.blog.csdn.net,作者:ReCclay,版权归原作者所有,如需转载,请联系作者。
原文链接:recclay.blog.csdn.net/article/details/114292586

- 点赞
- 收藏
- 关注作者
评论(0)